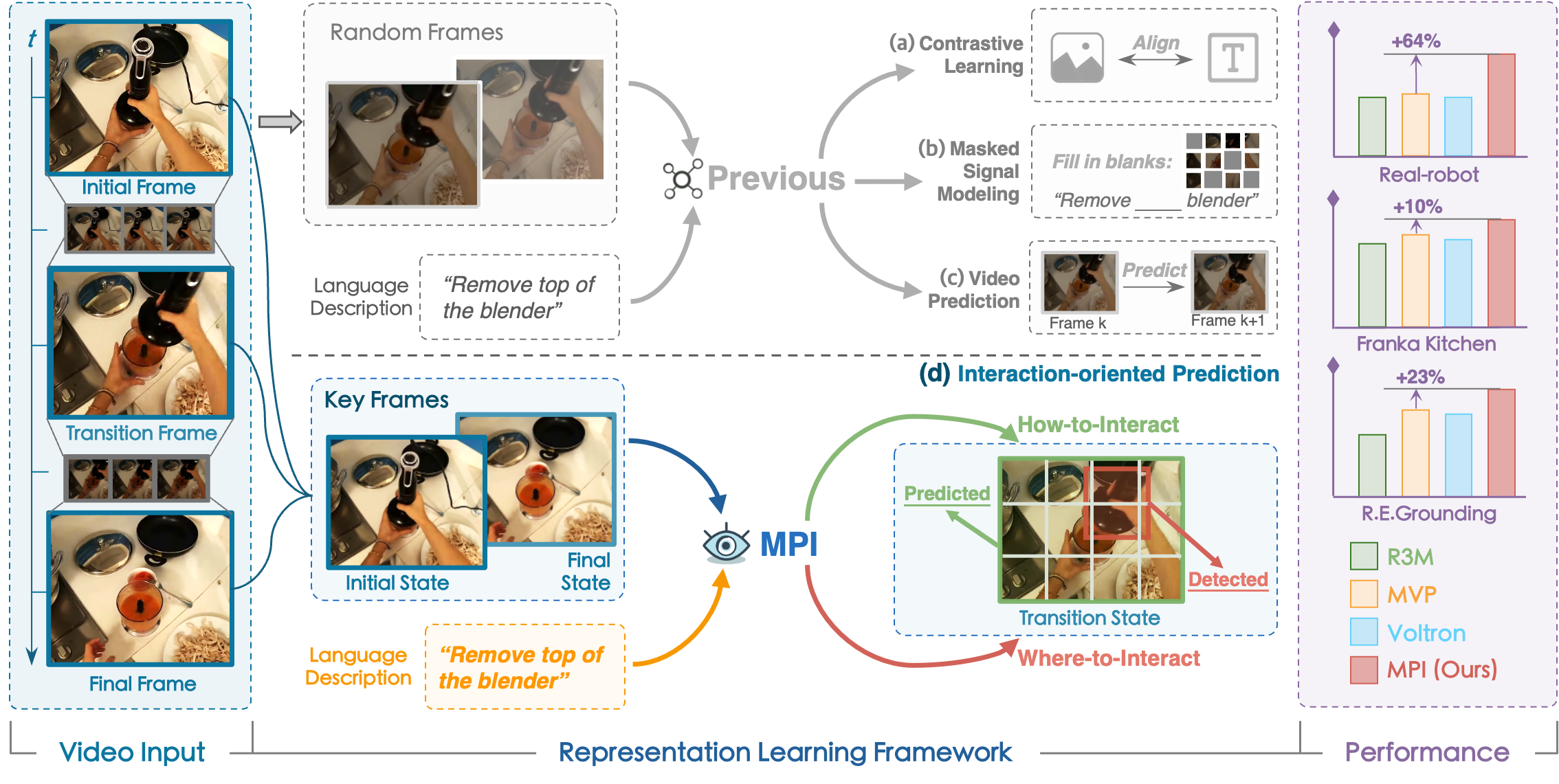
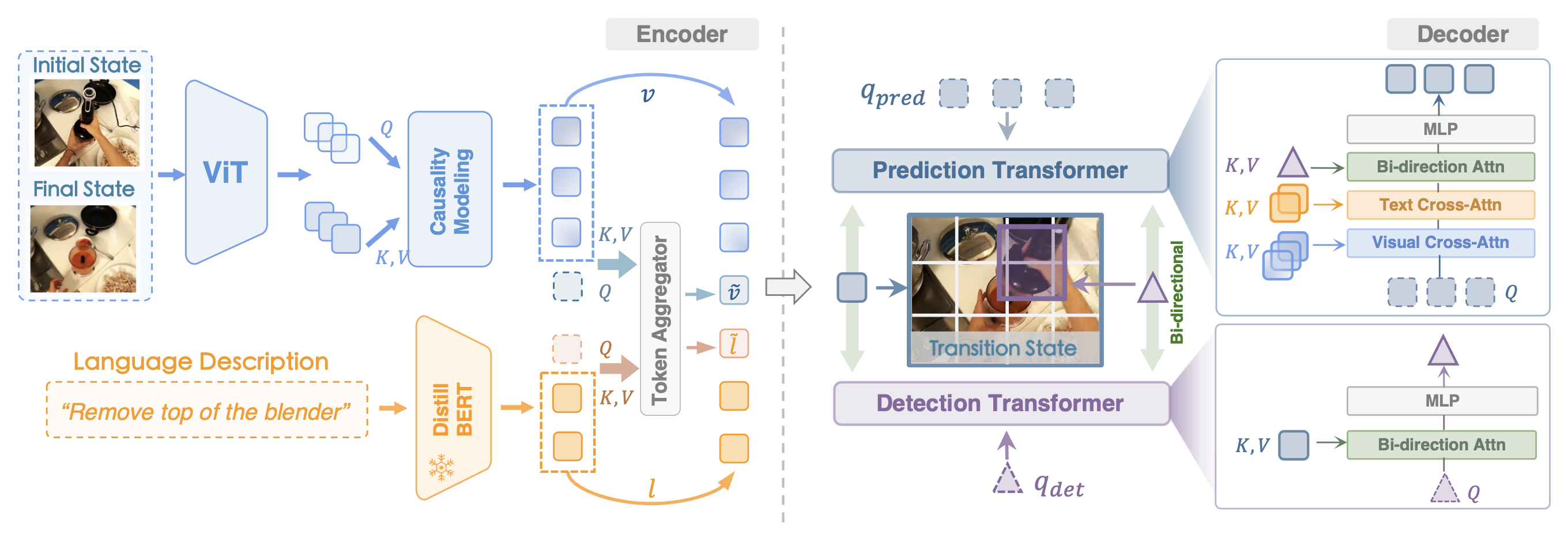
MPI comprises a multi-modal transformer encoder and a transformer decoder designed for predicting the image of the target interaction state and detecting interaction objects respectively. We achieve synergistic modeling and optimization of the two tasks through information transition between the prediction and detection transformers. The decoder is solely engaged during the pre-training phase while deprecated for downstream adaptations.
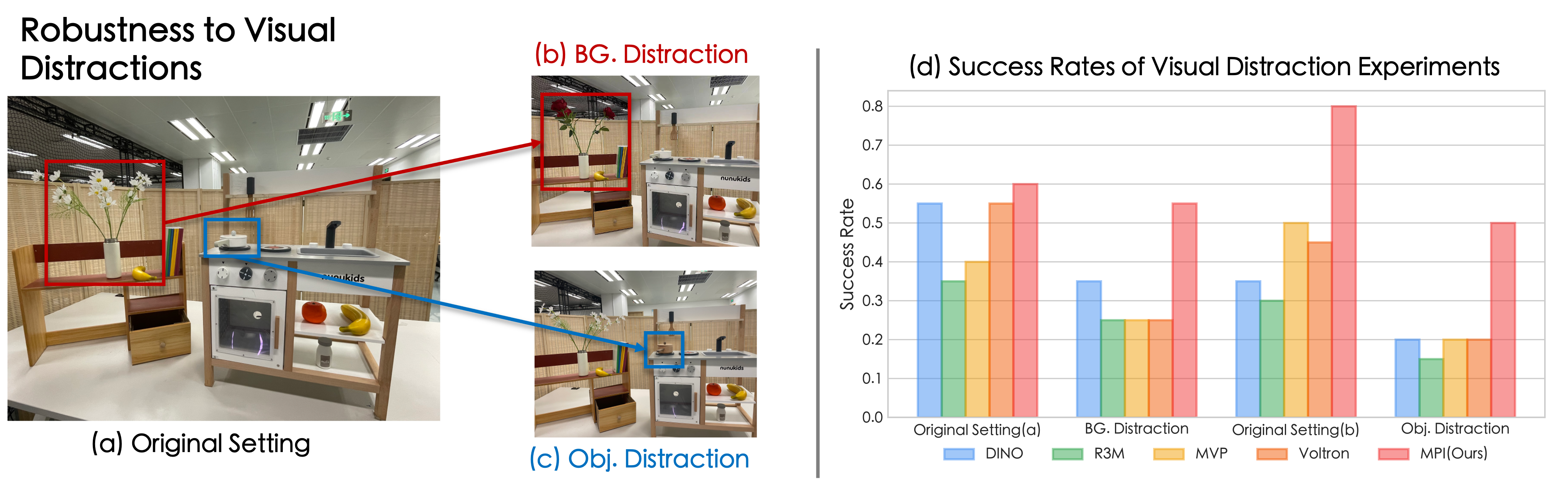
To provide a comprehensive evaluation of the effectiveness of different pre-trained encoders, we design two distinct scenarios with varying levels of complexity. The first scenario consists of ten diverse manipulation tasks in a clean background. These tasks require fundamental manipulation skills such as Pick & Place, articulated object manipulation, etc. In addition, we construct a more challenging kitchen environment that incorporates various interfering objects and backgrounds relevant to the target tasks. In this environment, we present five tasks: 1) taking the spatula off the shelf, 2) putting the pot into the sink, 3) putting the banana into the drawer, 4) lifting the lid, and 5) closing the drawer. As shown in Fig. 3(a), the complexity of these scenarios necessitates the visual encoder to possess both the “how-to-interact” and “where-to-interact” abilities to effectively handle these tasks.
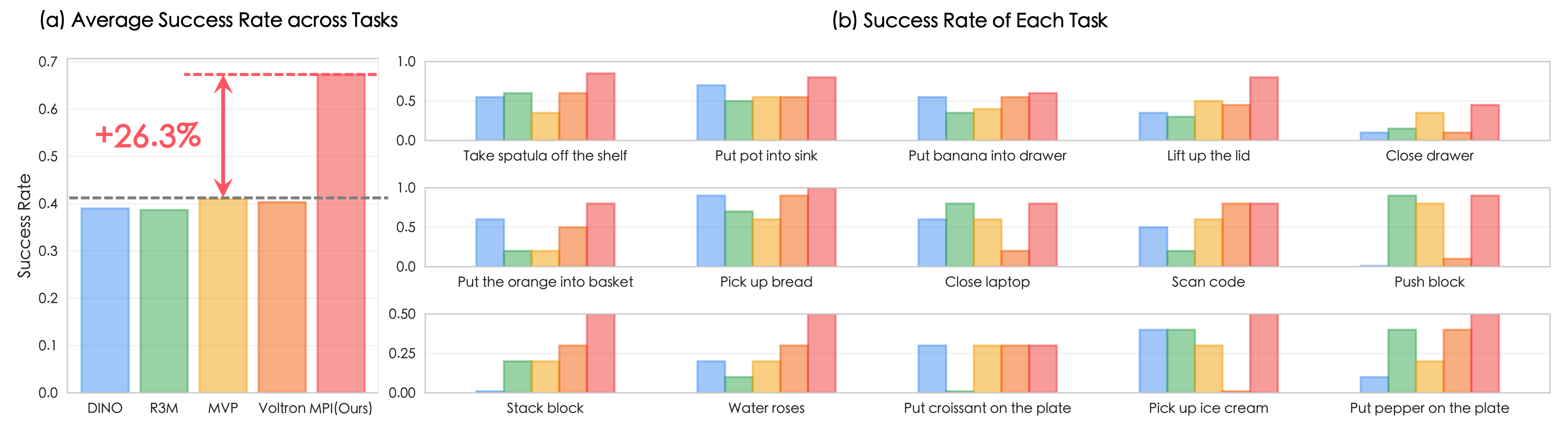
To genuinely reflect various encoder architectures’ capabilities in data-efficient robotic learning within real-world environments, we developed a series of complex manipulation tasks both in kitchen environment(5 tasks) and in clean background(10 tasks). The complex scenarios need the visual encoder to have not only "how to interact" but also "where to interact" ability to handle these tasks. Here are some examples.
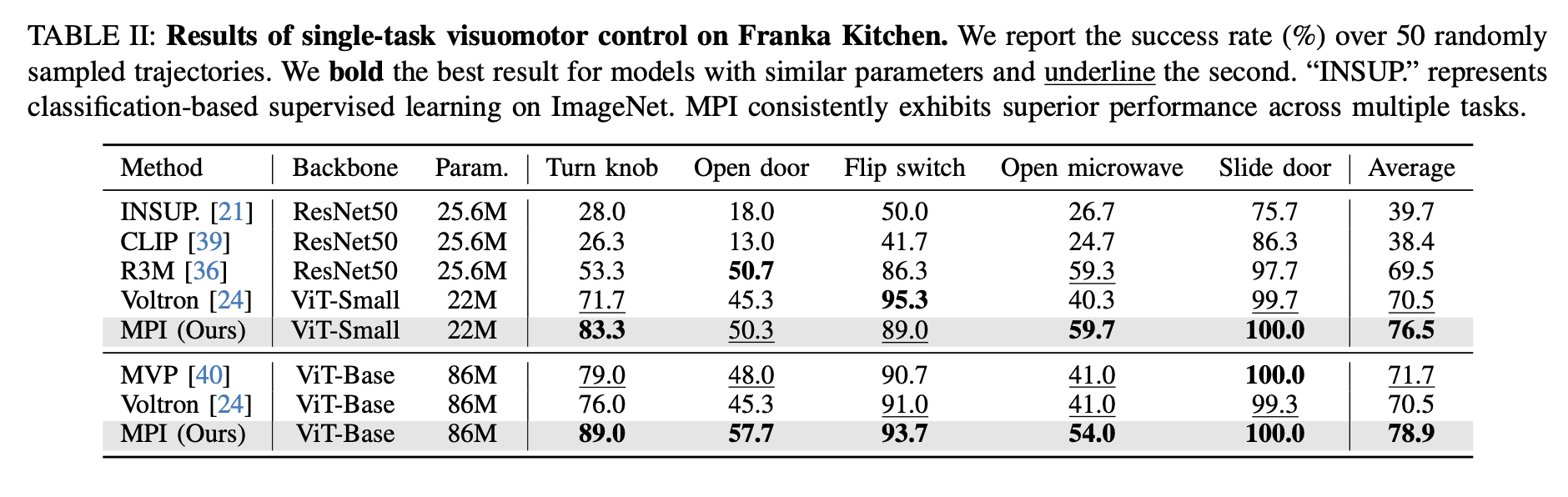
Previous studies have established imitation learning for visuomotor control in simulation as the standard evaluation method. This enables direct comparisons with prior works and focuses on assessing the sample-efficient generalization of visual representations and their impact on learning policies from limited demonstrations. We conduct this evaluation to compare the capabilities of different representations in acquiring both the knowledge of “where-to-interact” and “how-to-interact” in complex simulation environments.

@inproceedings{zeng2024mpi,
title={Learning Manipulation by Predicting Interaction},
author={Jia, Zeng and Qingwen, Bu and Bangjun, Wang and Wenke, Xia and Li, Chen and Hao, Dong and Haoming, Song and Dong, Wang and Di, Hu and Ping, Luo and Heming, Cui and Bin, Zhao and Xuelong, Li and Yu, Qiao and Hongyang, Li},
booktitle= {Proceedings of Robotics: Science and Systems (RSS)},
year={2024}
}