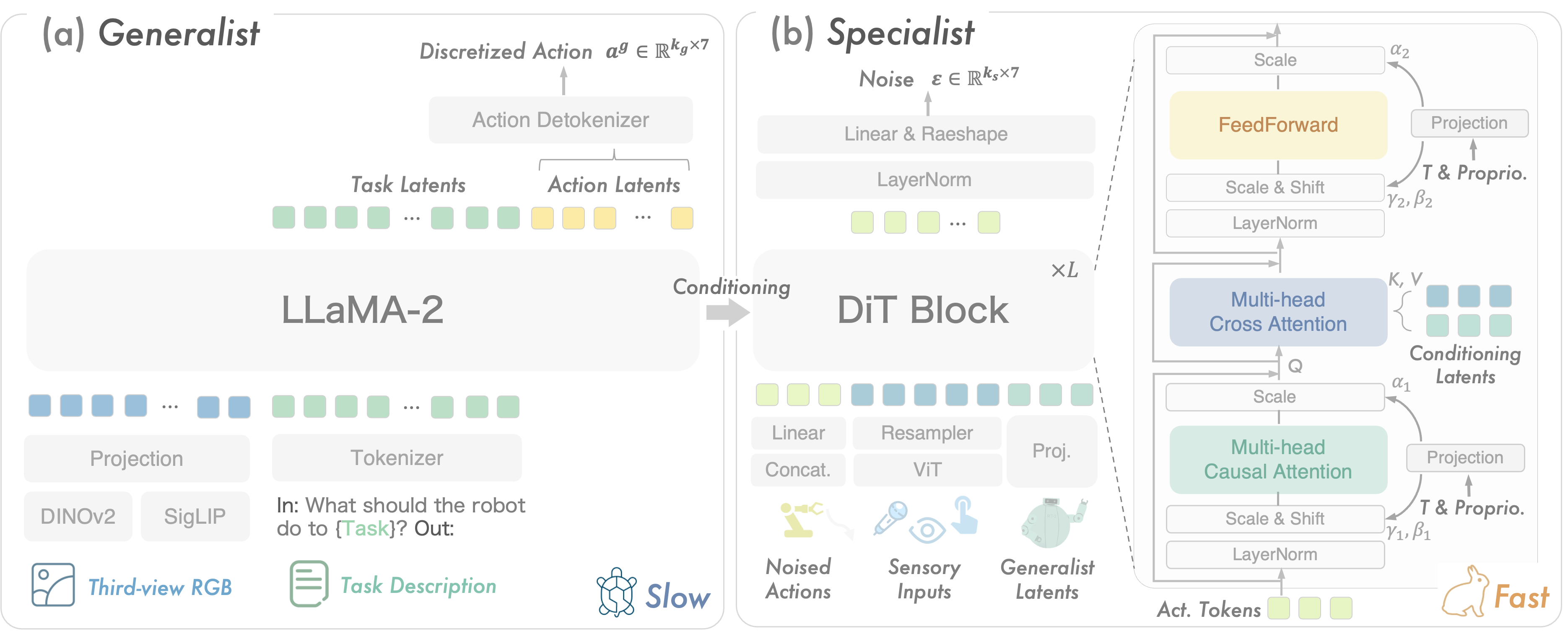
The overall architecture of RoboDual. (a) Generalist: The generalist takes as inputs RGB images and language prompts, generating conditioning sources for the specialist model, including latent representations and discretized actions. (b) Specialist: Comprising stacked Diffusion Transformer (DiT) blocks, the specialist is conditioned by multiple sensory inputs and the generalist's output through a cross-attention mechanism. It predicts noise injected into ground truth actions, providing fast, precise control by leveraging the slower, high-level guidance of the generalist.
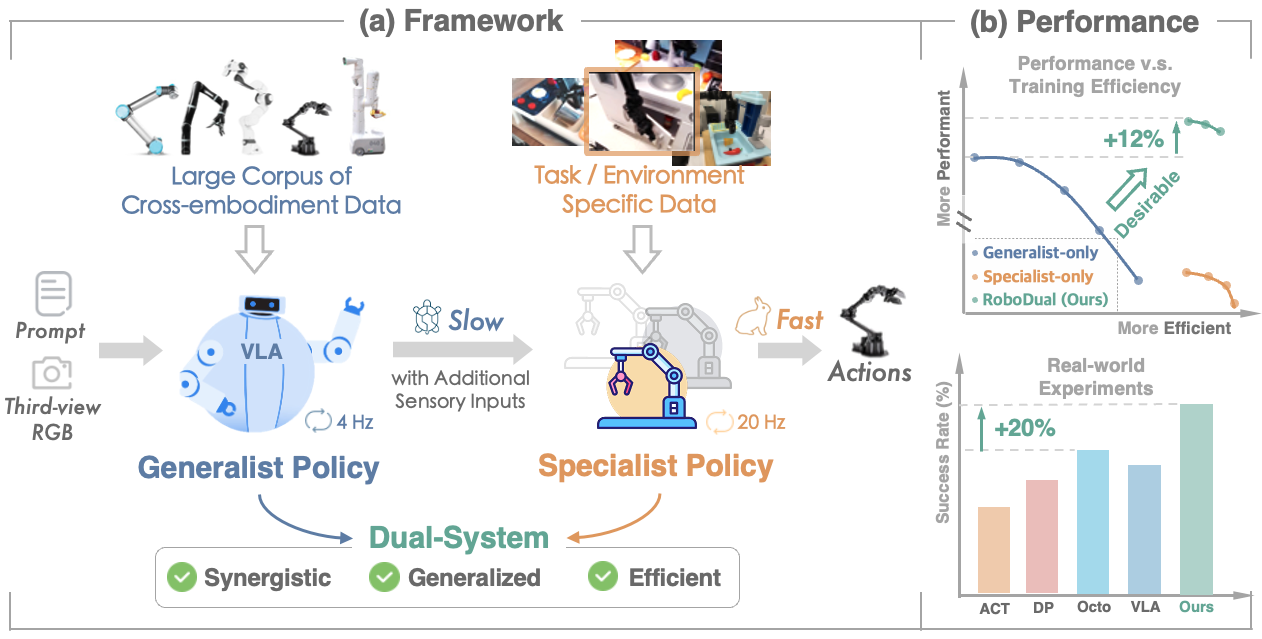
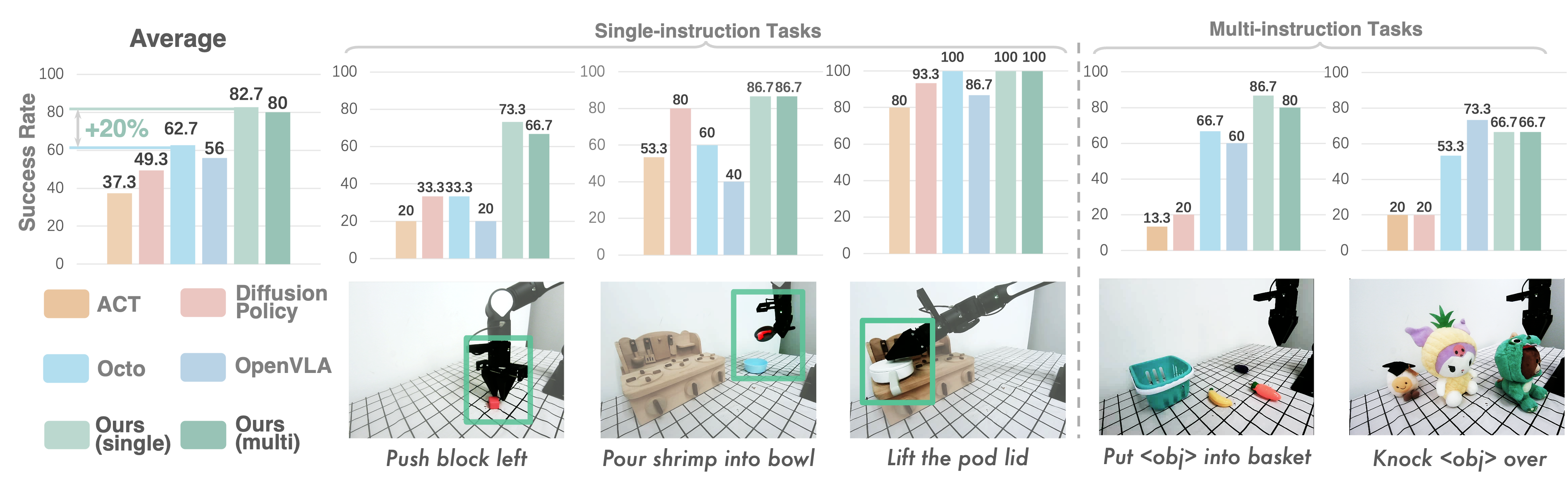
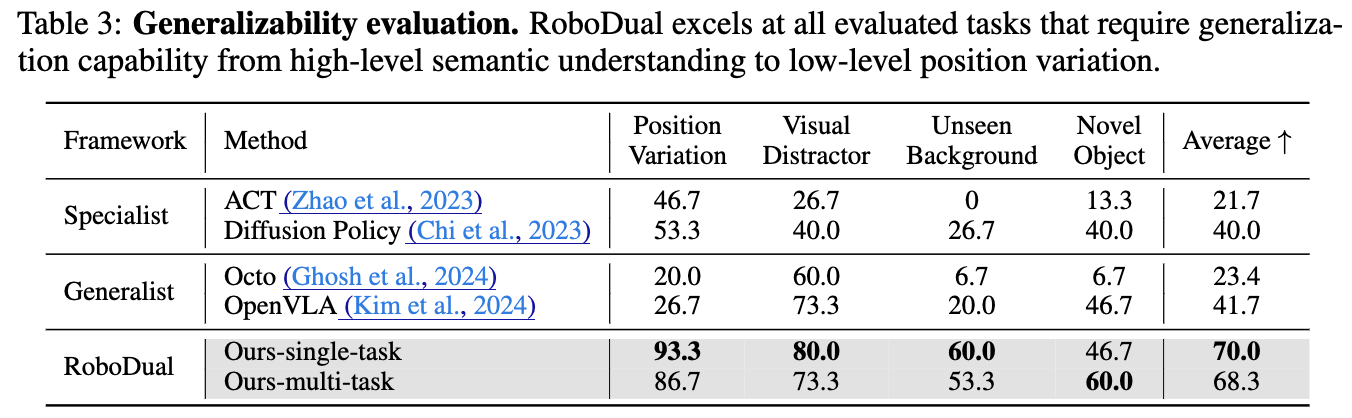
All real-world experiments are conducted with an AIRBOT Play robotic arm featuring a 7-DoF action space and a third-view RGB camera. We evaluate different policies on both single-instruction tasks ("Lift the Pod Lid", "Pour Shrimp into Bowl", and "Push the Block Left") and multi-instruction tasks ("Put [object] into Basket" and Knock [object] Over").
The following experiments are conducted with a NVIDIA RTX 4060 laptop GPU with only 8GB memories. We perform 4-bit quantization to OpenVLA and our generalist model to fit in the device. Specialist of RoboDual can still run at full precision.
Robodual achieves a control frequency of 15 Hz in our real-world setup using NVIDIA A5000 Ada GPUs, facilitating deployment in more dexterous tasks. Notably, inference latency is a primary factor contributing to the performance degradation of OpenVLA. Operating at only 3.9 Hz within our system, it significantly alters the system dynamics compared to the 20 Hz non-blocking controller used in our real-world tasks.
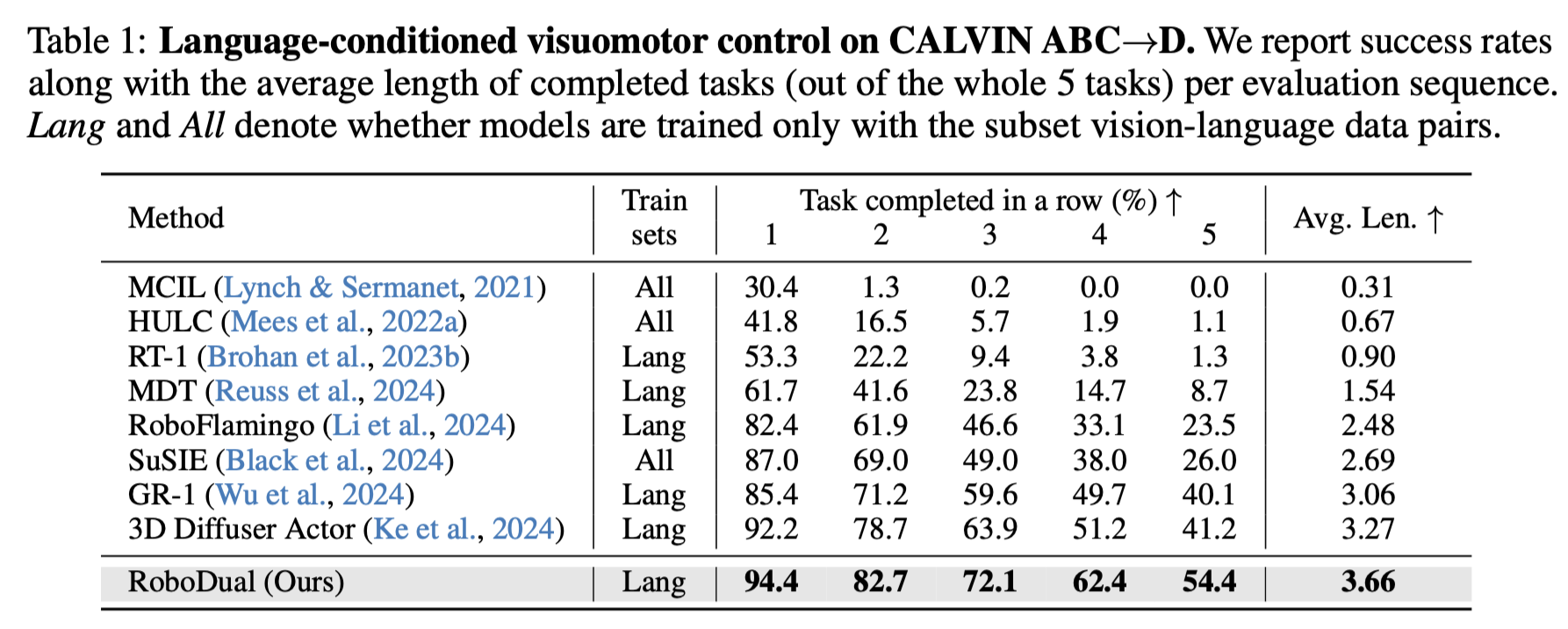
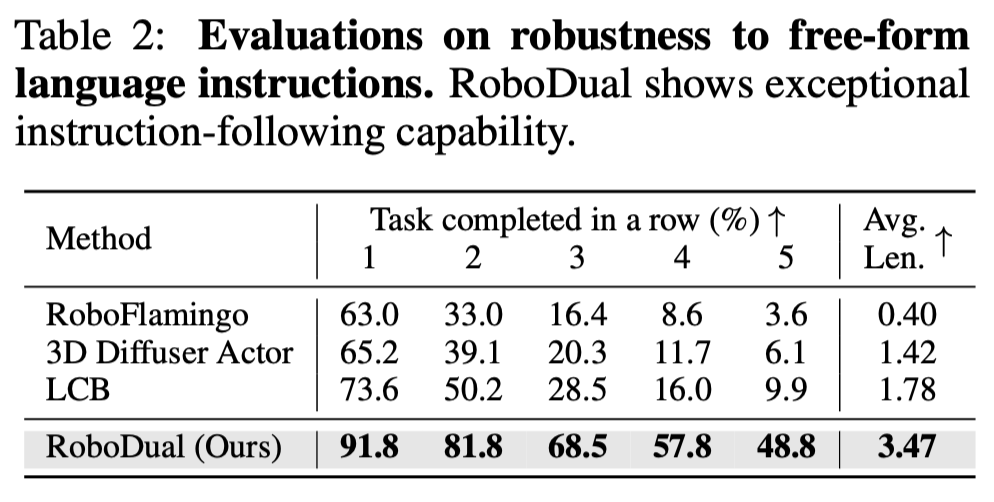
We compare the performance of RoboDual with other state-of-the-art methods on CALVIN ABC-D. We yield an improvement from 3.27 to 3.66 on the average length of completed tasks. The success rate of accomplishing consecutive 5 tasks is elevated by 13.2%. Additionally, we further investigate the robustness to free-form task instructions of various methods. We incorporate RoboFlamingo and LCB, both of which also utilize LLMs (MPT-1B and LLaVA-7B respectively), as our baseline approaches. All methods are trained exclusively on the ABC split using the original language annotations and are evaluated with GPT-4 enriched ones. While the performance of baseline methods decreases significantly compared to their results in default setting, our method exhibits minimal impact and nearly doubles the average length compared to LCB. This improvement can be attributed to both the semantic understanding capability of the generalist and the specialist model's robustness to variations in conditioning latents.
@article{bu2024robodual,
title={Towards Synergistic, Generalized, and Efficient Dual-System for Robotic Manipulation},
author={Qingwen Bu and Hongyang Li and Li Chen and Jisong Cai and Jia Zeng and Heming Cui and Maoqing Yao and Yu Qiao},
journal={arXiv preprint arXiv:2410.08001},
year={2024},
}