Hai Zhang*, Siqi Liang*, Li Chen, Yuxian Li, Yukuan Xu, Yichao Zhong, Fu Zhang, Hongyang Li
The University of Hong Kong
*Equal Contribution


SparseVideoNav achieves a 20-second future horizon with sub-second trajectory inference latency. This represents a 27× speed-up compared to unoptimized counterpart.
Introduces video generation models into vision-language navigation for the first time, overcoming short-horizon limitations of LLM-based methods in challenging beyond-the-view cases.
Achieves sub-second trajectory inference with sparse 20-second future prediction, enabling 27× speed-up for practical real-world deployment.
Achieves 2.5× success rate over LLM-based baselines on beyond-the-view tasks and marks the first realization of such capability in challenging night scenes.
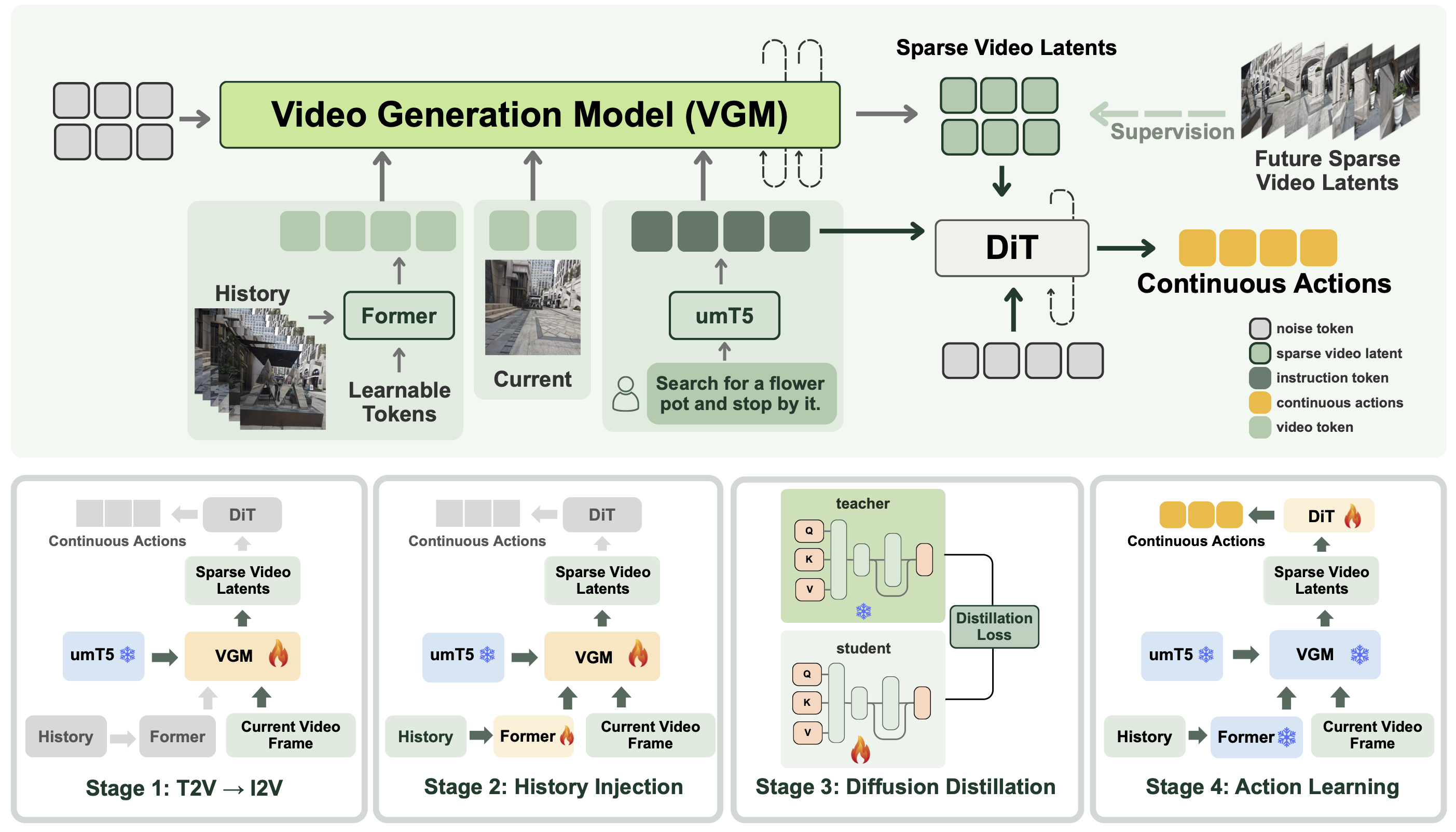
(Top) denotes our whole training architecture. Current observation, historical observations, and the language instruction are fed into the video generation model (VGM) backbone to generate future sparse video latents. DiT-based action head then predicts continuous actions conditioned on generated sparse future and the language instruction.
(Bottom) denotes our four-stage training pipeline: Stage 1 adapting T2V to I2V, Stage 2 injecting history into I2V backbone; Stage 3 distilling the backbone to reduce denoising steps; Stage 4 learning actions based on generated sparse future. Components not utilized in a specific stage are indicated by gray blocks.
The largest real-world VLN dataset to date.
We will open-source the dataset to benefit the community. The estimated release time is 2026 Q3 due to restriction policy.
@article{zhang2026sparse,
title={Sparse Video Generation Propels Real-World Beyond-the-View Vision-Language Navigation},
author={Zhang, Hai and Liang, Siqi and Chen, Li and Li, Yuxian and Xu, Yukuan and Zhong, Yichao and Zhang, Fu and Li, Hongyang},
journal={arXiv preprint arXiv:2602.05827},
year={2026}
}