
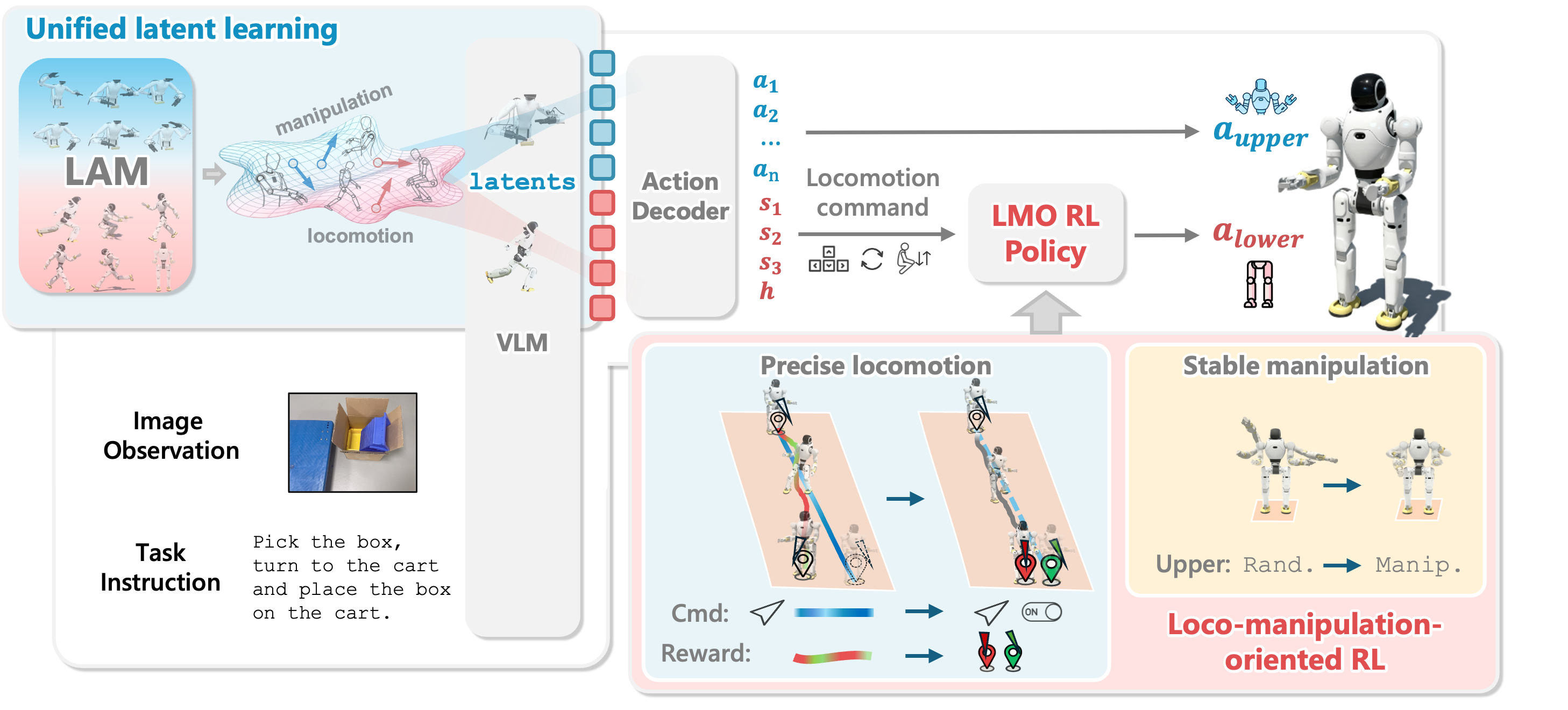
WholeBodyVLA Performance in Complex Tasks
Adaptability & Scalability
Demonstrate WholeBodyVLA's robustness to variations in objects appearance and position, layout, and table color.
Showcase WholeBodyVLA's ability to compose forward advancing, sidestepping, turning, and squatting to handle diverse start-poses (X/Y offsets, orientations, and table heights).
Demonstrate WholeBodyVLA's ability to traverse uneven terrain.
Demonstrate WholeBodyVLA's competence on long-horizon sequences that involve loco-manipualtion and whole-body coordinated actions.
Showcase WholeBodyVLA's scalability to more complex everyday loco-manipulation tasks (e.g., wiping, vacuum cleaning, etc).




