1 Intelligent Vehicle Research Center at Beijing Institute of Technology
2 OpenDriveLab at The University of HongKong
3 Nanyang Technological University
4 NVIDIA Research
5 Yinwang Intelligent Tech. Co. Ltd.
†Work done while interning at OpenDriveLab
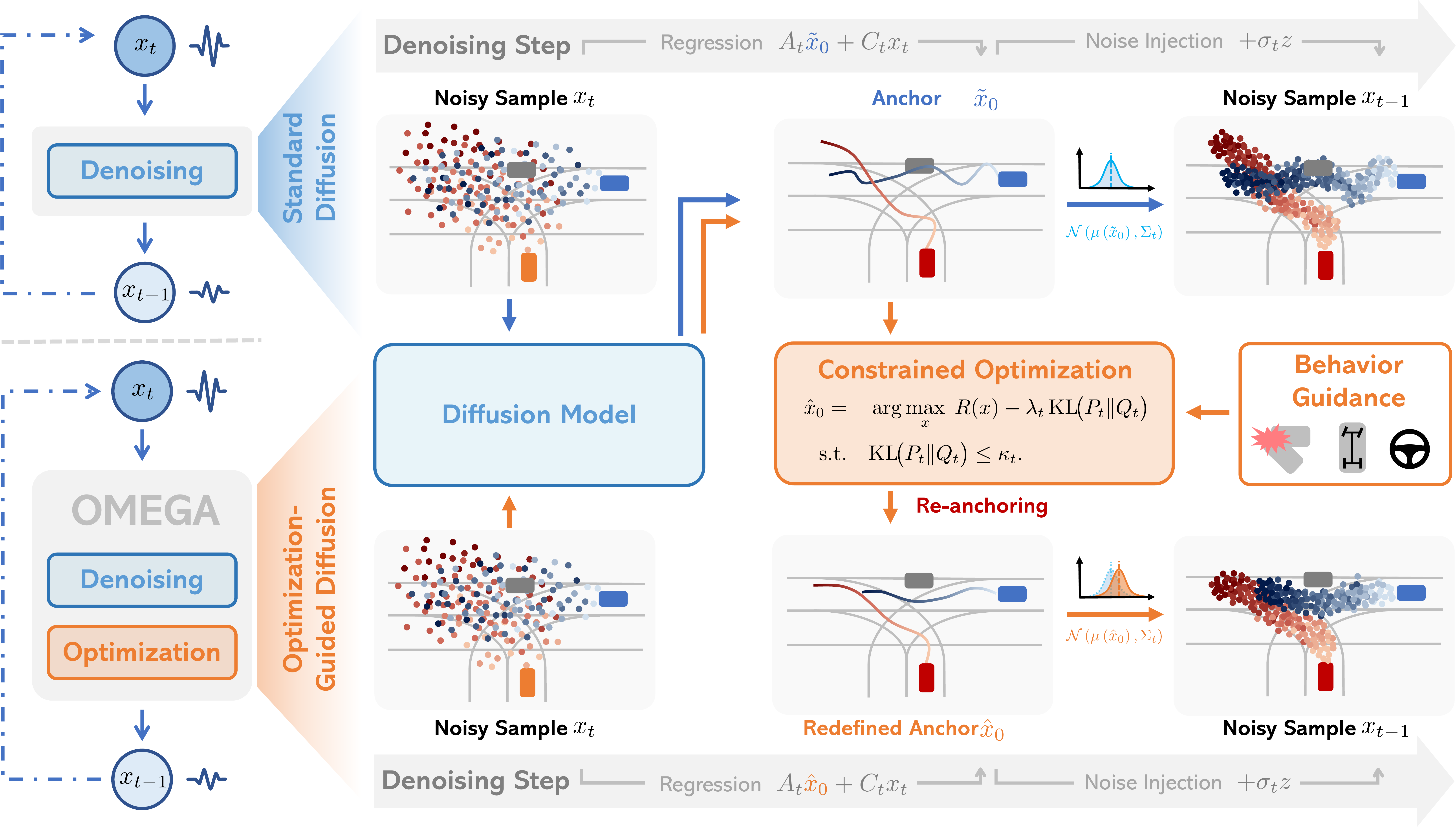
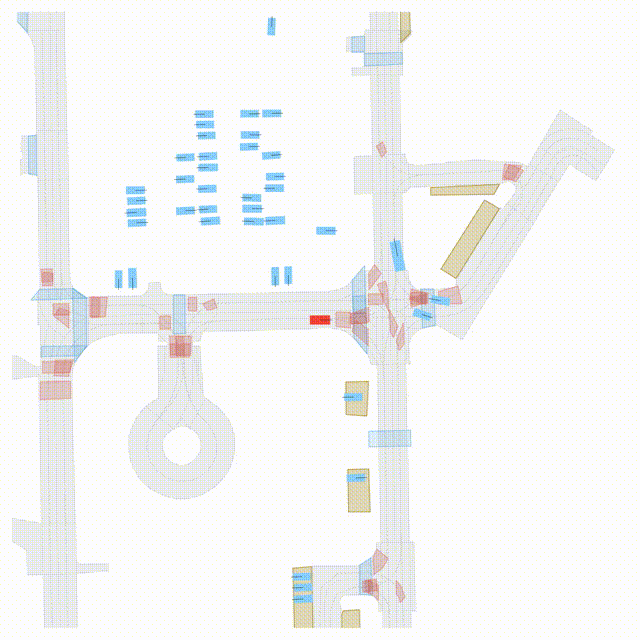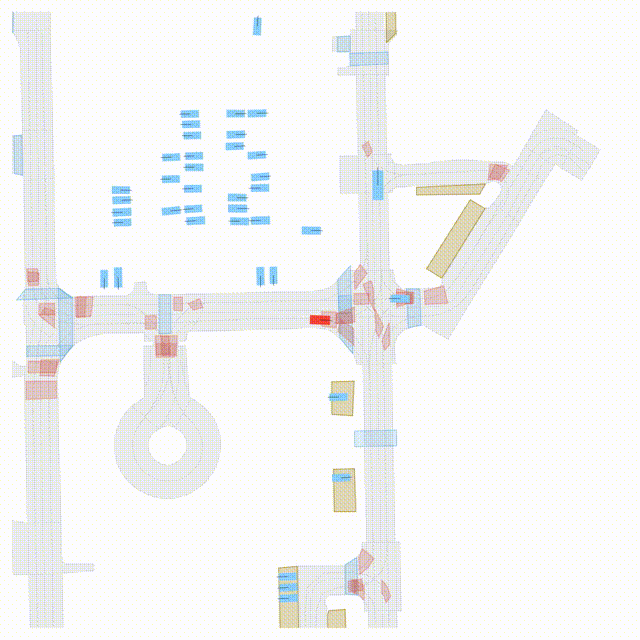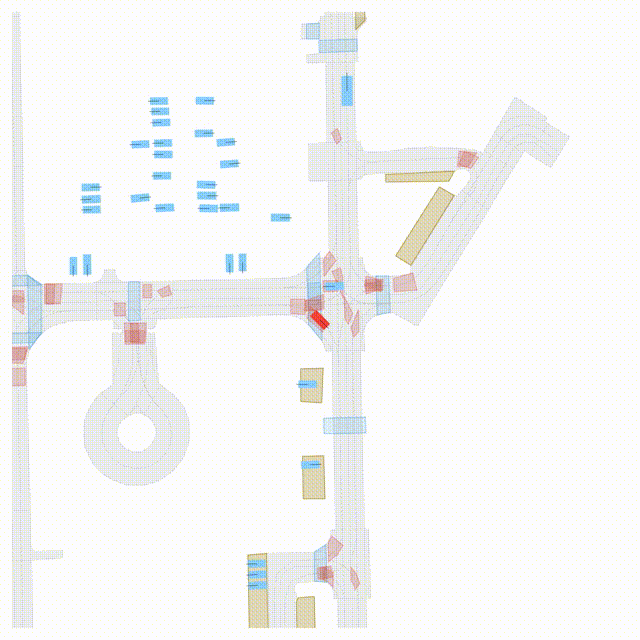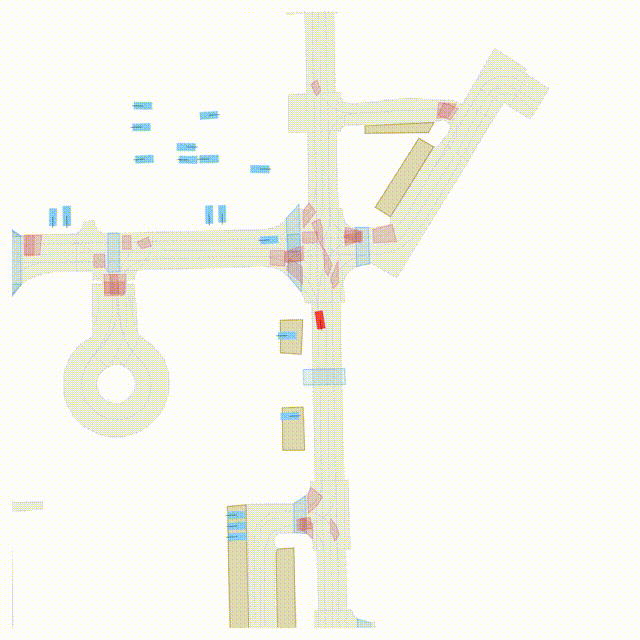
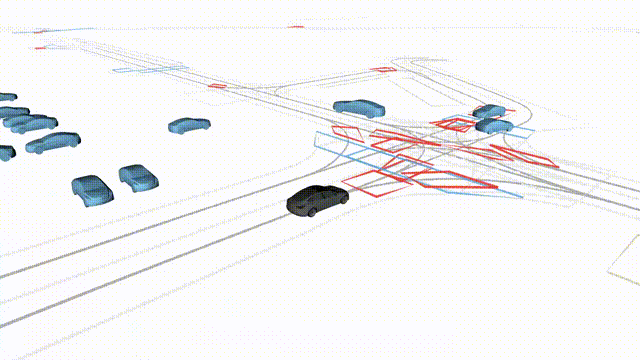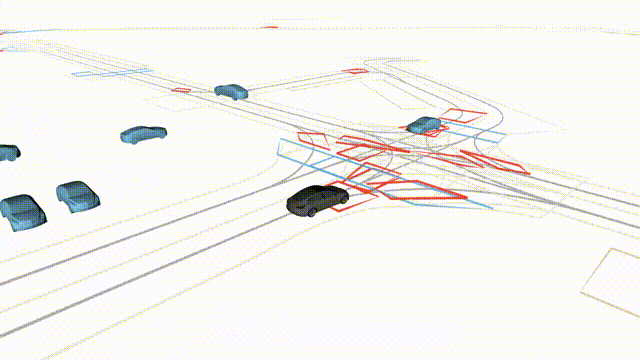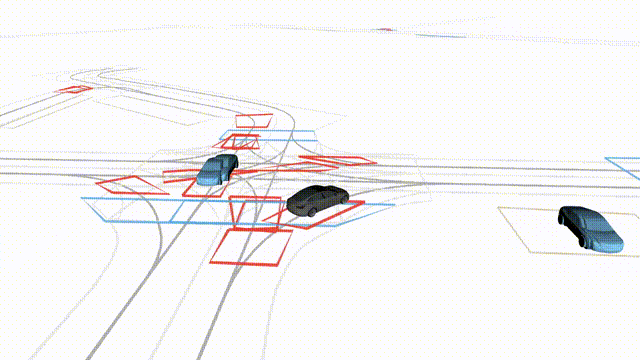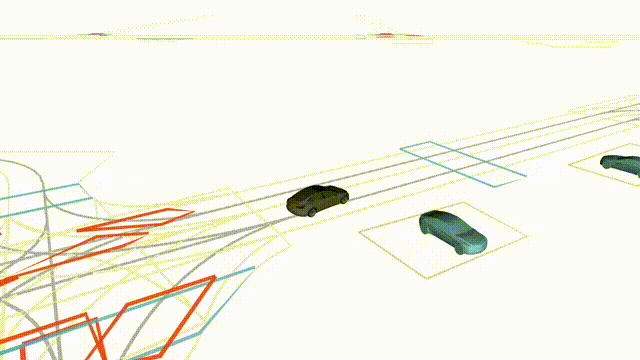
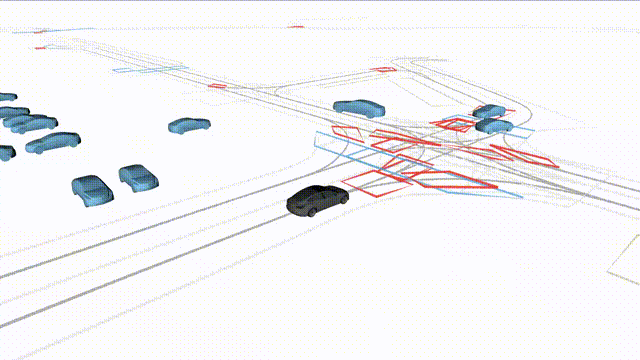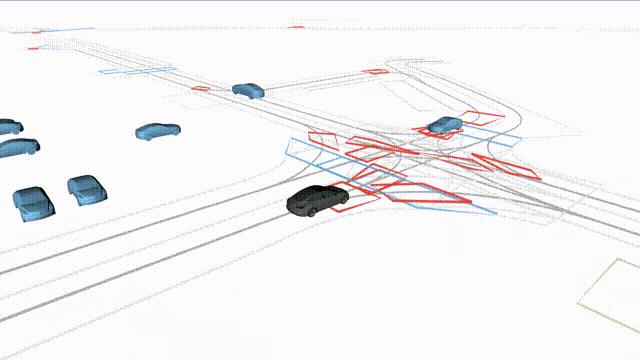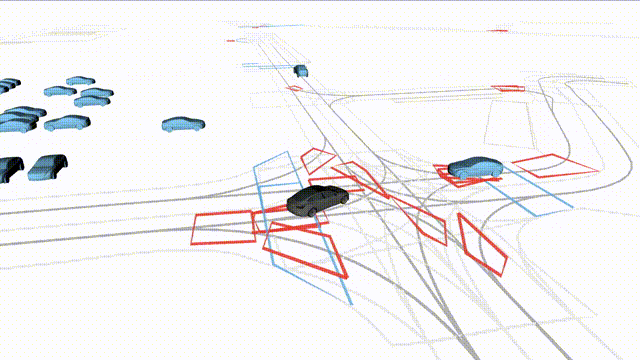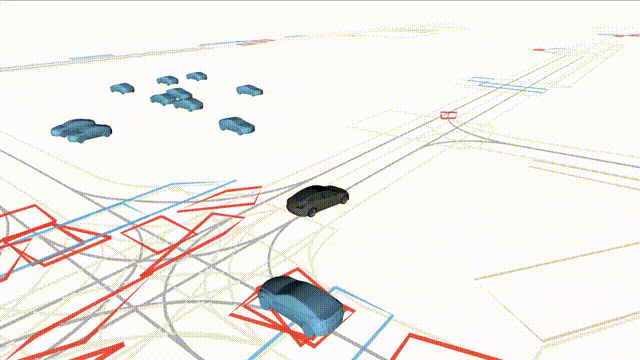
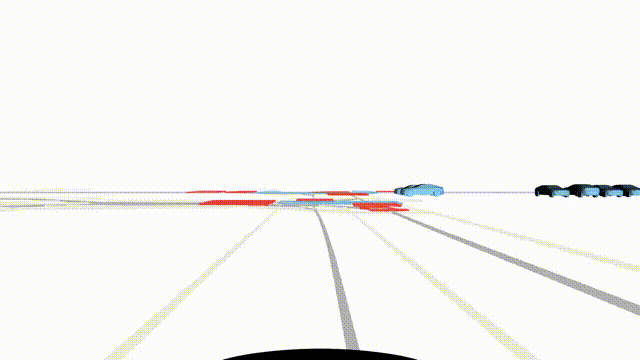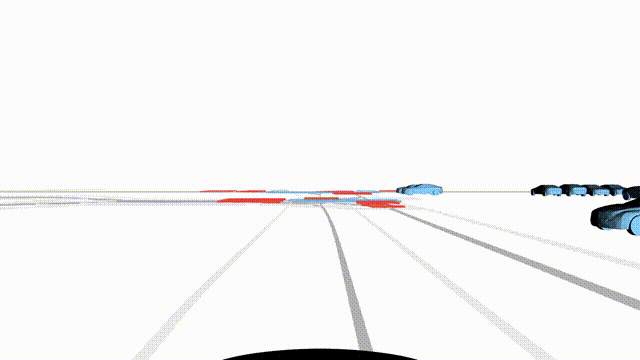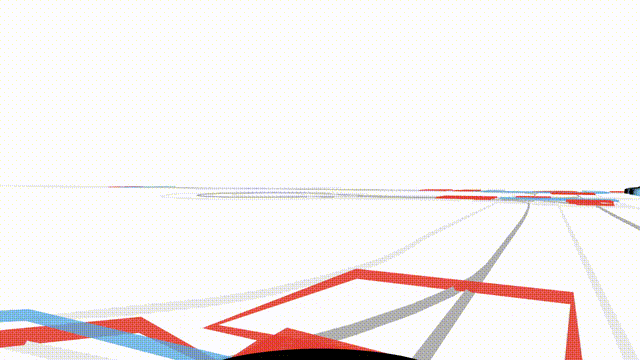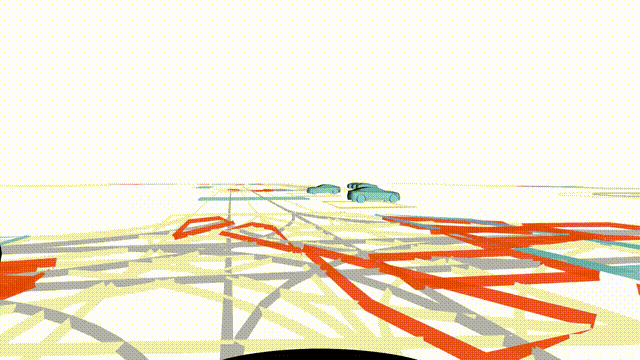
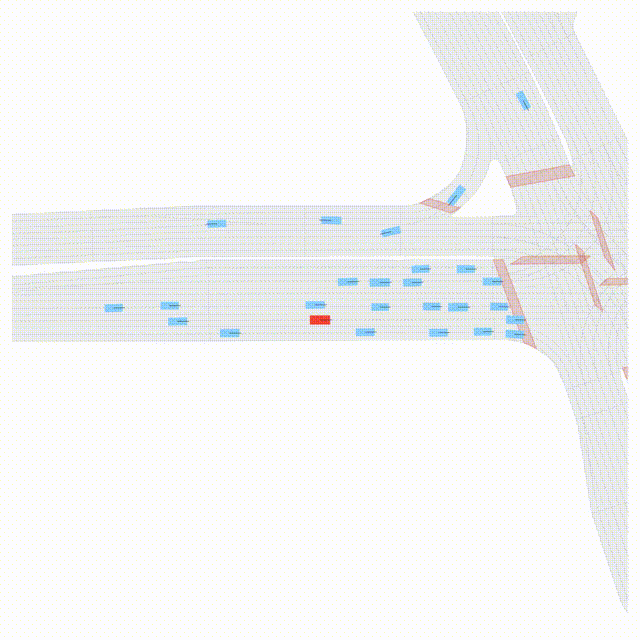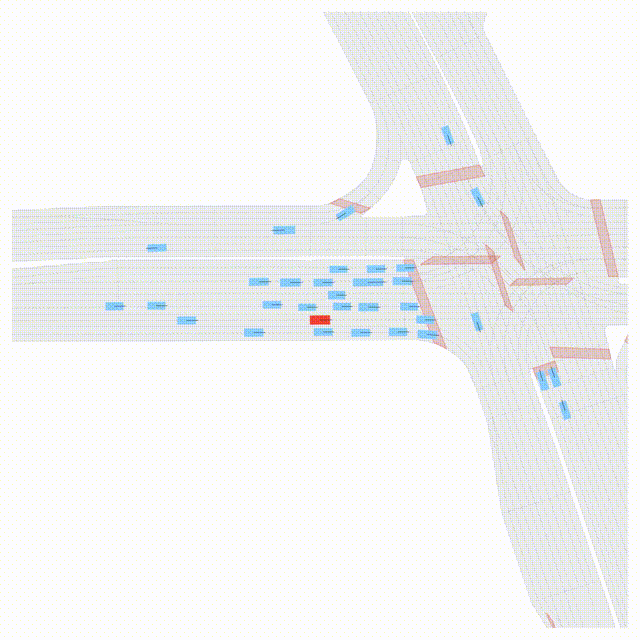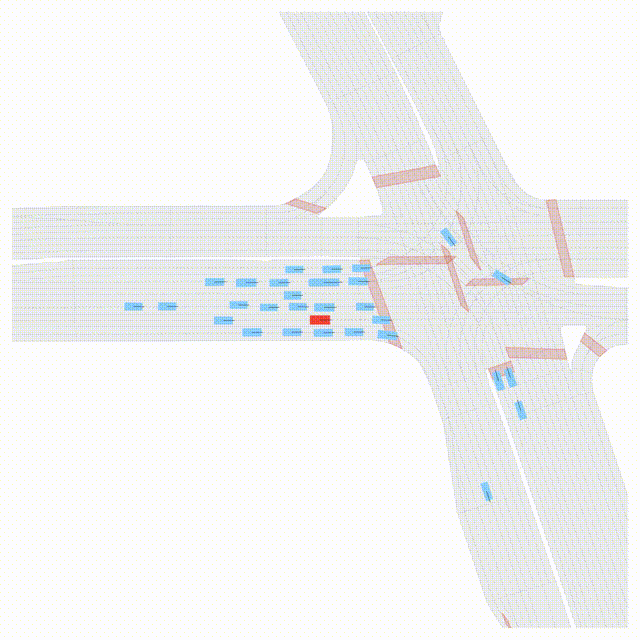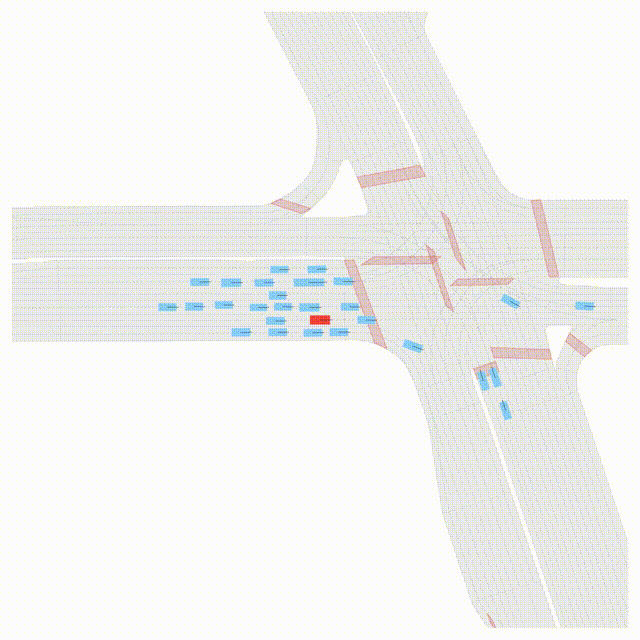
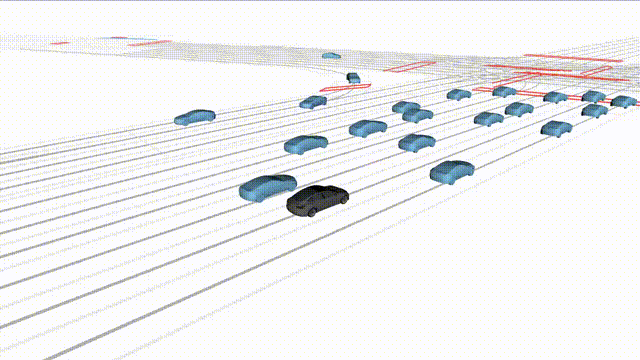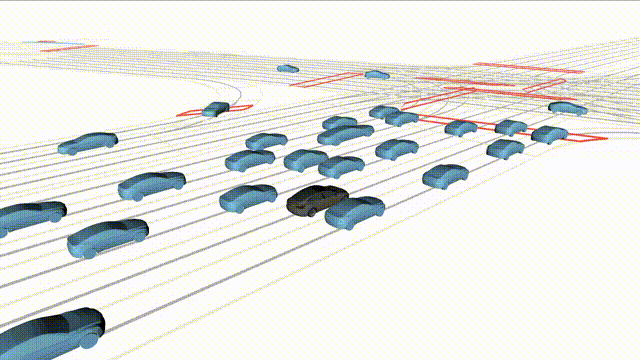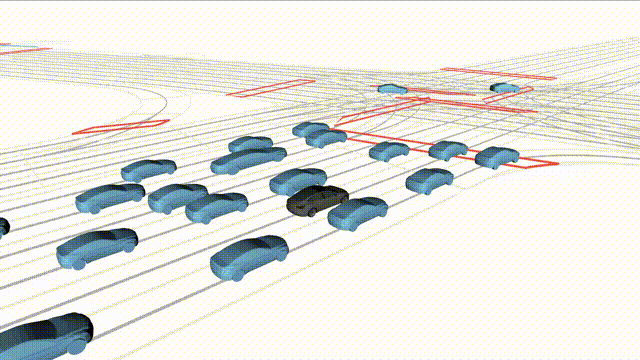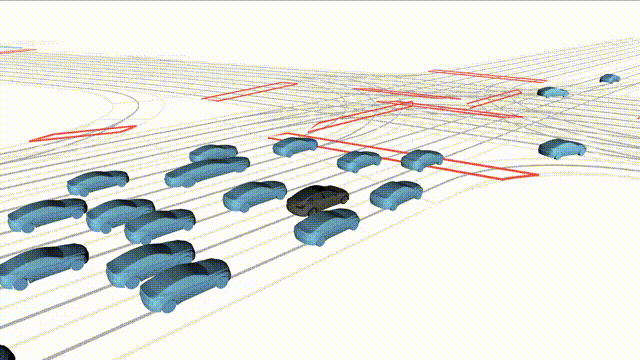
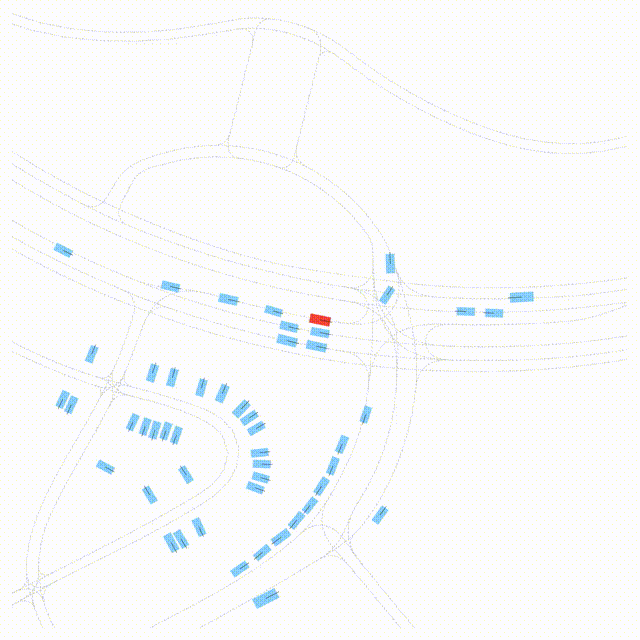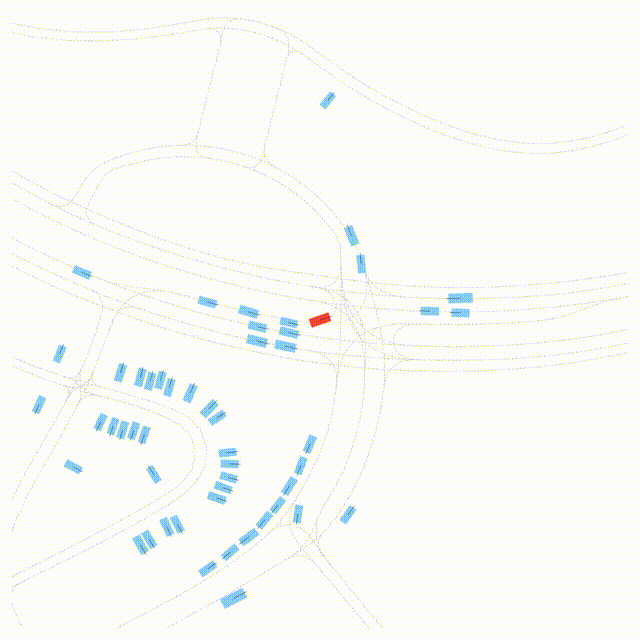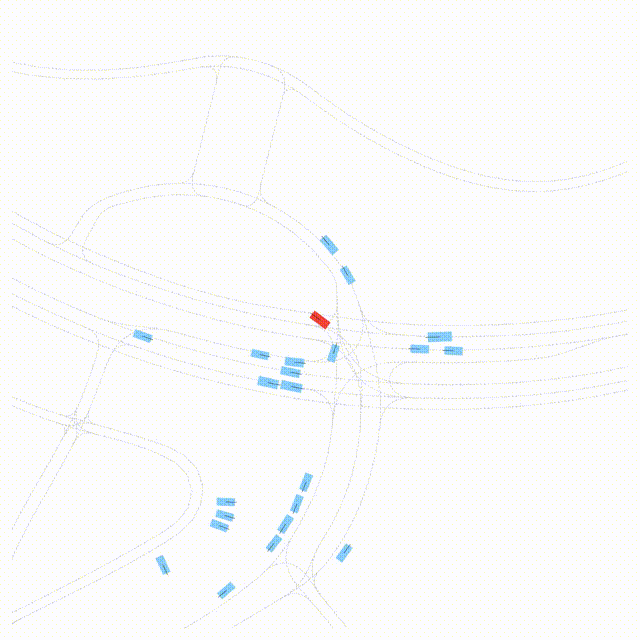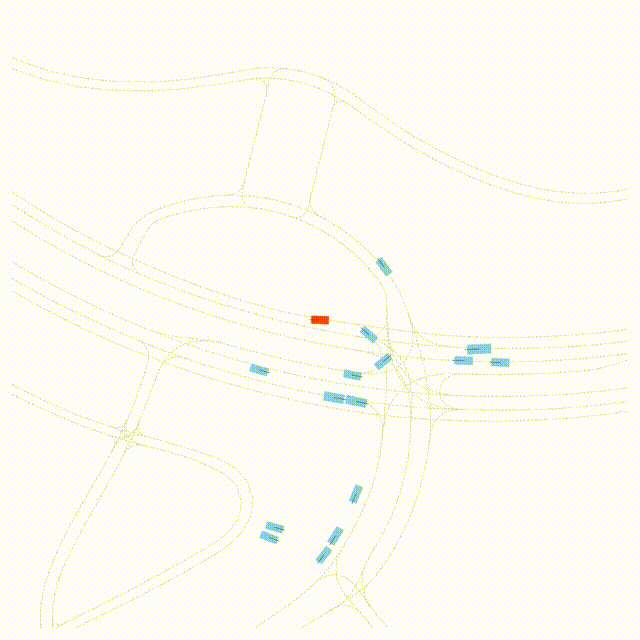
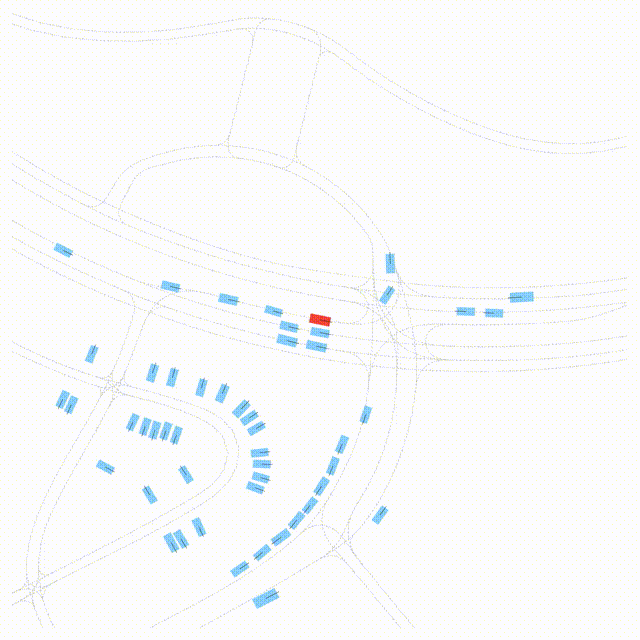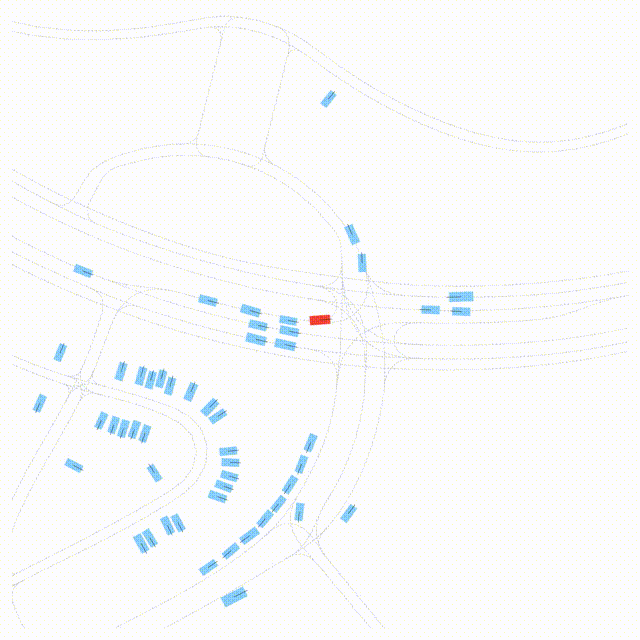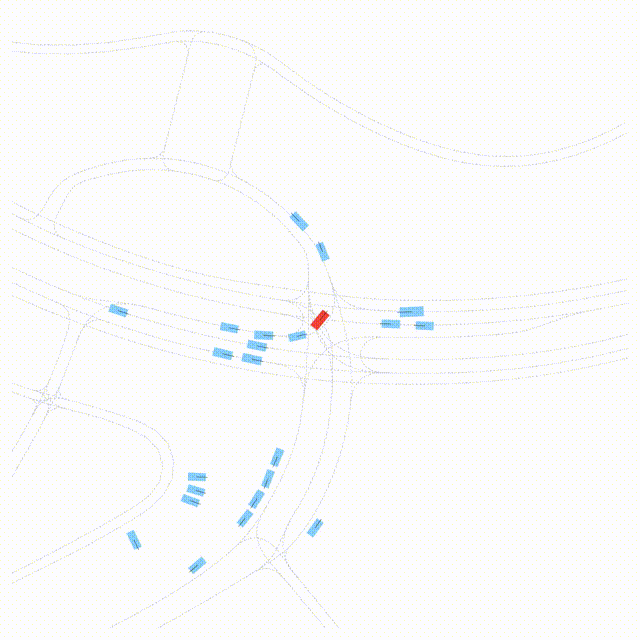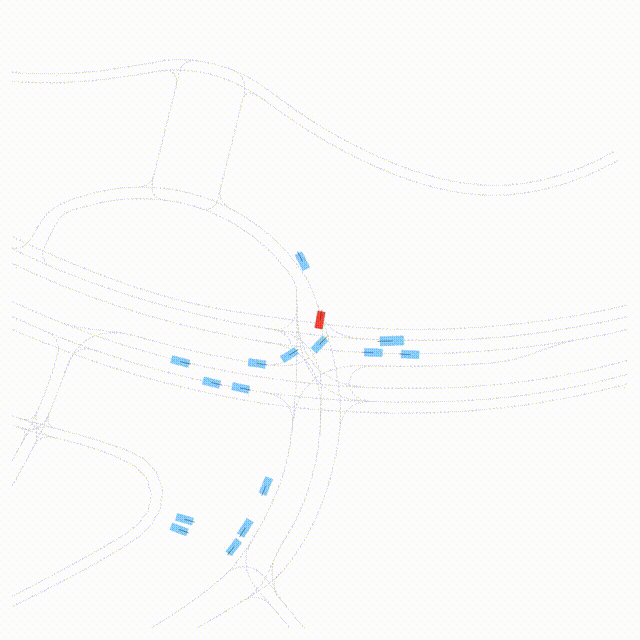
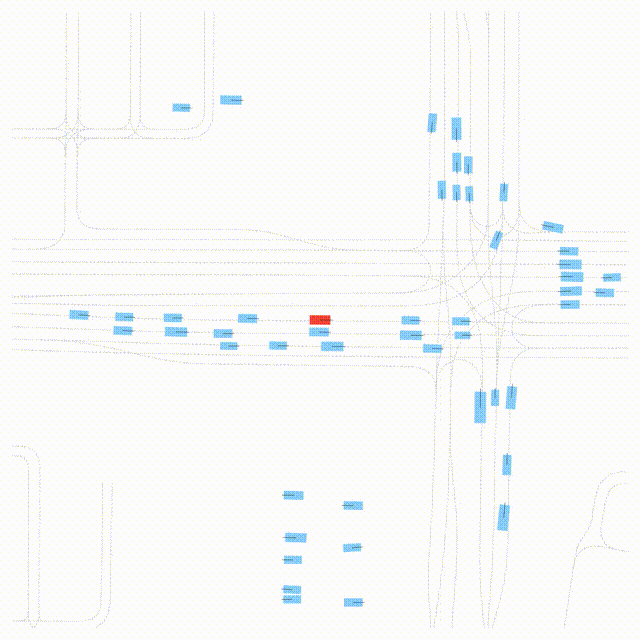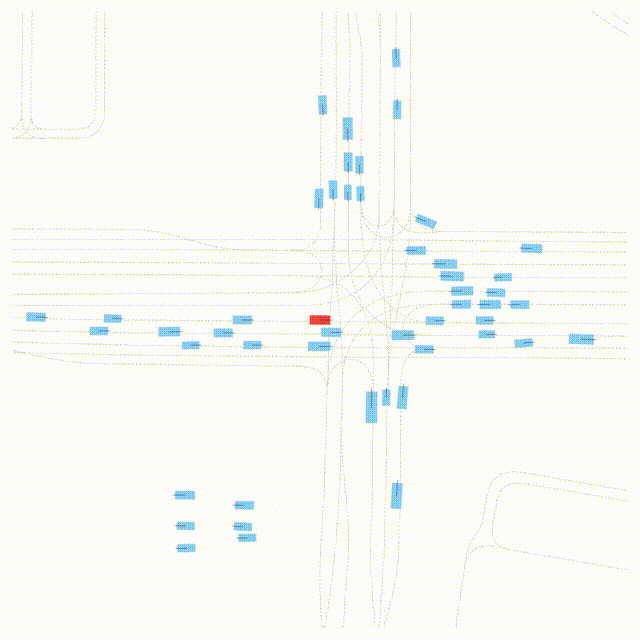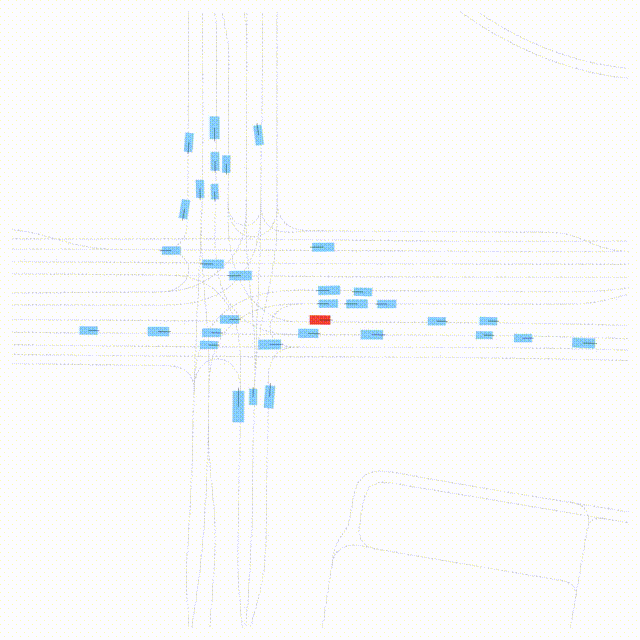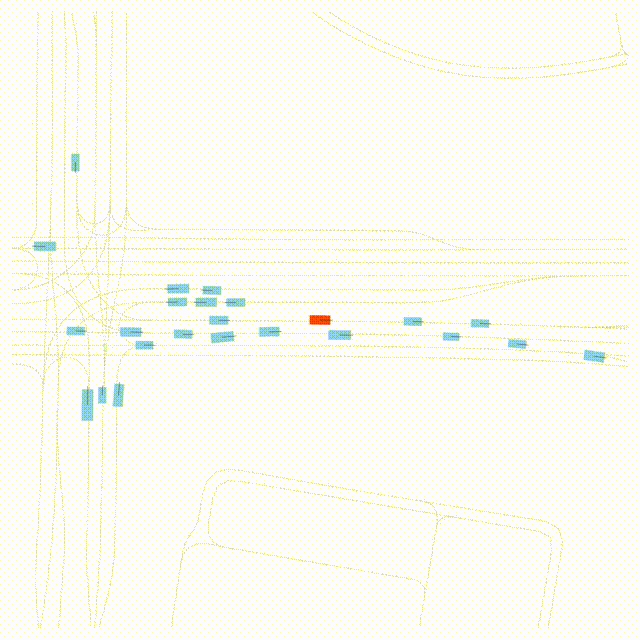
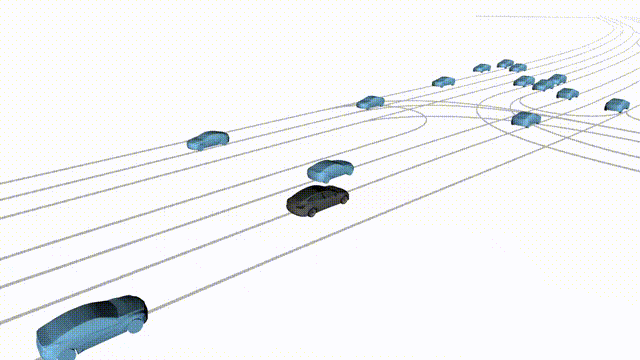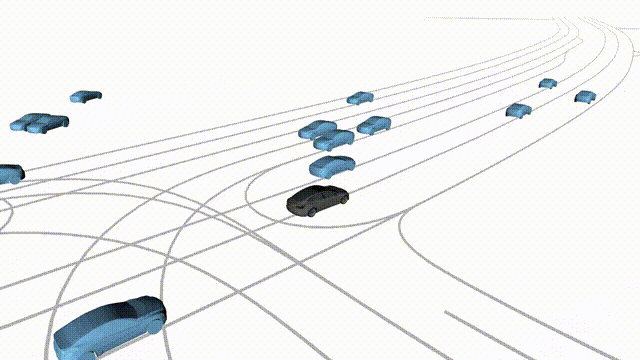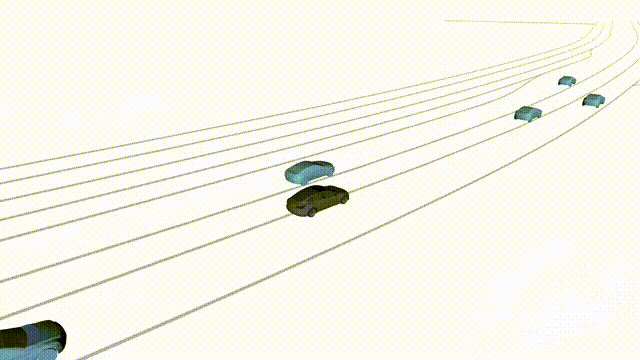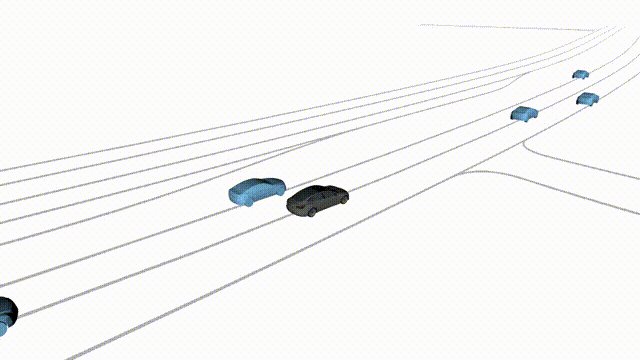
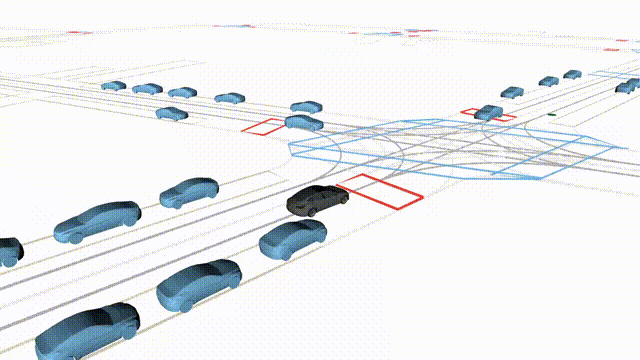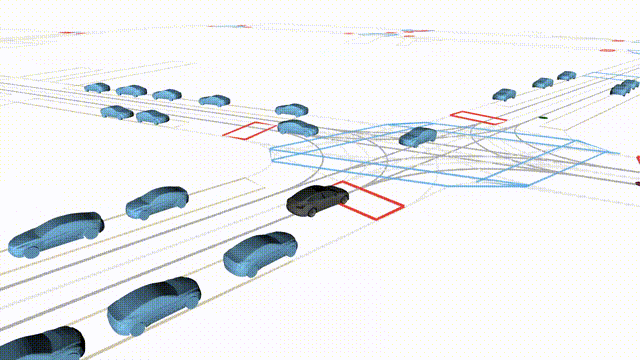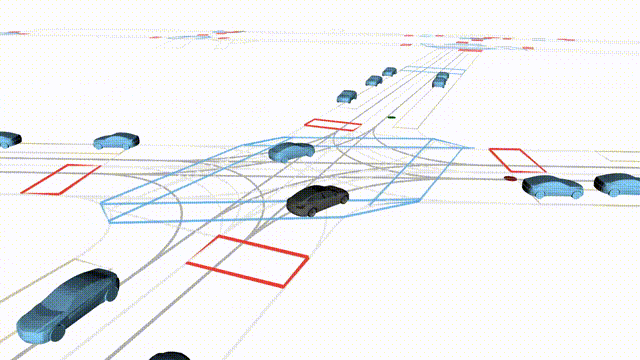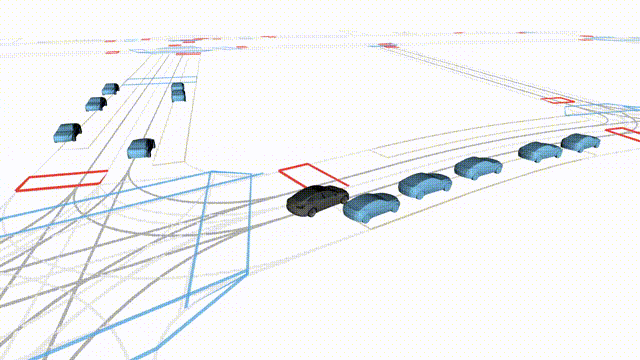
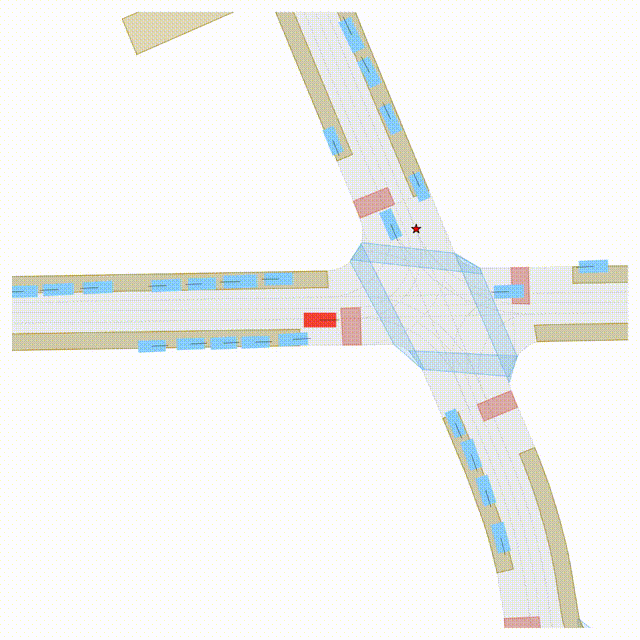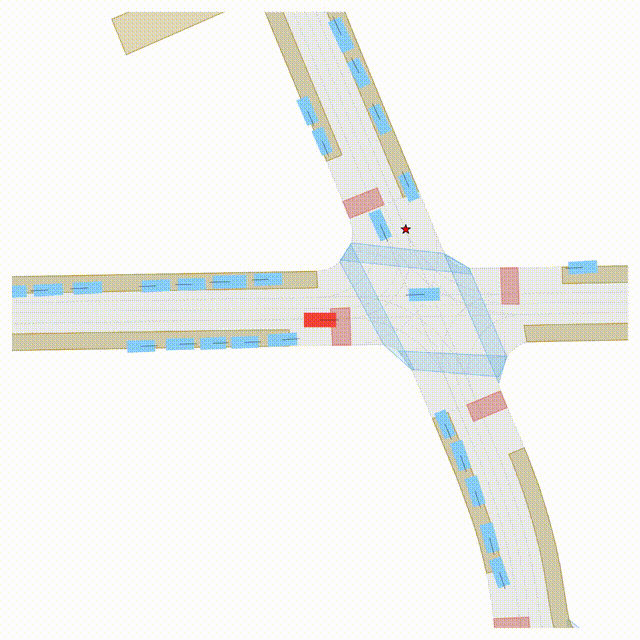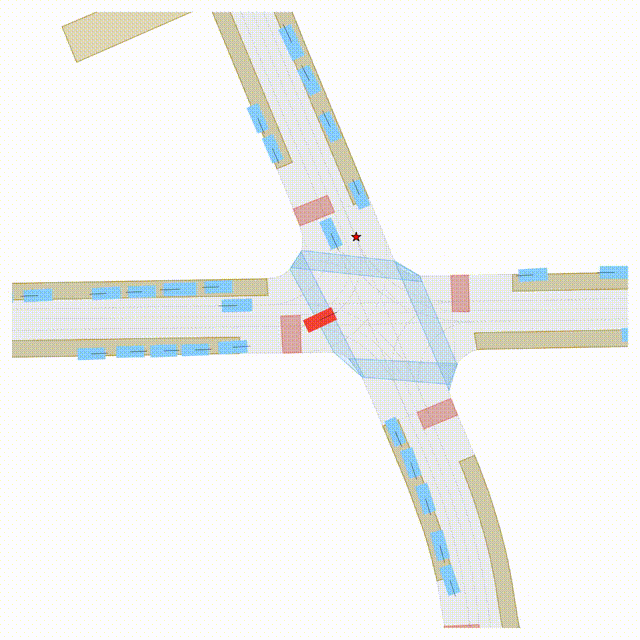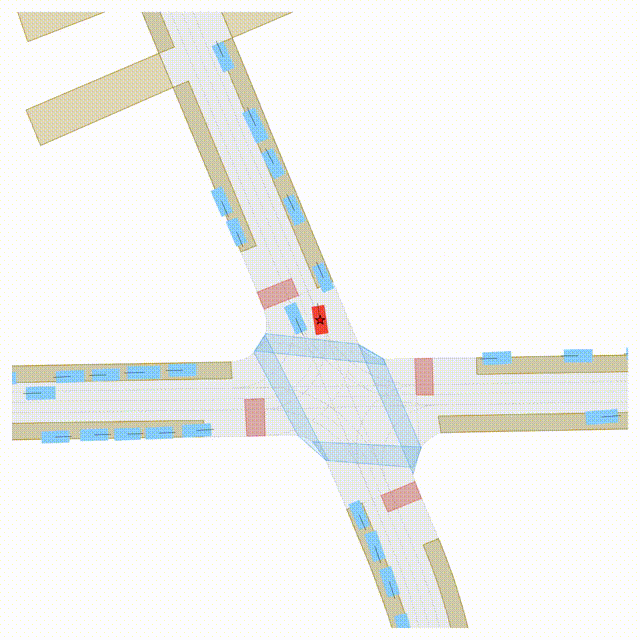
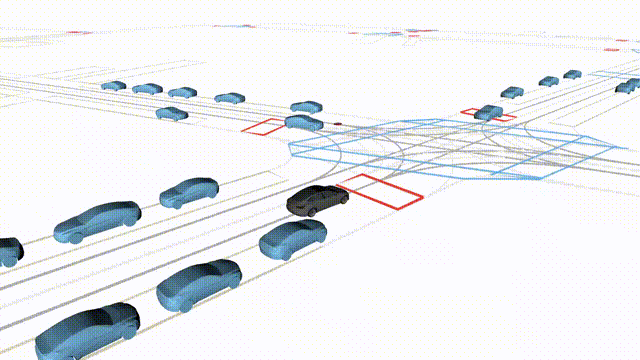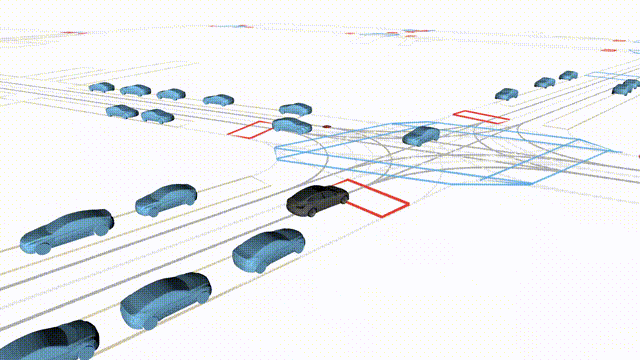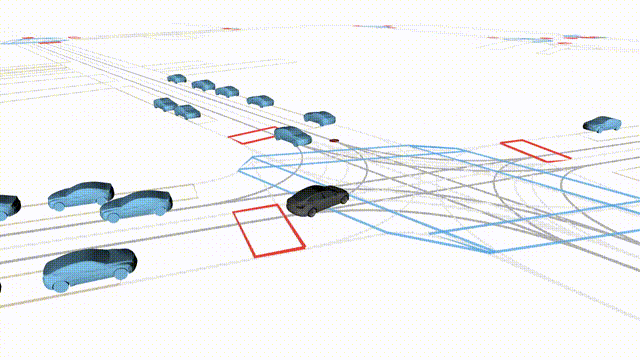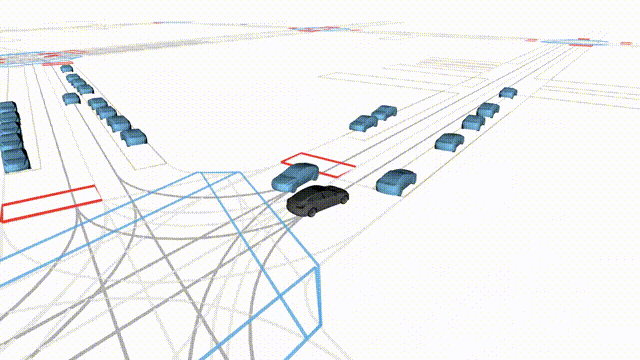
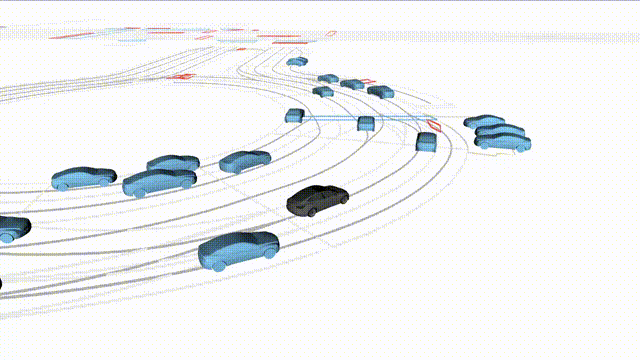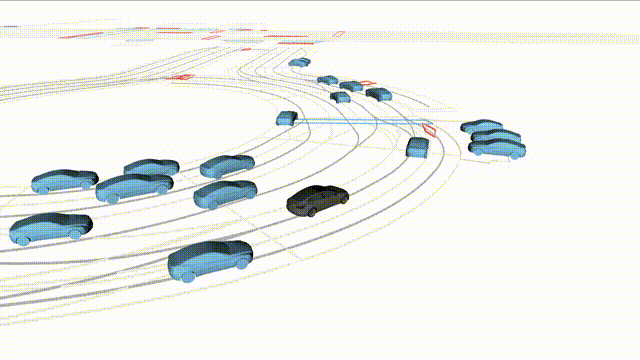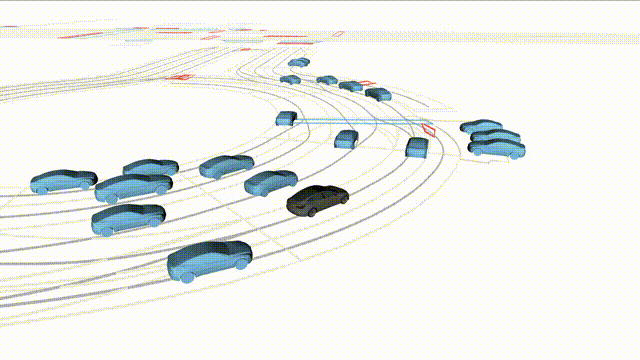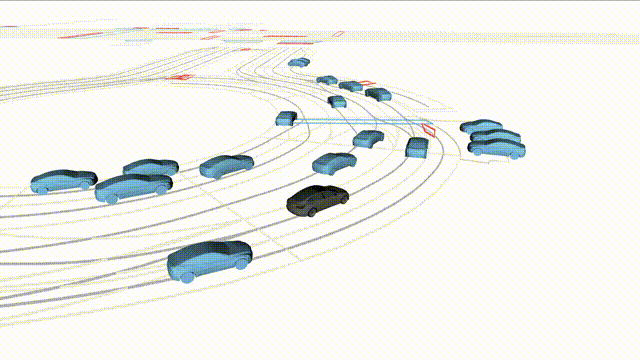
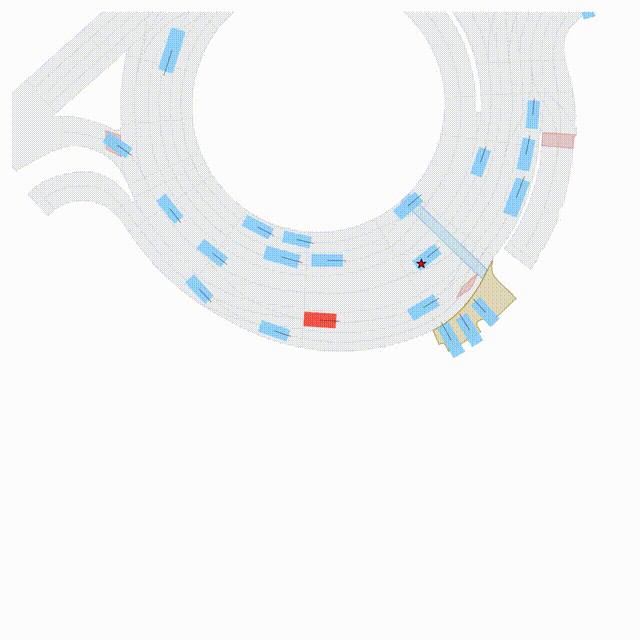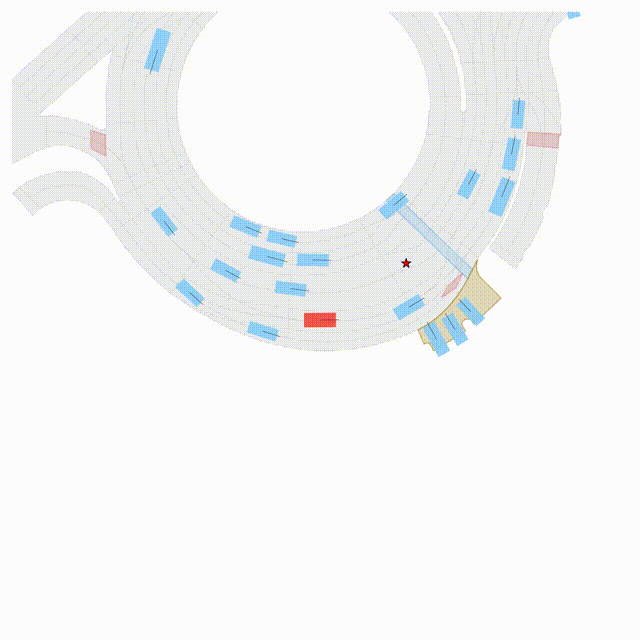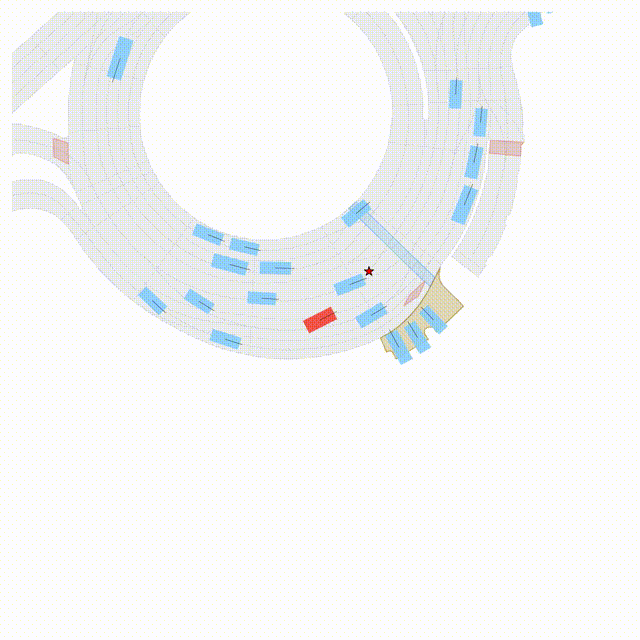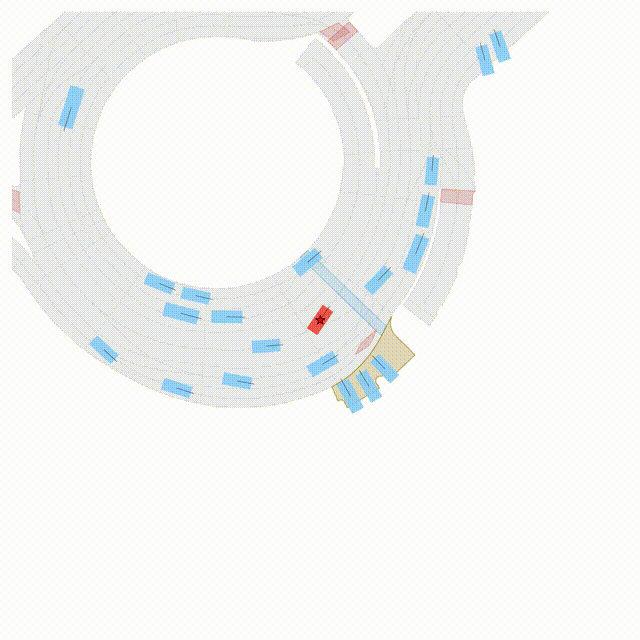
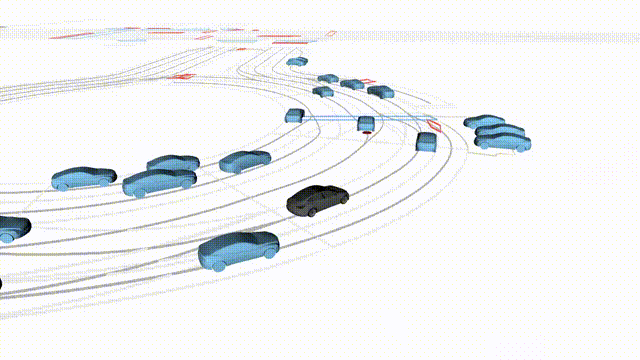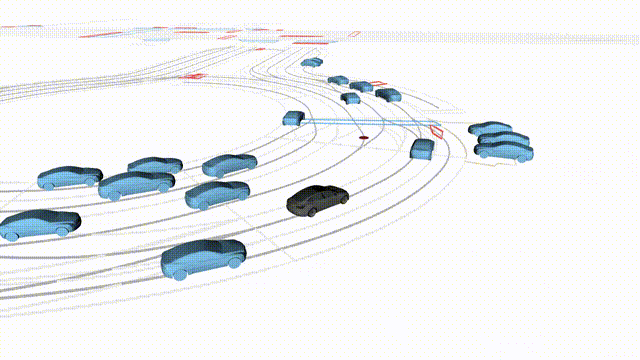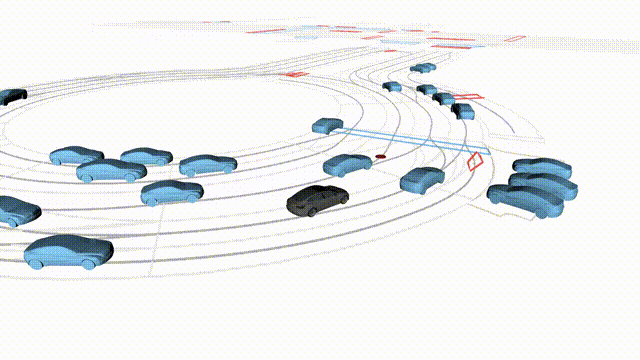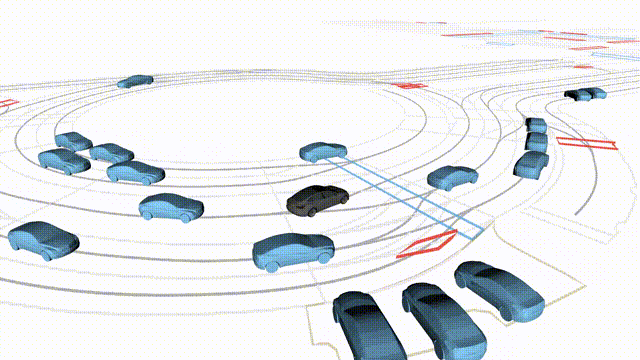
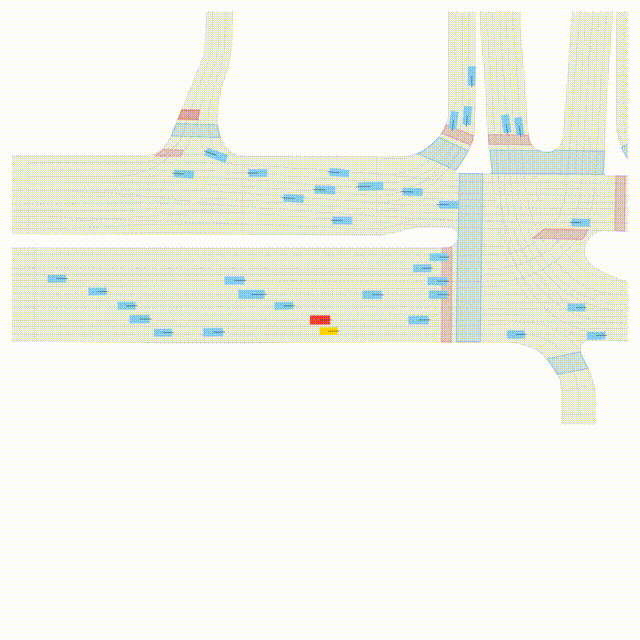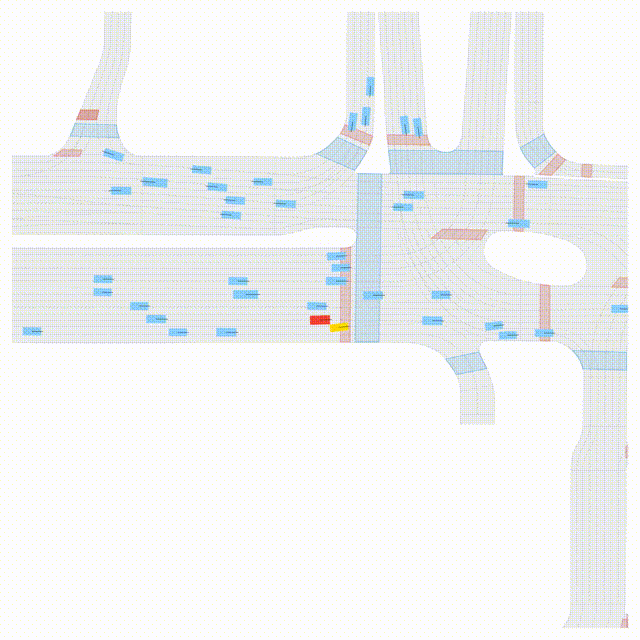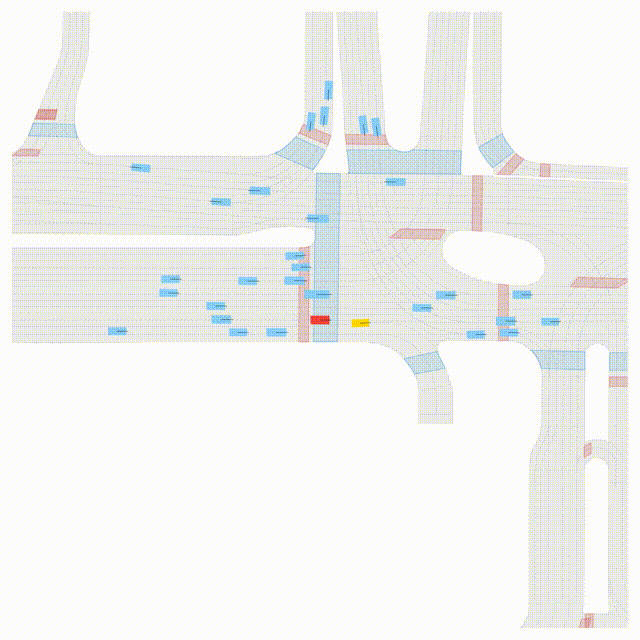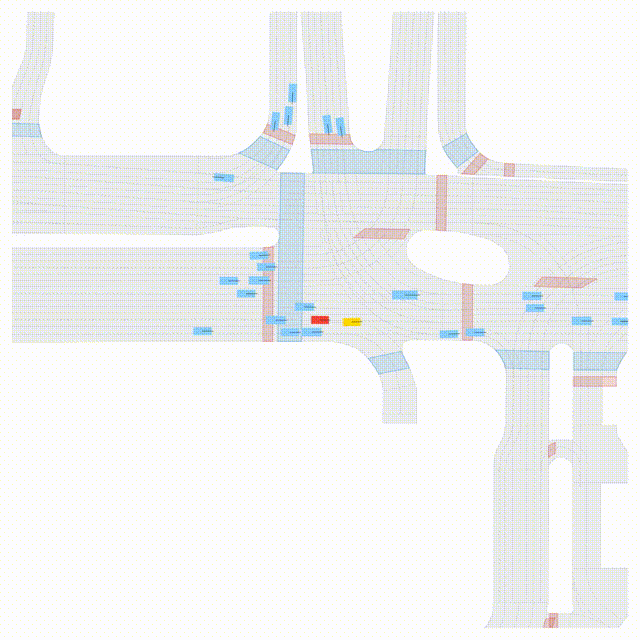
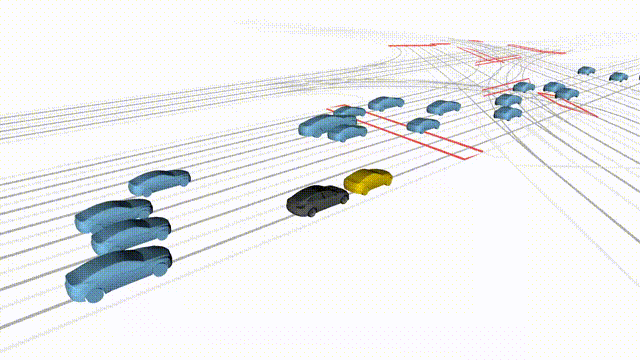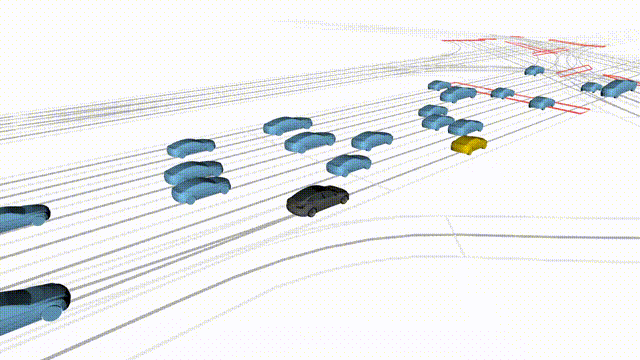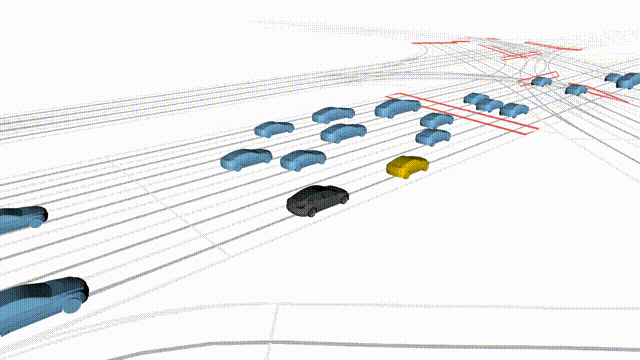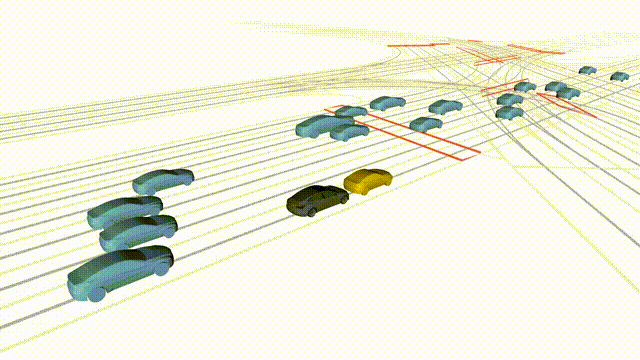
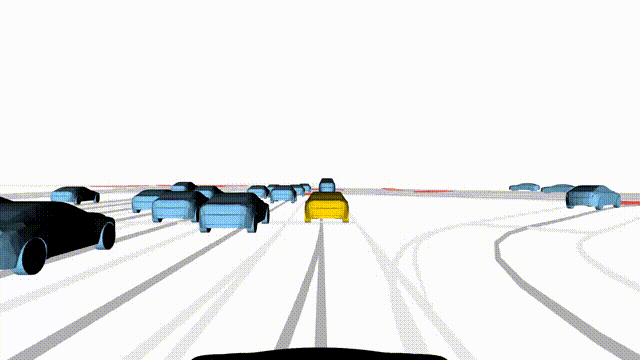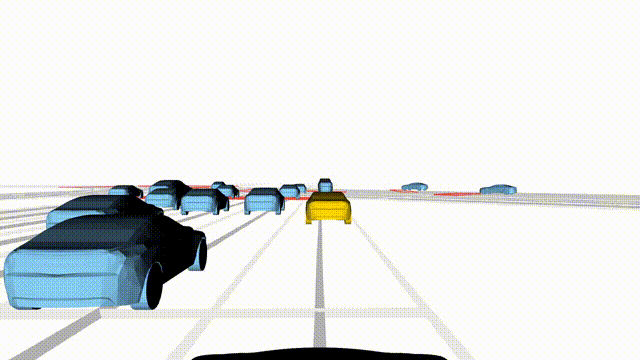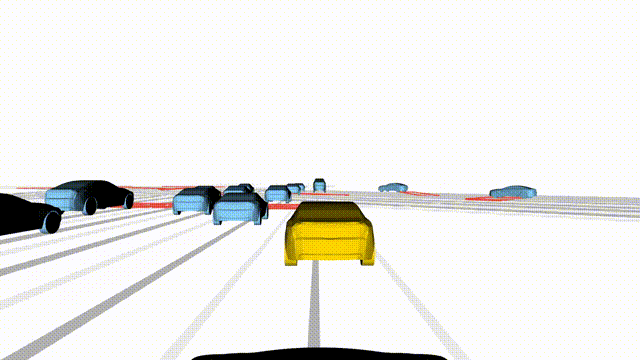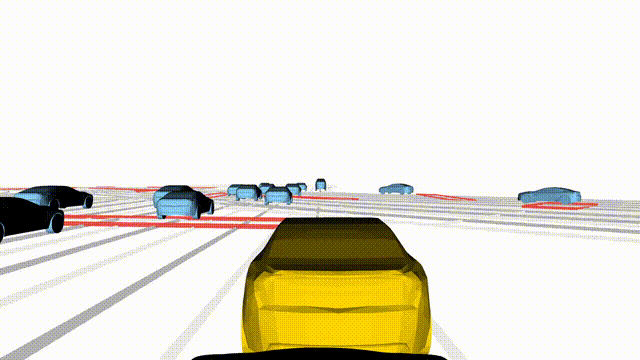
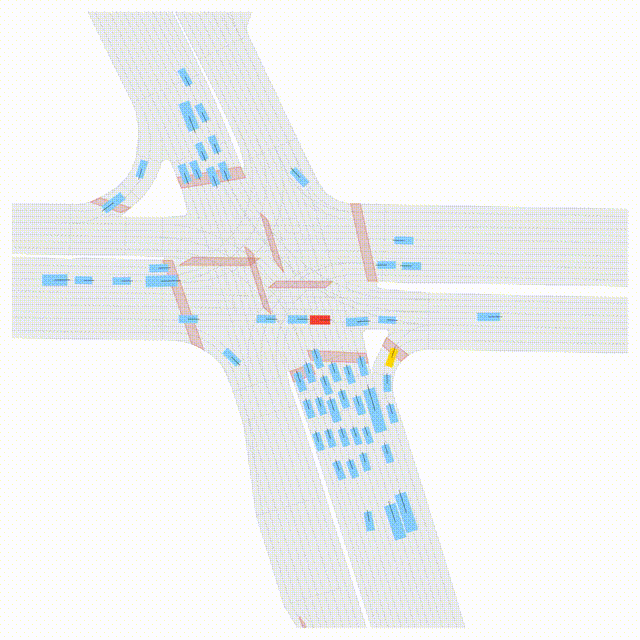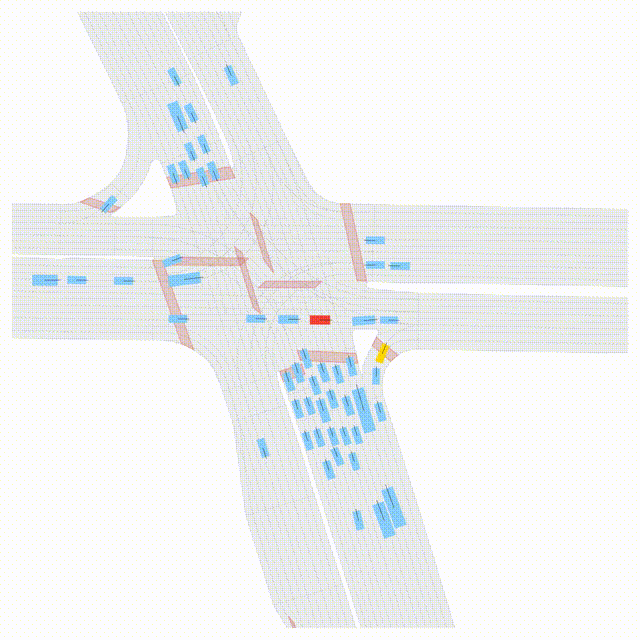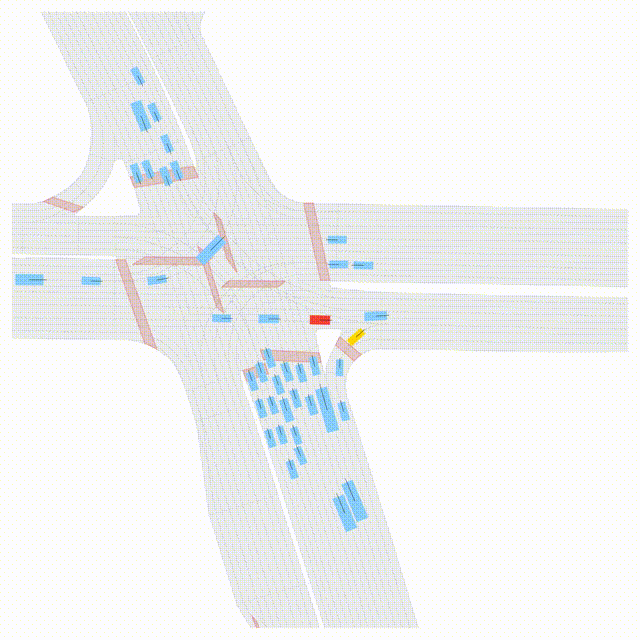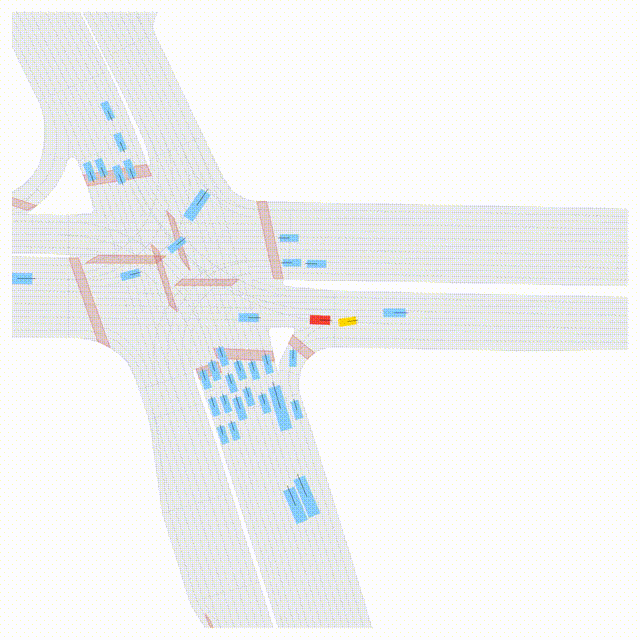
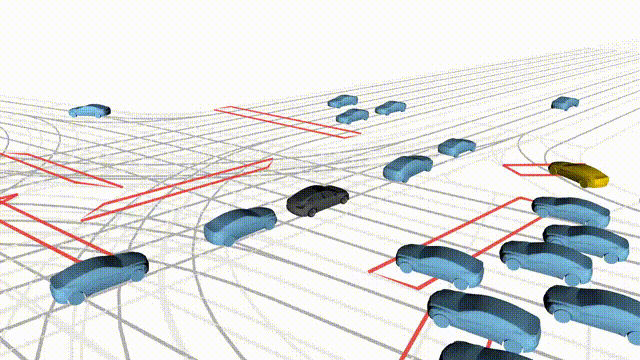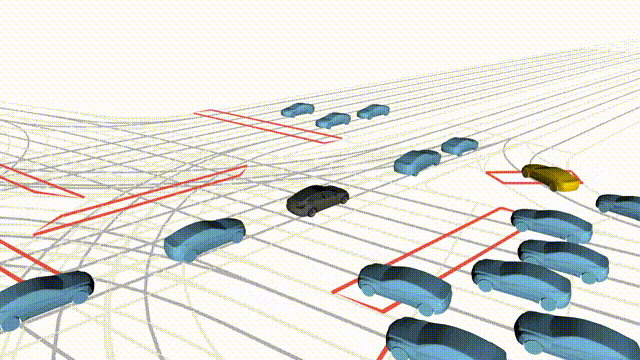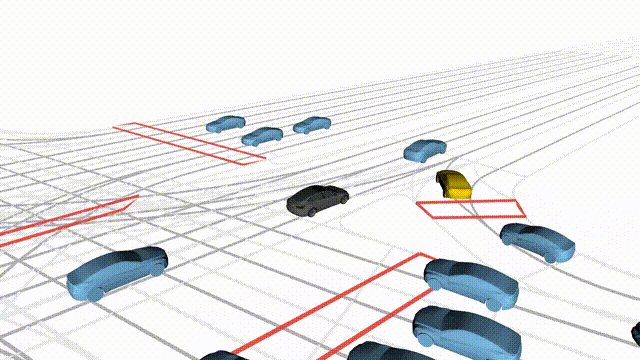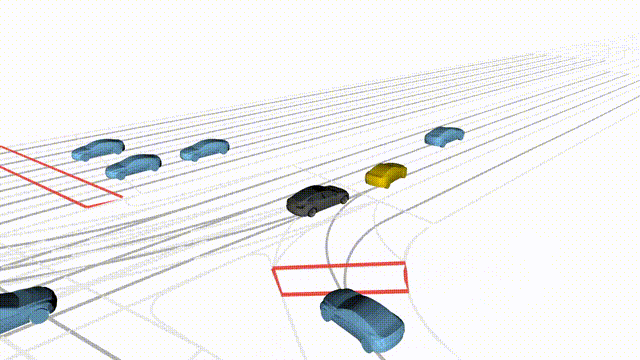
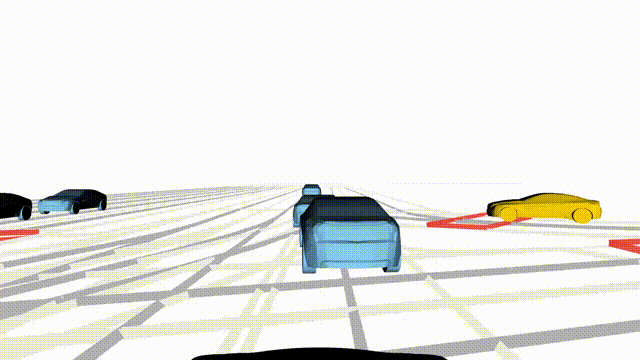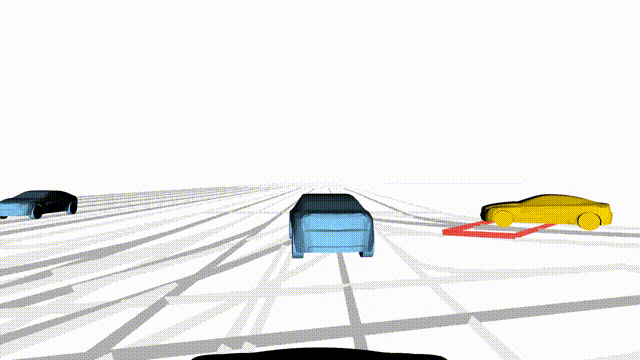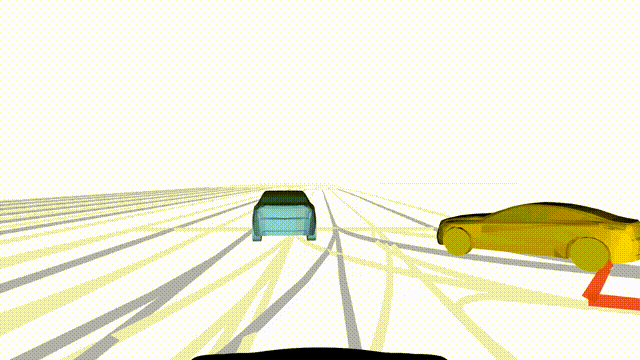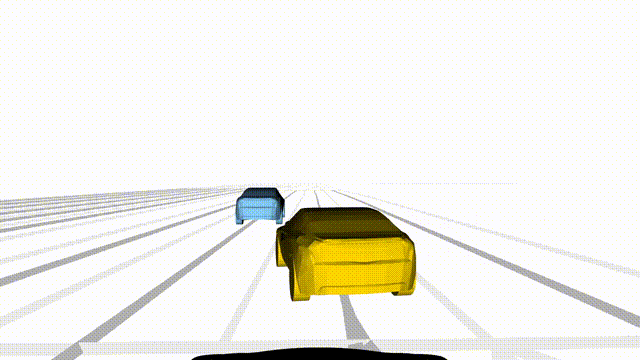
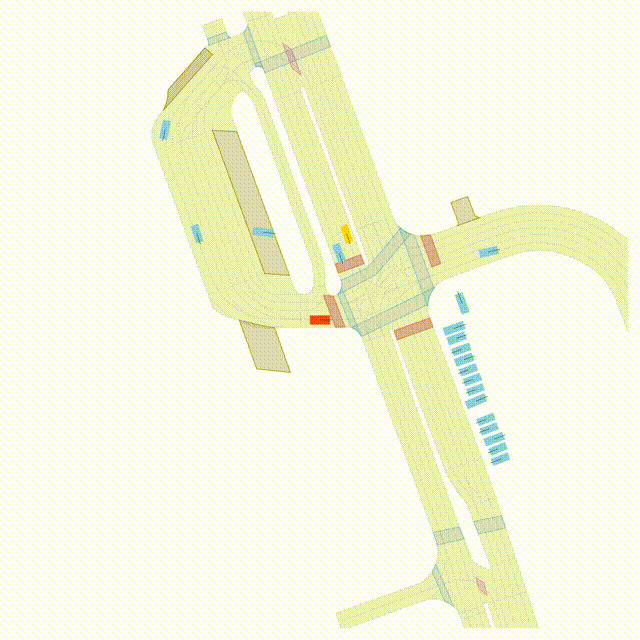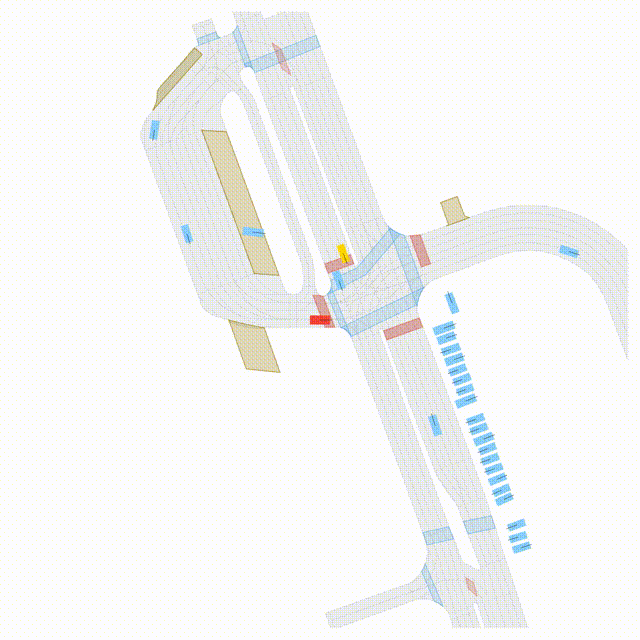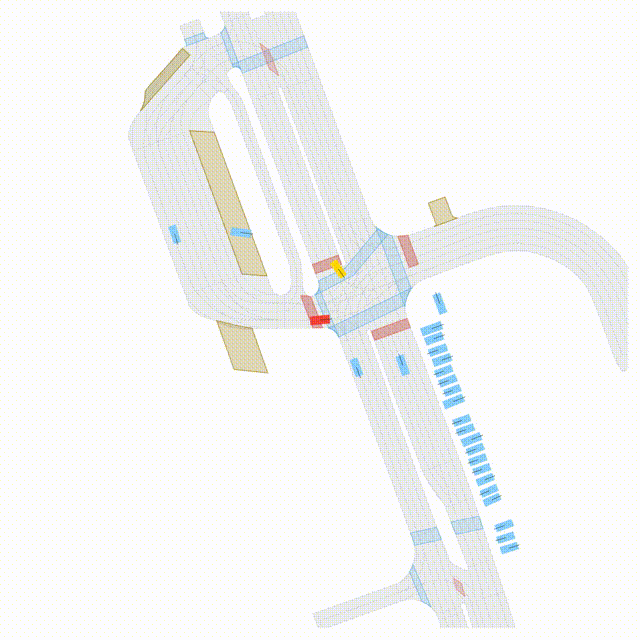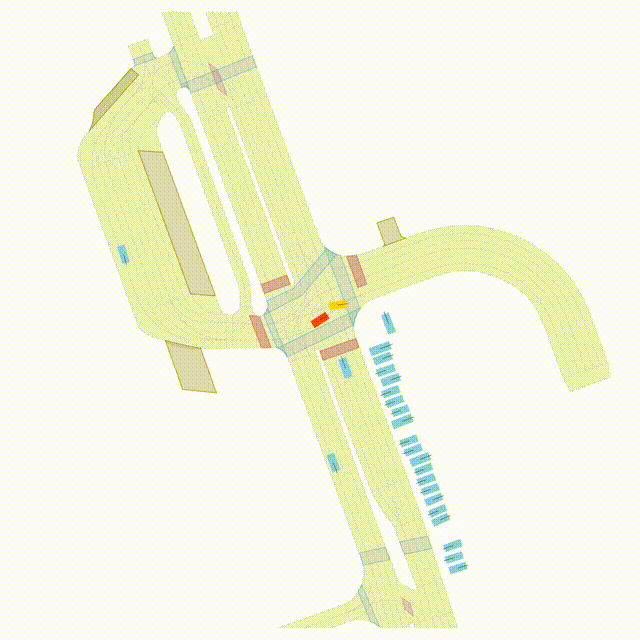
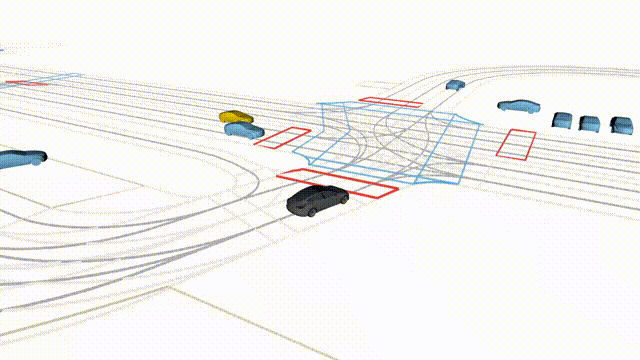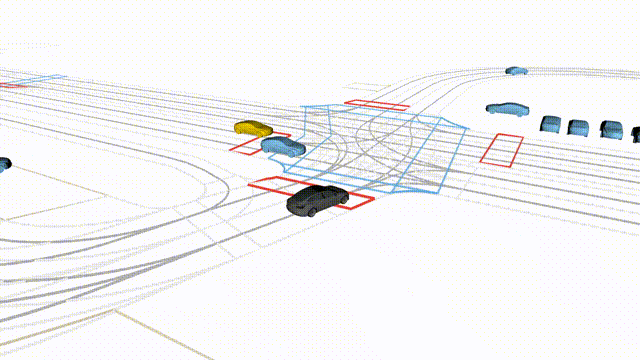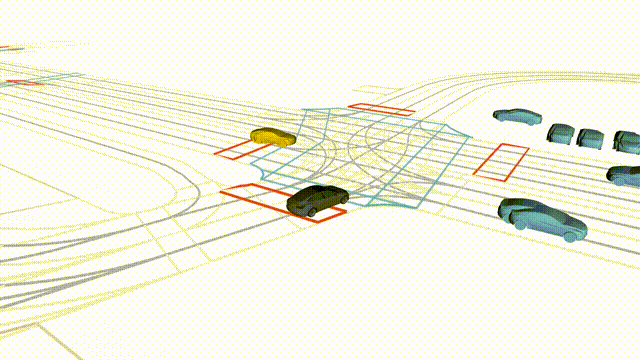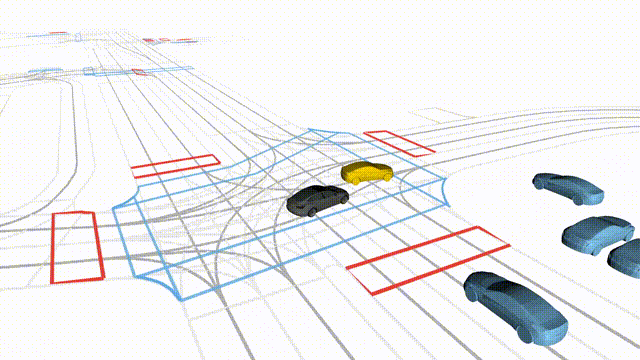
OMEGA (\(\Omega\)).
Our plug-and-play, training-free guidance module can be dropped into existing
diffusion-based driving scene generators to provide
significantly more realistic, controllable, and interactive
traffic scenarios. Color transitions indicate the direction and speed of motion:
ego (red gradient),
attacker (yellow gradient),
and other vehicles (blue gradient).
Top
Our guidance produces diverse and realistic future scenarios from the same historical
initialization, increasing the rate of physically and behaviorally valid scenes on both
the nuPlan benchmark (used during the base model's training) and the Waymo benchmark
(zero-shot deployment) compared to unguided baselines.
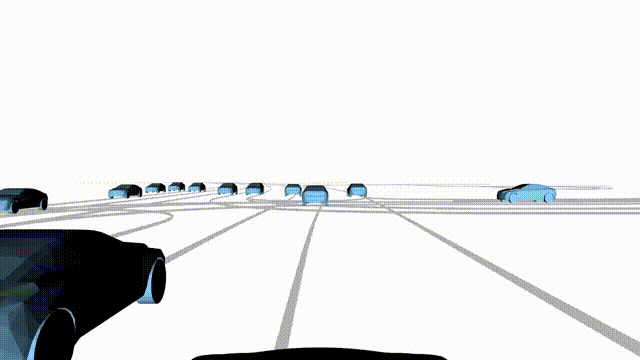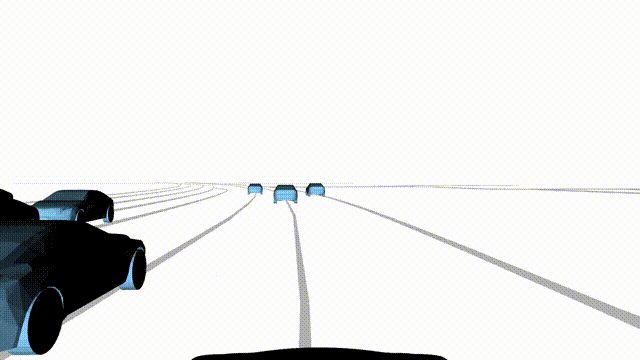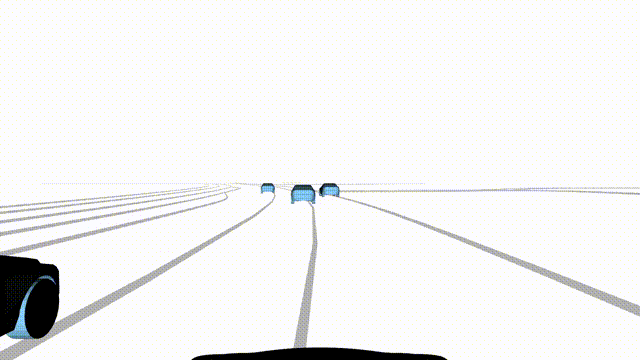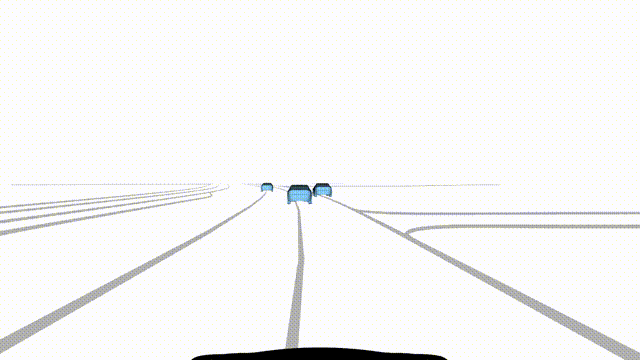
Middle
Controllability-conditioned generation synthesizes scenes where vehicles must reach
predefined goal points (green flags) for one or multiple target agents, achieving precise
behavioral control while maintaining natural interactions.
Bottom
Finally, we enable adversarial scene generation, adaptively producing diverse attack
scenarios without explicitly specifying attacker trajectories.
Abstract
Realistic and diverse multi-agent driving scenes are crucial for evaluating autonomous vehicles, but safety-critical events which are essential for this task are rare and underrepresented in driving datasets. Data-driven scene generation offers a low-cost alternative by synthesizing complex traffic behaviors from existing driving logs. However, existing models often lack controllability or yield samples that violate physical or social constraints, limiting their usability. We present OMEGA, an optimization-guided, training-free framework that enforces structural consistency and interaction awareness during diffusion-based sampling from a scene generation model. OMEGA re-anchors each reverse diffusion step via constrained optimization, steering the generation towards physically plausible and behaviorally coherent trajectories. Building on this framework, we formulate ego-attacker interactions as a game-theoretic optimization in the distribution space, approximating Nash equilibria to generate realistic, safety-critical adversarial scenarios. Experiments on nuPlan and Waymo show that OMEGA improves generation realism, consistency, and controllability, increasing the ratio of physically and behaviorally valid scenes from 32.35% to 72.27% for free exploration capabilities, and from 11% to 80% for controllability-focused generation. Our approach can also generate \(5\times\) more near-collision frames with a time-to-collision under three seconds while maintaining the overall scene realism.
Method
Standard diffusion sampling (top) vs. our optimization-guided OMEGA (bottom).
OMEGA re-anchors each reverse diffusion step using constrained optimization
within a KL-bounded trust region, steering sampling toward physically consistent
and behaviorally coherent scenes.
Two-phase noise scheduling.
Warmup reduces noise along full trajectories to establish macro-level layout and agent-wise dynamic plausibility, minimizing drift and stabilizing long-horizon trends. Rolling-Zero then performs fine-grained, time-indexed denoising with residual-noise updates that incorporate environmental feedback, improving reactivity and yielding structurally feasible, responsive multi-agent scenes.
Key Contributions✨
⚓ Optimization-guided diffusion sampling.
A plug-and-play, training-free method that re-anchors each reverse step via constrained optimization, enforcing structural consistency and stable diffusion guidance.
🕐 Two-phase noise scheduling.
A coarse-to-fine denoising strategy for interaction fidelity, ensuring macro-level plausibility with fine-grained reactivity, enabling context-aware and dynamically coordinated multi-agent scene evolution.
♟️ OMEGAAdv.
A game-thoretic formulation that models ego-attacker interactions as a distributional optimization game, enabling the adaptive generation of realistic yet challenging driving scenarios.
Video Results
Click any GIF to view in full resolution. (Click outside / press Esc to close.)
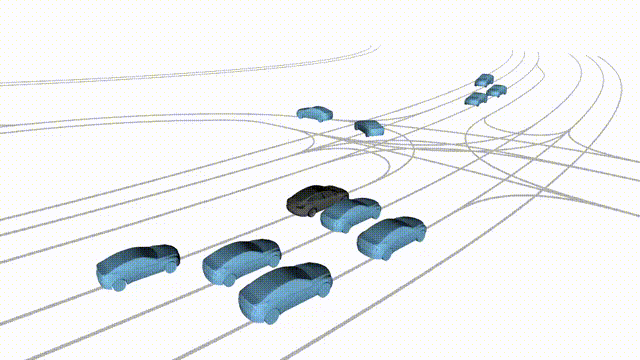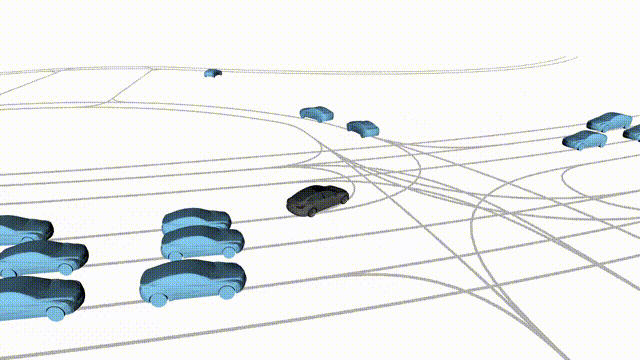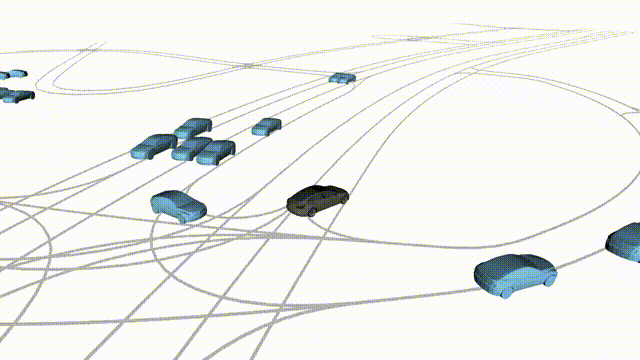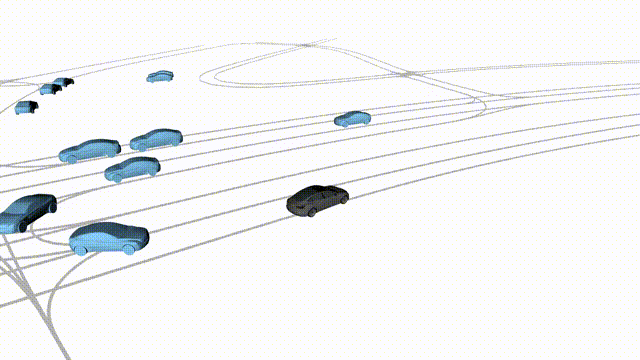
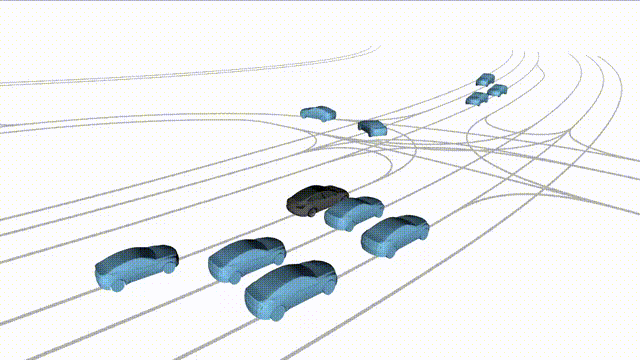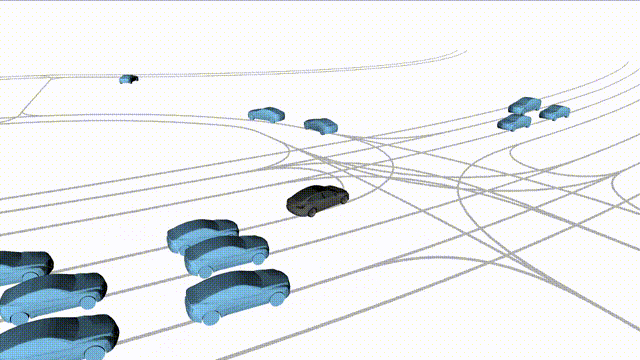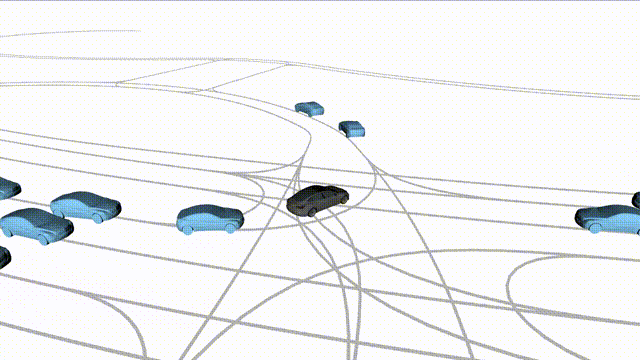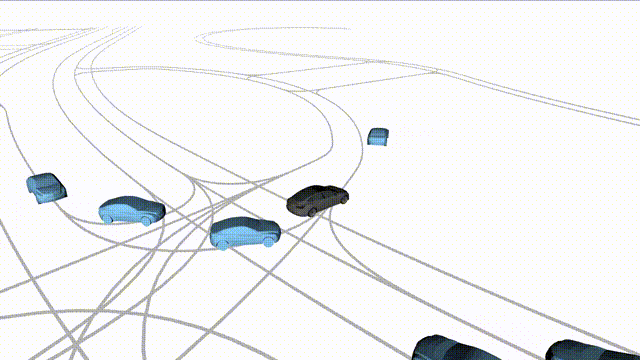
Free Exploration on nuPlan
Scenes 1-2: Two rollouts sampled from the same initial scene, resulting in different future trajectories.
Scenes 3-4: Additional rollouts from distinct nuPlan scenarios.
In the BEV view, the ego vehicle is shown in red;
in the three camera-centric views, the ego vehicle appears in black.
Surrounding agents are consistently rendered in blue.
Scene 1 (Run A)
Same init, different sample
Bird’s-eye
Axonometric
Front
Rear
Idle
Loading
Scene 2 (Run B)
Same init, different sample
Bird’s-eye
Axonometric
Front
Rear
Idle
Loading
Scene 3
Different scenario
Bird’s-eye
Axonometric
Front
Rear
Idle
Loading
Scene 4
Different scenario
Bird’s-eye
Axonometric
Front
Rear
Idle
Loading
Zero-Shot Free Exploration on Waymo
Scenes 1-2: Two rollouts sampled from the same initial scene, resulting in different future trajectories.
Scenes 3-4: Additional rollouts from distinct Waymo scenarios.
In the BEV view, the ego vehicle is shown in red;
in the three camera-centric views, the ego vehicle appears in black.
Surrounding agents are consistently rendered in blue.
Scene 1 (Run A)
Same init, different sample
Bird’s-eye
Axonometric
Front
Rear
Idle
Loading
Scene 2 (Run B)
Same init, different sample
Bird’s-eye
Axonometric
Front
Rear
Idle
Loading
Scene 3
Different scenario
Bird’s-eye
Axonometric
Front
Rear
Idle
Loading
Scene 4
Different scenario
Bird’s-eye
Axonometric
Front
Rear
Idle
Loading
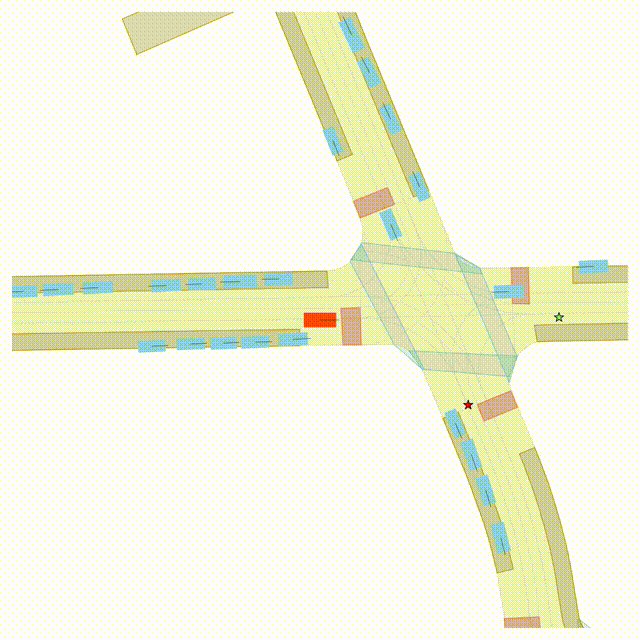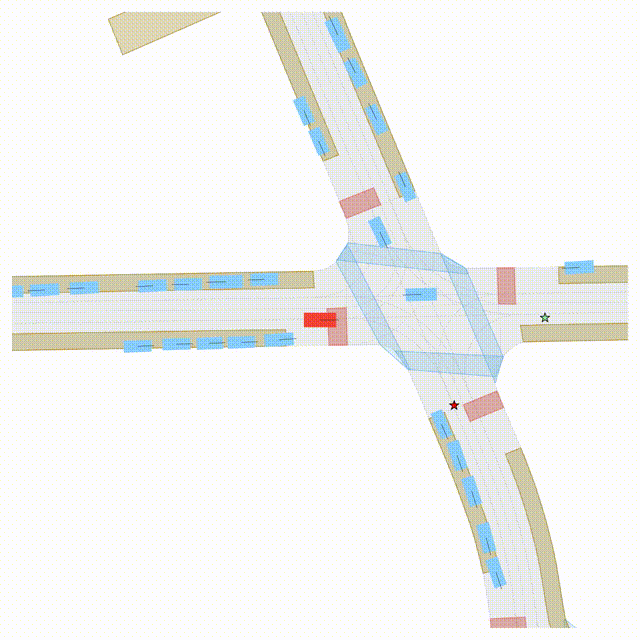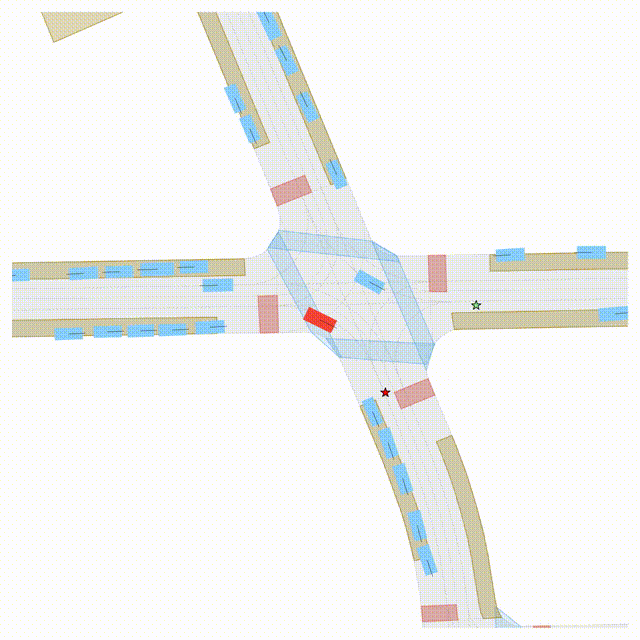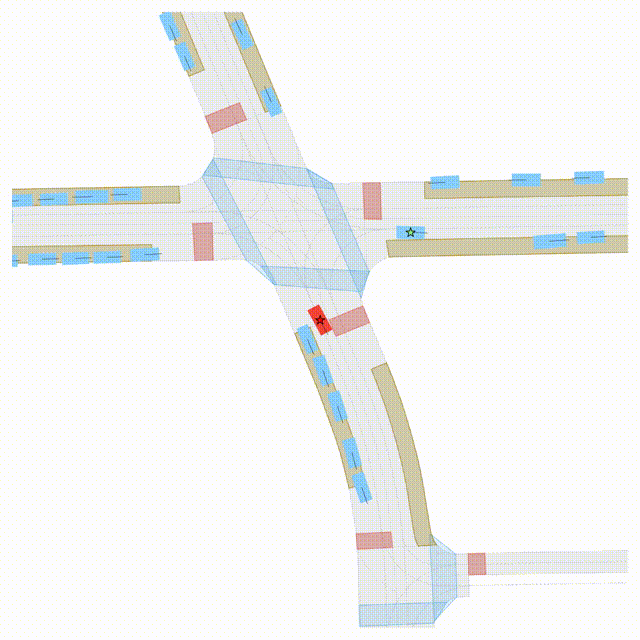
Goal-Conditioned Controllability
Scenes 1–2: A paired rollout from the same scene, produced by specifying different goal points for the ego and selected agents.
Scenes 3–4: Another paired rollout under a different scene initialization, with alternative goal specifications.
In the BEV view, the ego vehicle is shown in red;
in the three camera-centric views, the ego vehicle appears in black.
Surrounding agents are consistently rendered in blue.
Goal markers: red stars/dots indicate the ego goal, and green stars/dots indicate agent goals.
Scene 1
Same init, different goals
Bird’s-eye
Axonometric
Front
Rear
Idle
Loading
Scene 2
Same init, different goals
Bird’s-eye
Axonometric
Front
Rear
Idle
Loading
Scene 3
Same init, different goals
Bird’s-eye
Axonometric
Front
Rear
Idle
Loading
Scene 4
Same init, different goals
Bird’s-eye
Axonometric
Front
Rear
Idle
Loading
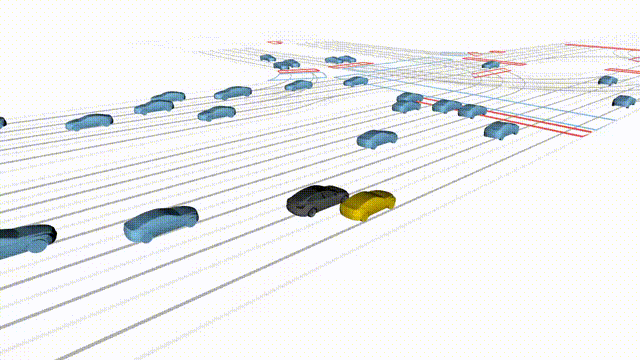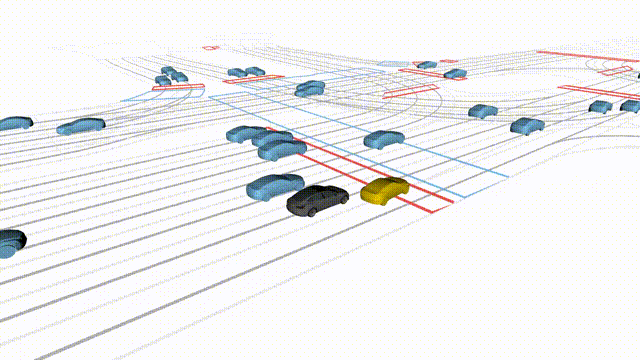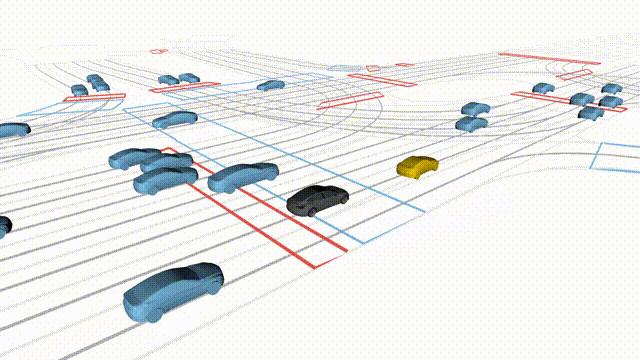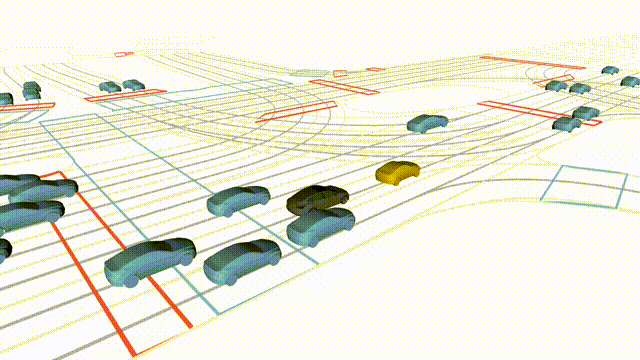
Adversarial Scene Generation
Adversarial scenes generated by adapting to different attacker relative positions, resulting in diverse interaction outcomes
(e.g., Lane Intrusion, Hard Brake, Forced Merge, and Cross-Traffic Encroachment).
In the BEV view, the ego vehicle is shown in red;
in the three camera-centric views, the ego vehicle appears in black.
Surrounding agents are rendered in blue,
while the attacking vehicle is highlighted in yellow.
Scene 1
Lane Intrusion
Bird’s-eye
Axonometric
Front
Rear
Idle
Loading
Scene 2
Hard Brake
Bird’s-eye
Axonometric
Front
Rear
Idle
Loading
Scene 3
Forced Merge
Bird’s-eye
Axonometric
Front
Rear
Idle
Loading
Scene 4
Cross-Traffic Encroachment
Bird’s-eye
Axonometric
Front
Rear
Idle
Loading
Click outside / press Esc to close
Quantitative Results
Free Exploration
Free-exploration scene generation on nuPlan and zero-shot evaluation on Waymo.
Oracle denotes the original logged data. We report N-Dist (JSD of nearest-agent distance, \(\times 10^{-3}\)),
L-Dev (lateral deviation JSD, \(\times 10^{-3}\)), A-Dev (angular deviation JSD, \(\times 10^{-3}\)),
Spd (speed JSD, \(\times 10^{-3}\)), per-agent / per-scene validity (P-Ag. / P-Sc.),
and overall scene valid rate (no collision / off-road / kinematic violation).
Arrows \(\downarrow\) / \(\uparrow\) indicate lower / higher is better.
Goal-Conditioned Controllability
Controllability under user-specified intents.
Each method is evaluated by assigning multiple user-defined goal points to the target vehicle
and measuring whether it can reliably reach these goals while maintaining scene realism and validity.
Adversarial Scene Generation
Adversarial scene generation with ego–attacker interactions.
We compare ground truth (Oracle), Nexus variants finetuned or guided for attacking behavior:
Nexus-FT (finetuned on adversarial scenarios), Nexus-GC (goal-attacking conditioning), and
Nexus-CTG\(_\mathrm{Adv}\) (cost-based attacking with CTG). Please refer to the supplementary material for details.
We report ego risk metrics (mean time-to-collision per frame, TTC [s], and the percentage of frames with
\(\mathrm{TTC} < 1,2,3\,\mathrm{s}\)), motion intensity (mean acceleration [\(\mathrm{m^2/s}\)] and jerk [\(\mathrm{m^3/s}\)]),
and ego non-responsible collision rate (Ego NC, \%).
Right: Nexus-\(\Omega_\mathrm{Adv}\) produces more low-speed, short-TTC frames, indicating riskier yet realistic scenarios.
More Results
Comparison of Guidance Strategies
Ablation Study
Ego-Kinematic Distributions in Adversarial Scenarios
Joint distributions of ego speed with TTC, acceleration, jerk, and yaw rate are shown for
ground truth, Nexus, and Nexus-\(\Omega_{\mathrm{Adv}}\).
Marginal histograms use a logarithmic scale to highlight rare events.
Nexus-\(\Omega_{\mathrm{Adv}}\) produces more short-TTC frames, shifts ego speeds toward lower and medium ranges,
and broadens acceleration and jerk distributions, indicating stronger adversarial effects on ego motion.
More Qualitative Results
Click any image to view in full resolution.
nuPlan
Free Exploration
Top: Multiple inference runs from the same initial scene yield diverse future evolutions.
Bottom: Additional scenarios illustrating broad variation in free exploration.
Waymo (Zero-shot)
Free Exploration
Top: Zero-shot rollouts on Waymo produce diverse future evolutions.
Bottom: Additional scenarios demonstrating strong cross-domain generalization.
nuPlan
Goal-Conditioned Generation
Top: Different goal points yield diverse but consistent goal-directed behaviors.
Bottom: Additional cases showing controllable, coherent multi-agent outcomes.
nuPlan
Adversarial Generation
Top: Different attacker identities generate distinct adversarial outcomes.
Bottom: Nexus-ΩAdv adapts to attacker positions and produces plausible attack behaviors.
Ecosystem
This work is part of a broader research program at
OpenDriveLab focusing on
large-scale simulation, scene generation, behavior modeling, and end-to-end training for autonomous driving.
If you find the project helpful for your research, please consider citing our paper:
@article{li2025optimization,
title={Optimization-Guided Diffusion for Interactive Scene Generation},
author={Li, Shiaho and Ye, Naisheng and Li, Tianyu and Chitta, Kashyap and An, Tuo and Su, Peng and Wang, Boyang and Liu, Haiou and Lv, Chen and Li, Hongyang},
journal={arXiv preprint arXiv:2512.07661},
year={2025}
}