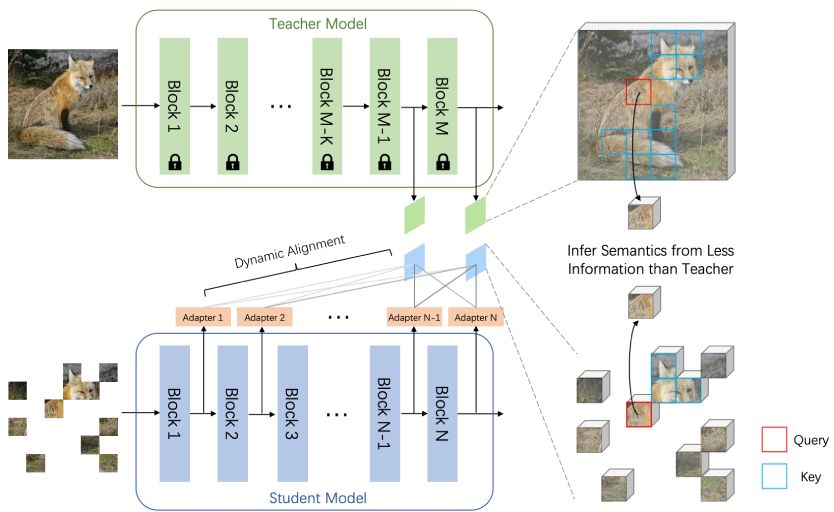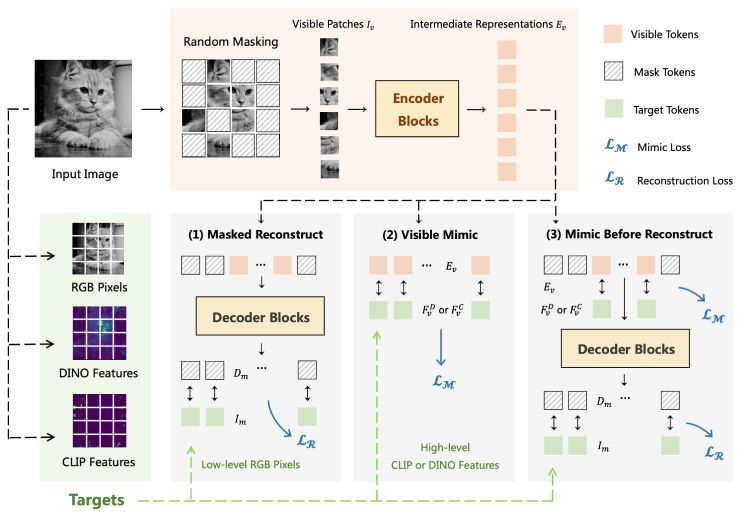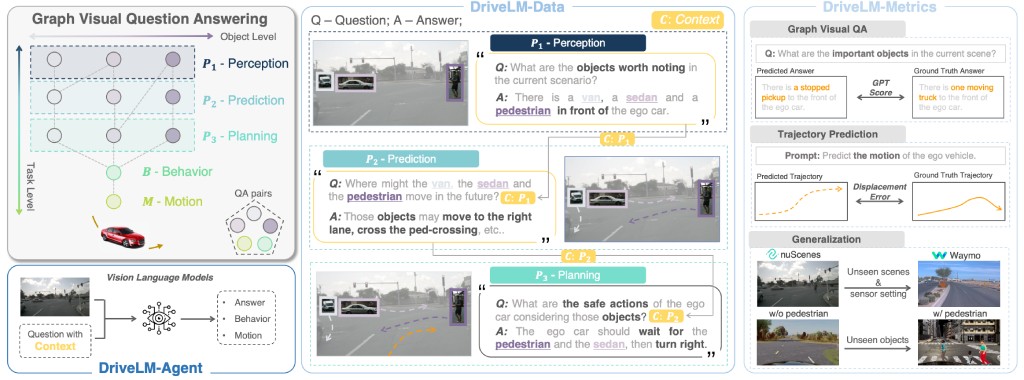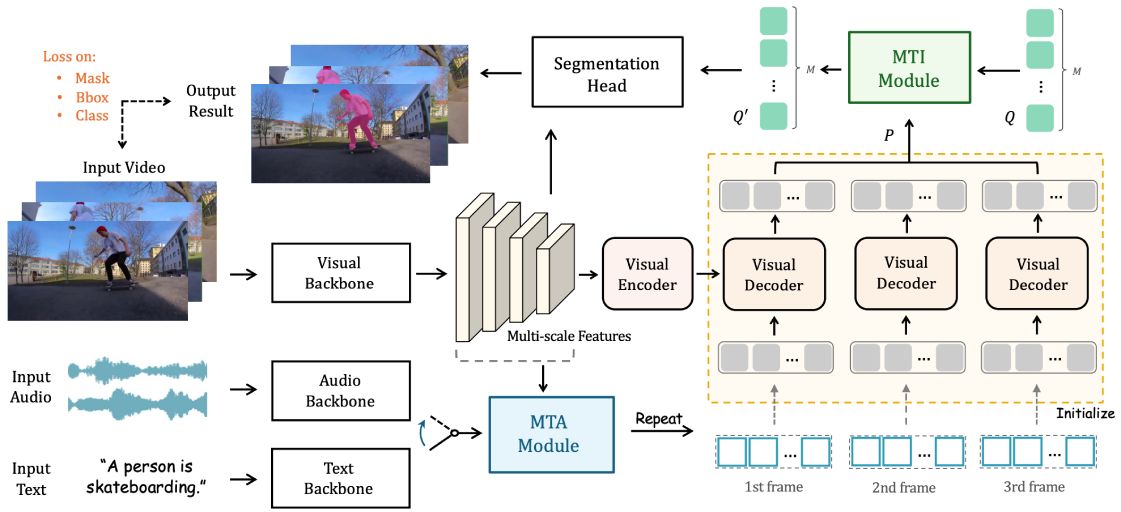
[nuScenes First Place] [Waymo Challenge 2022 First Place]




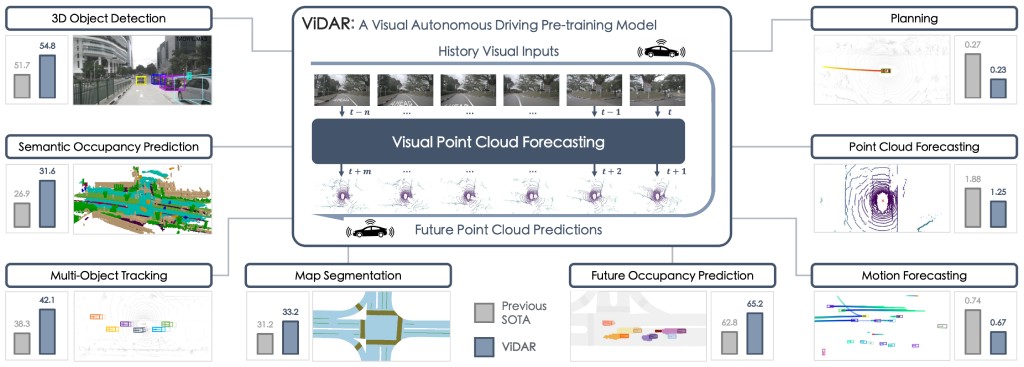

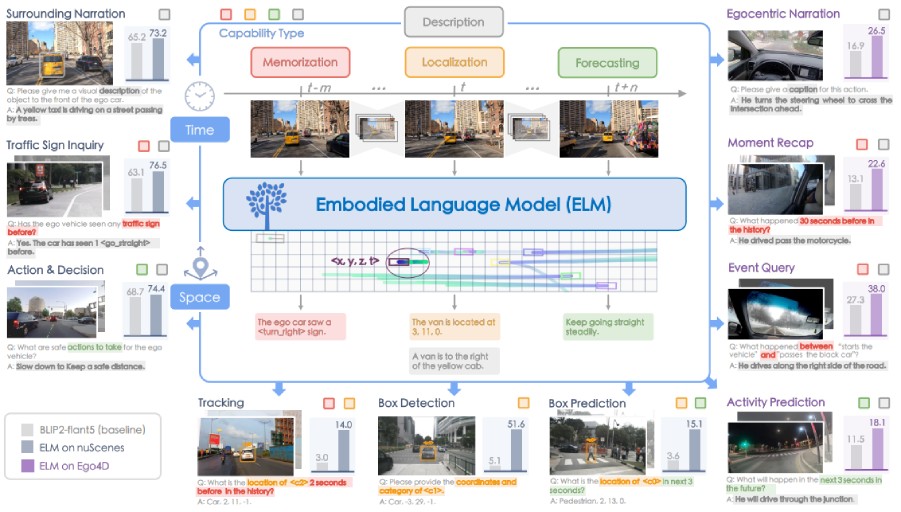

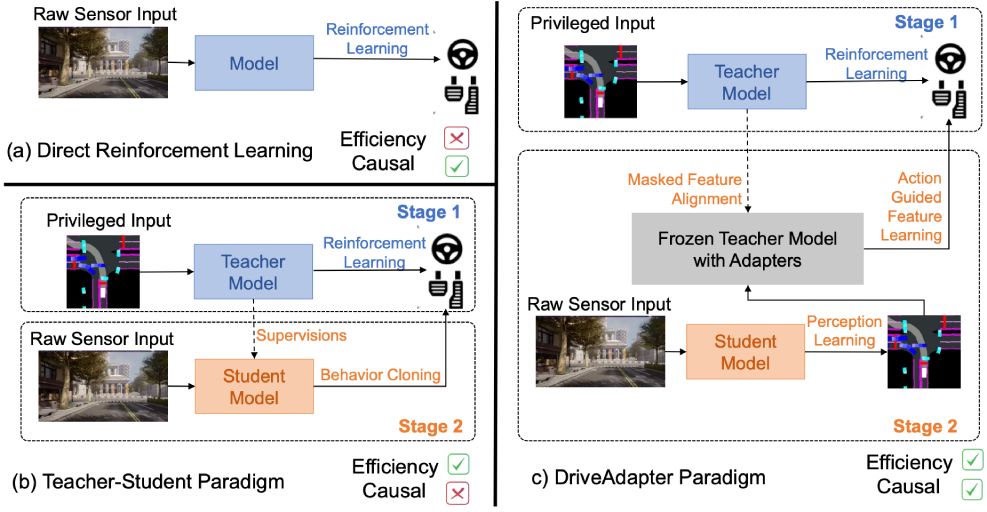

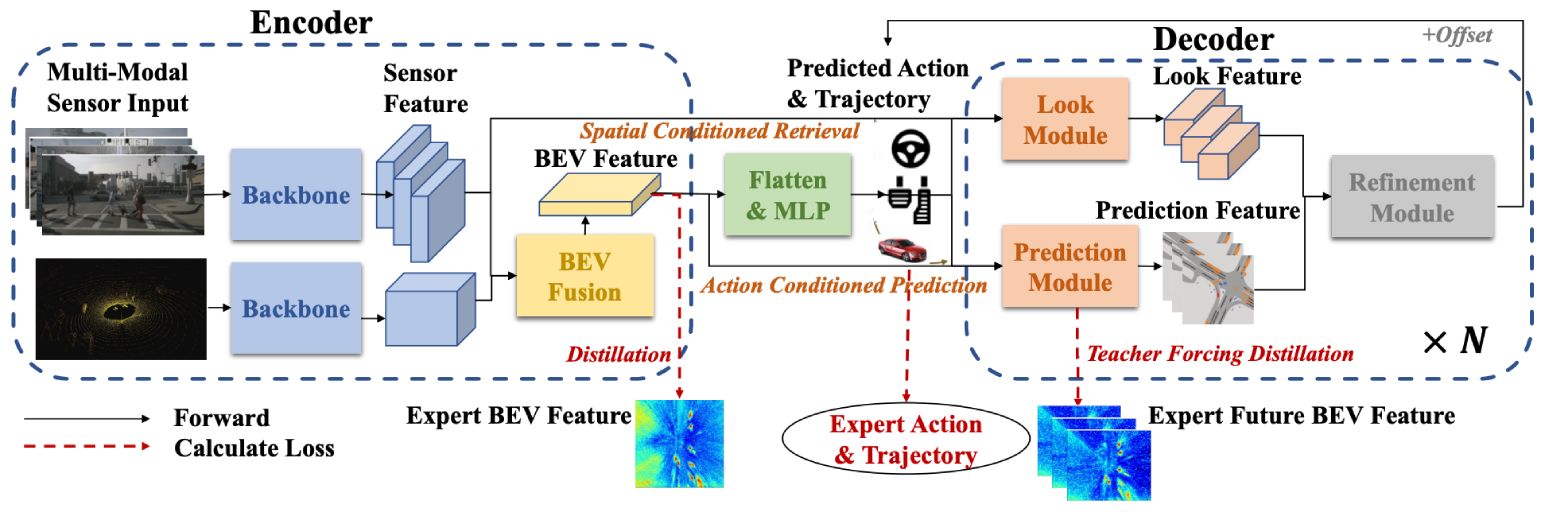

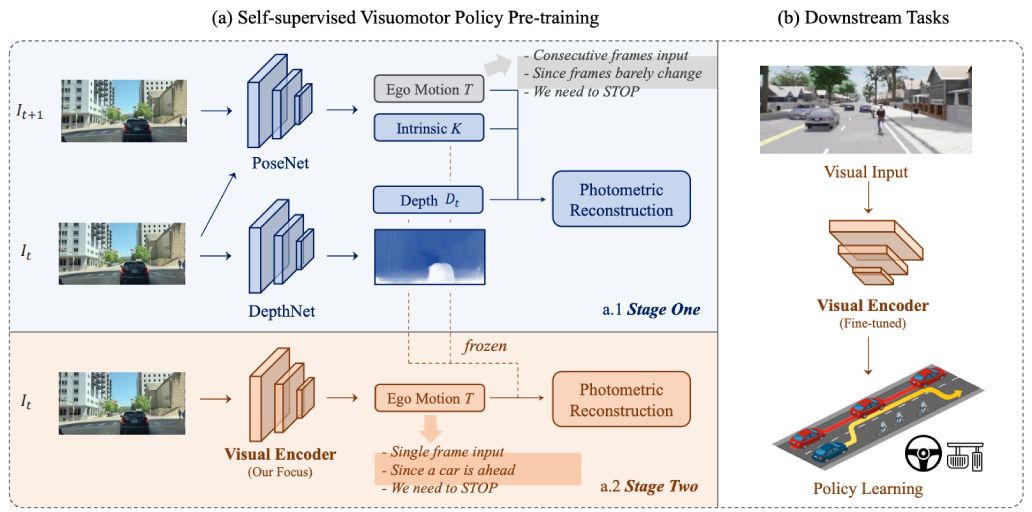

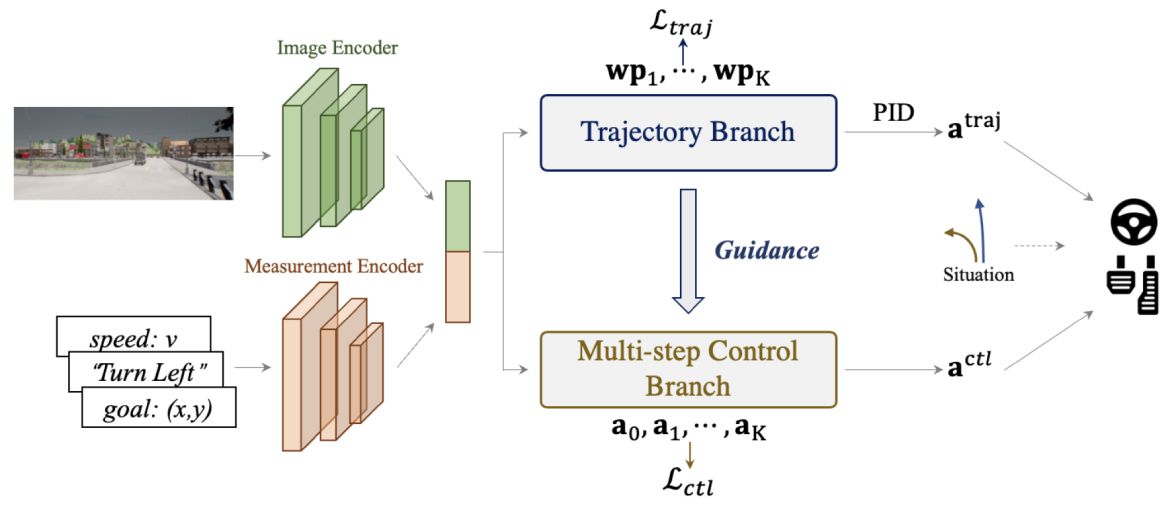
[Carla First Place]

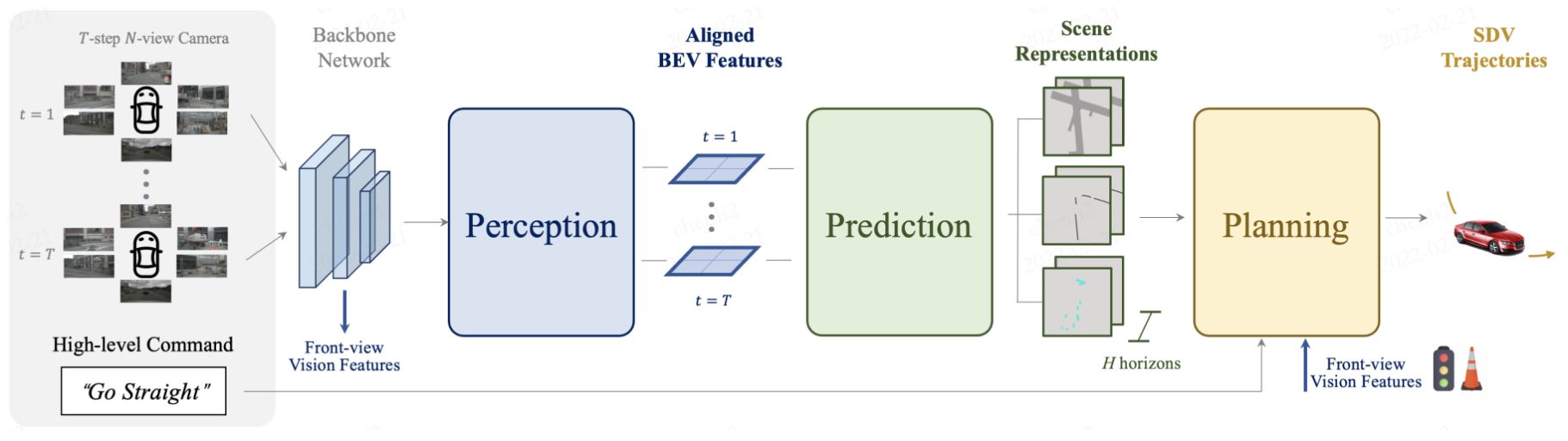

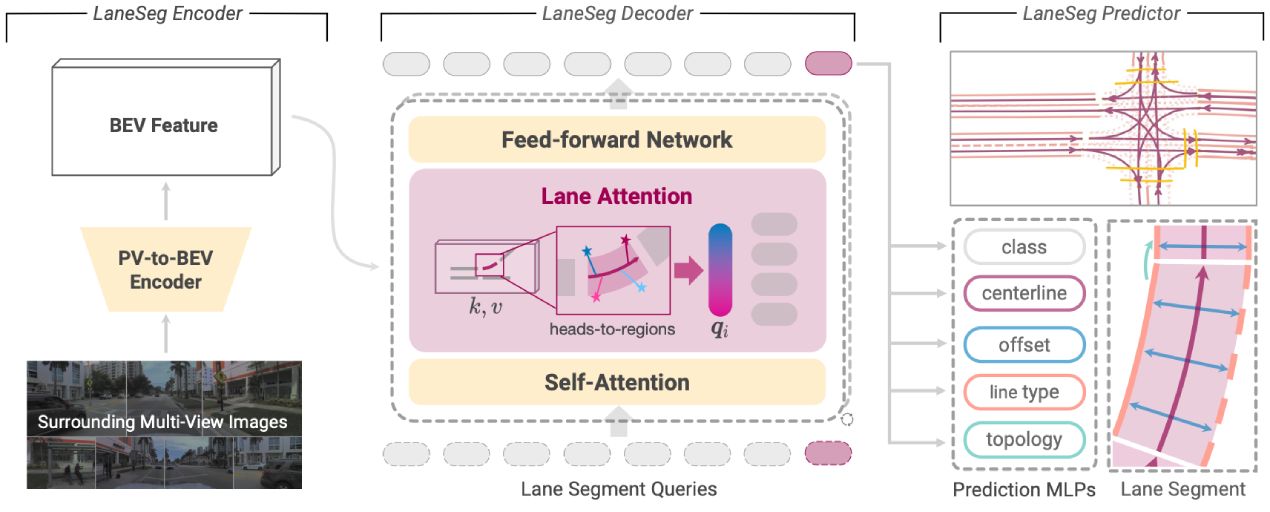

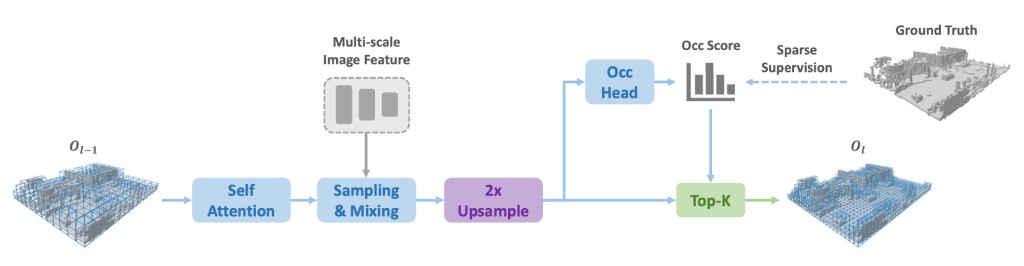

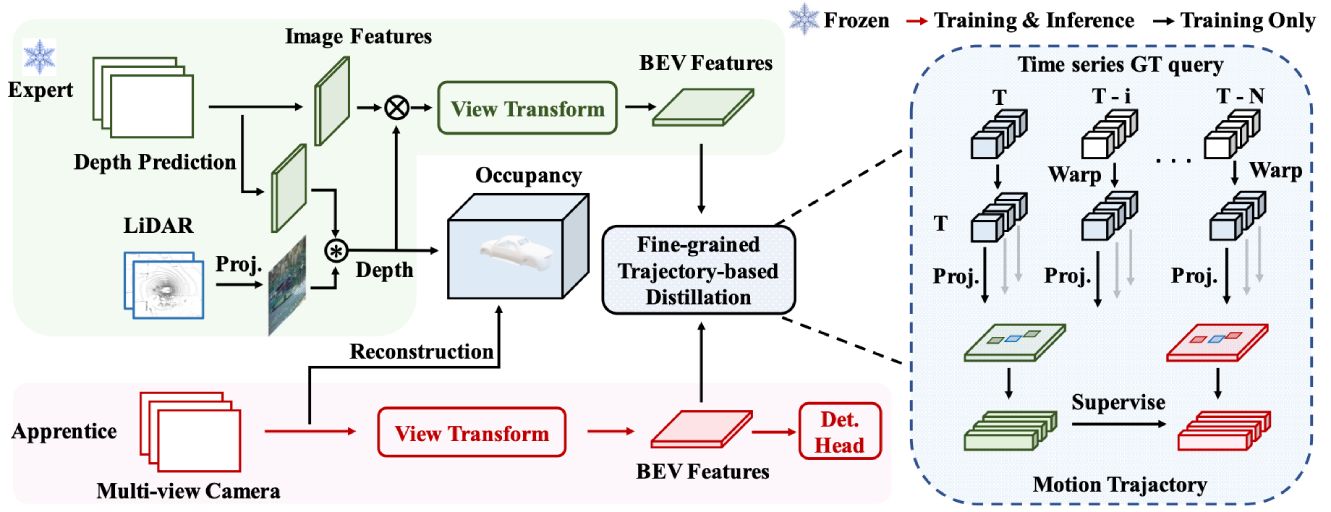

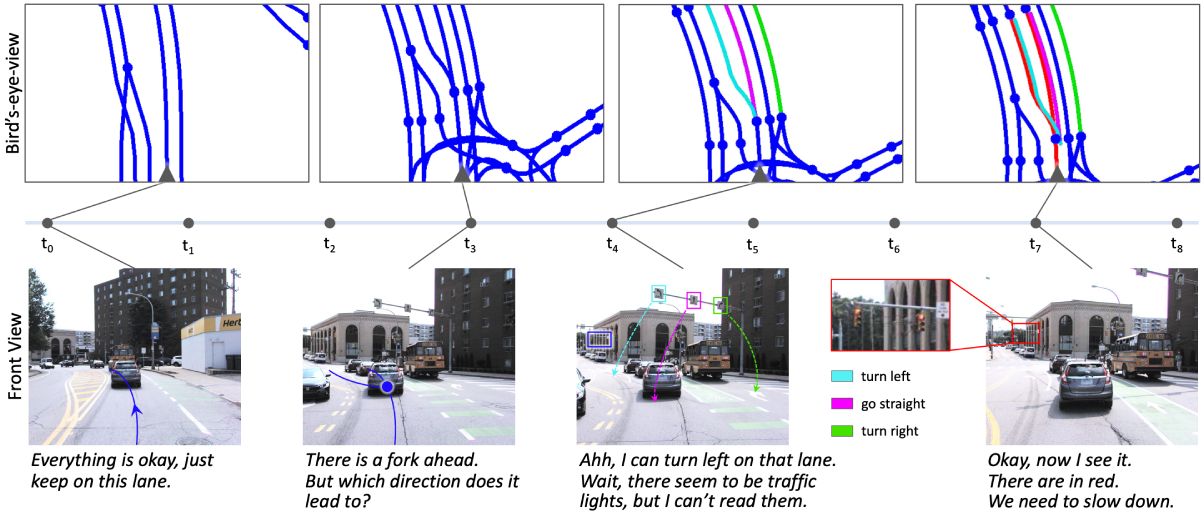

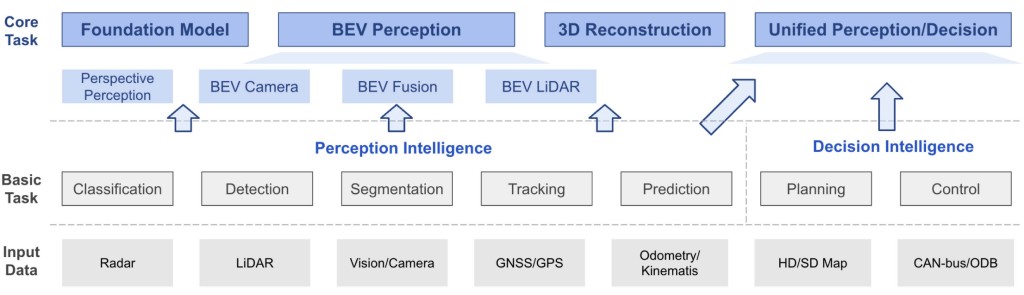
[Setup the Table]

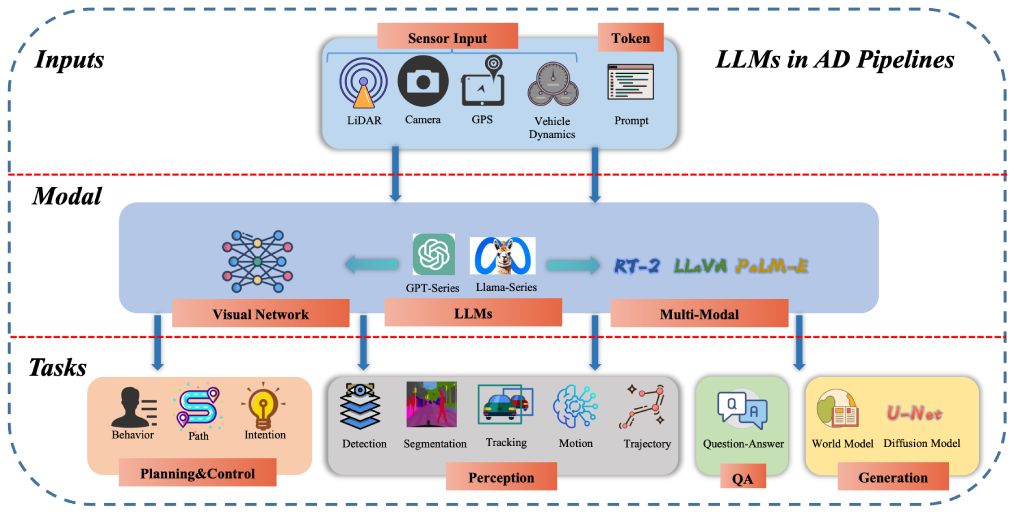

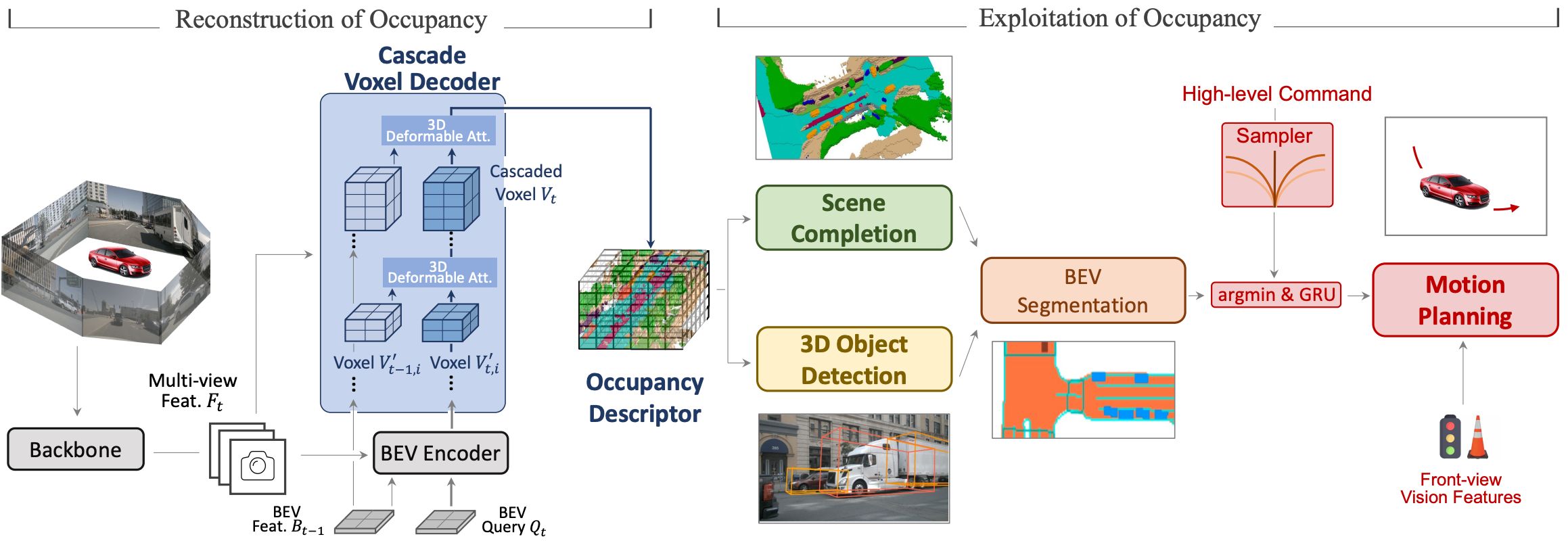

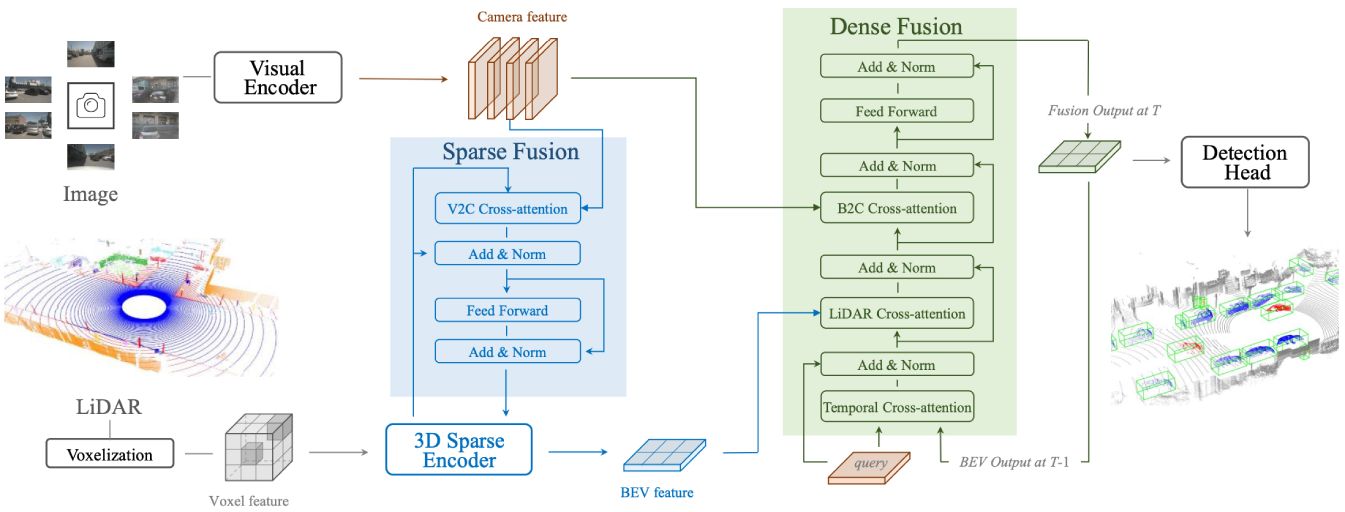
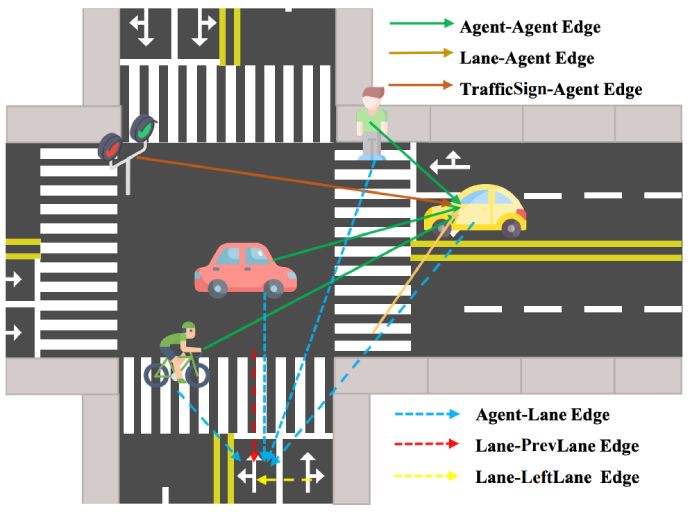

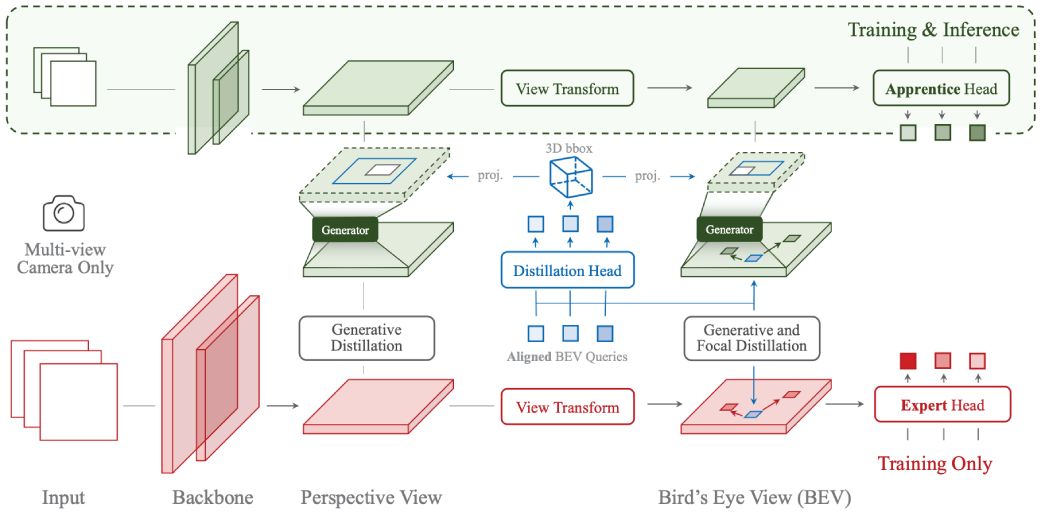
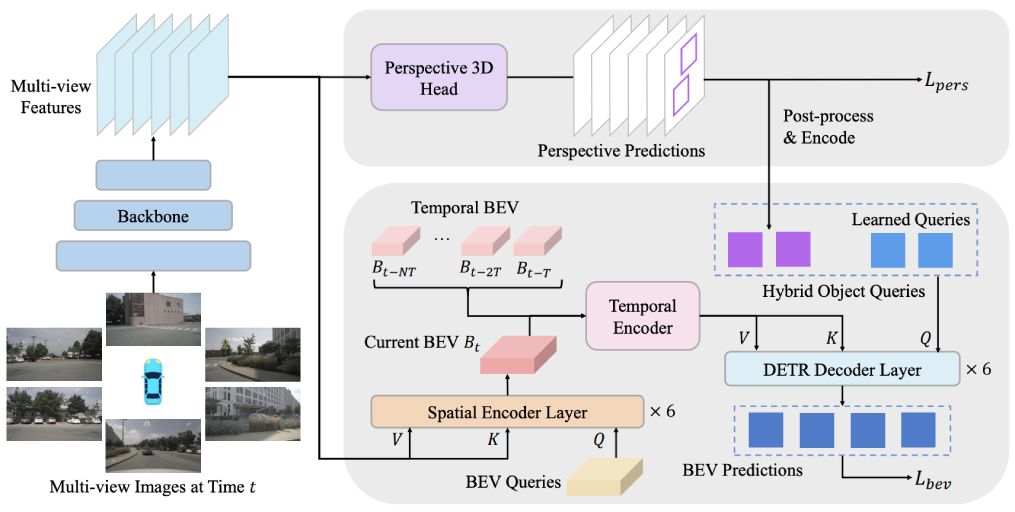
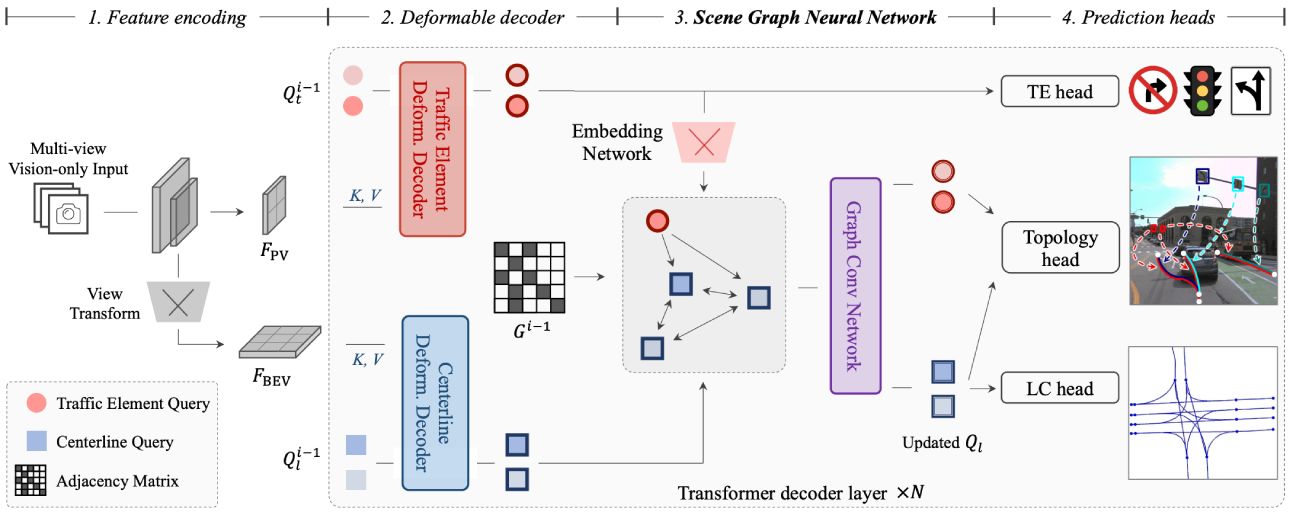

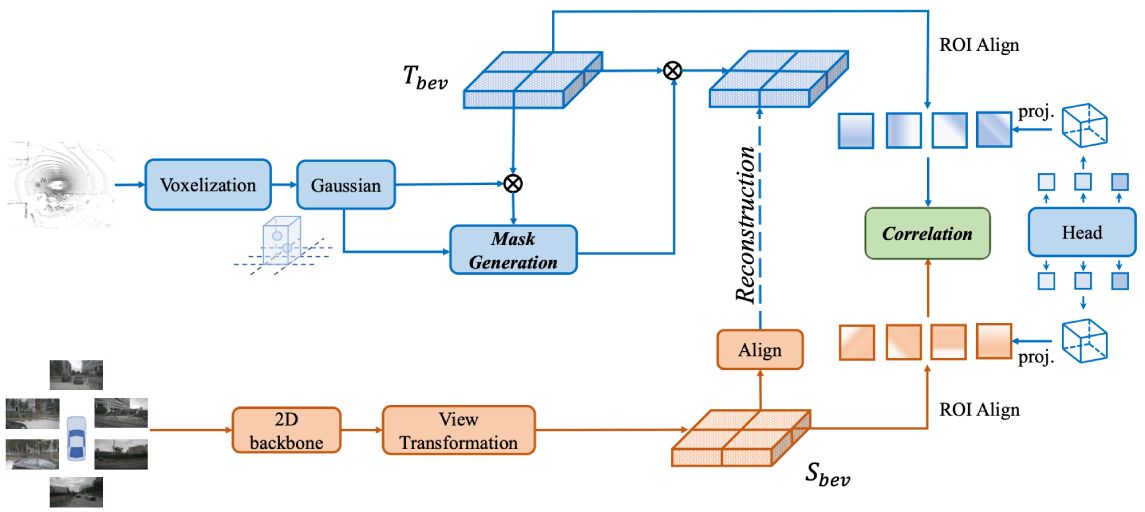
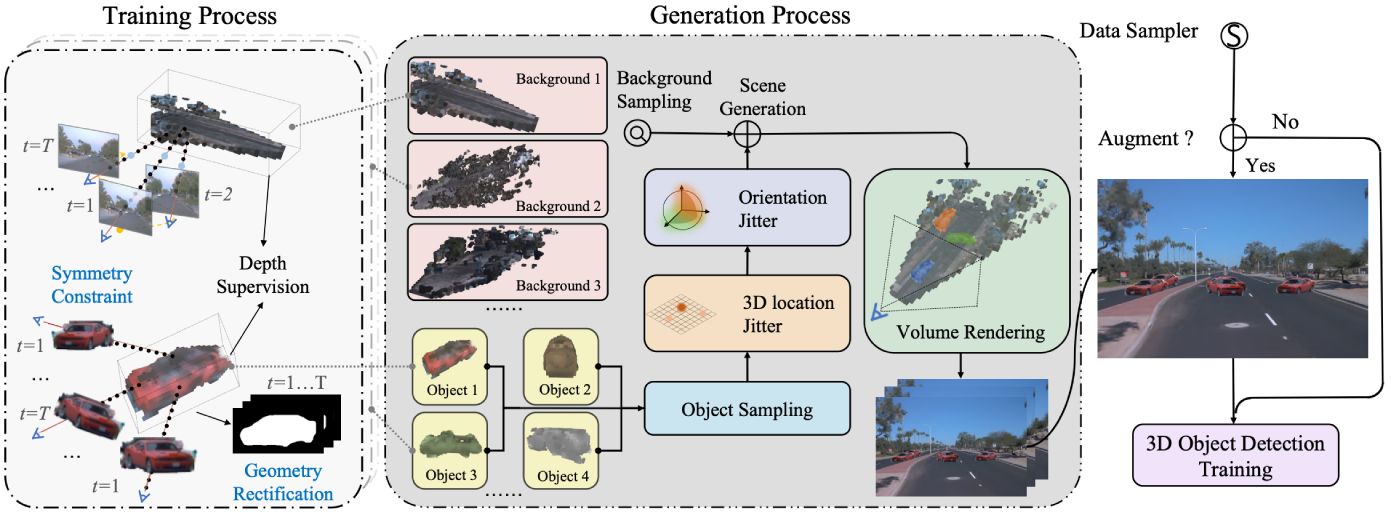
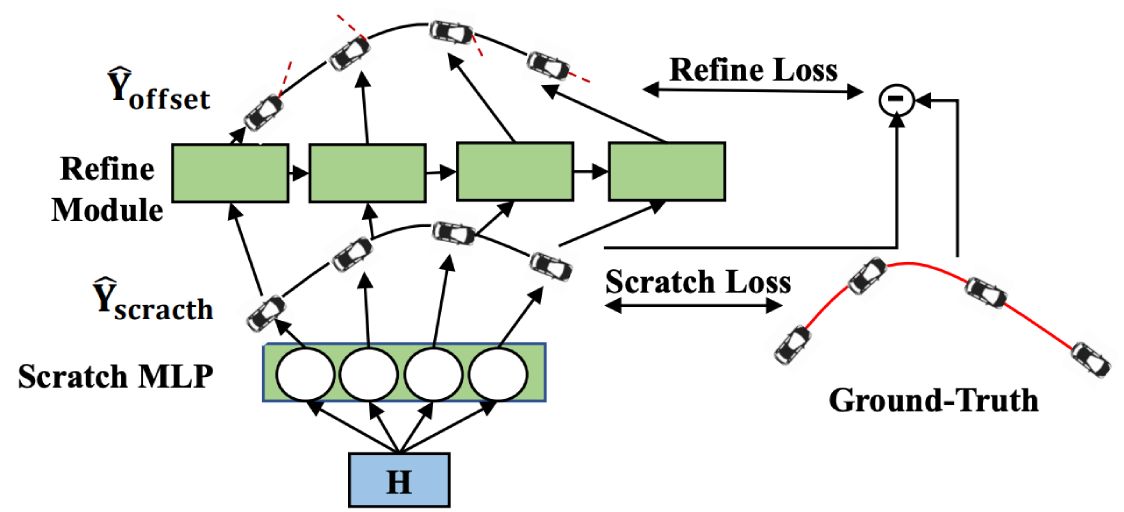
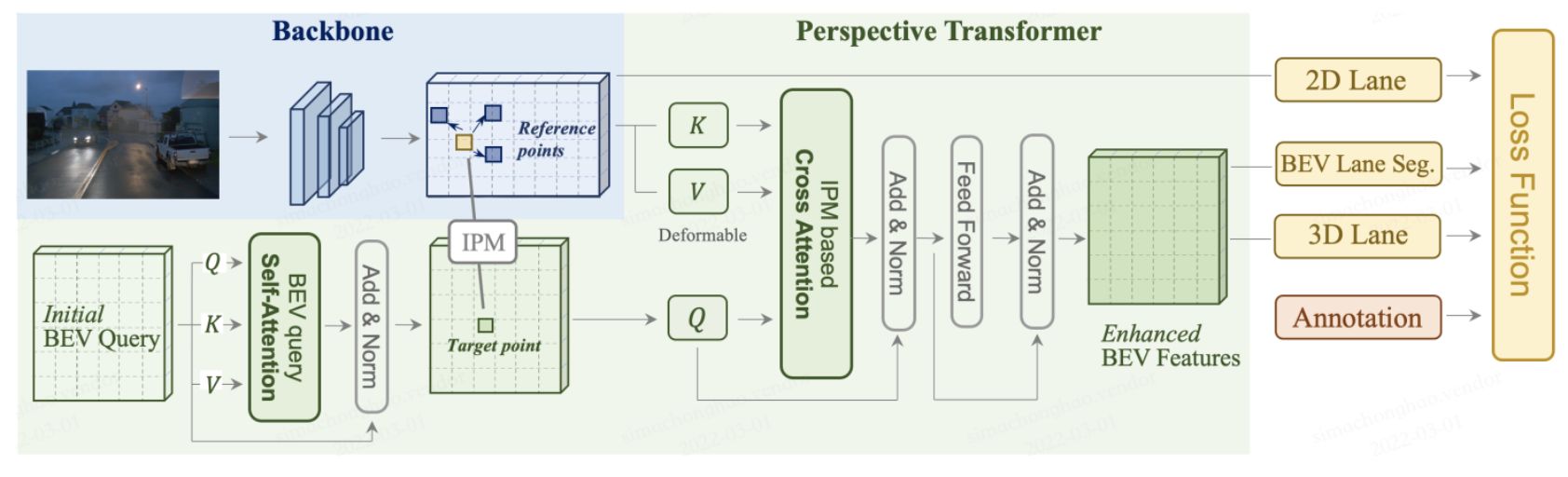
[Redefine the Community]