World's first less-than-1-meter-level accurate humanoid soccer shooting policy in general cases.
Single human reference, learn to track, then deviate and adapt.


Elite humanoid soccer shooting requires whole-body stability, high-impulse whole-body interactions, and accuracy to targets. Motion tracking-driven reinforcement learning (RL) provides stability in whole-body movement coordination, but a fixed reference makes it hard to adapt to varied ball positions and strike timings; in contrast, task reward-driven RL struggles to explore and discover valid kicks from scratch. We therefore introduce RoboNaldo, a three-stage motion-guided curriculum RL framework for high-impulse humanoid interaction. A single human-kick reference is used as a scaffold and progressively shifts optimization towards shooting performance. The curriculum first learns a stable whole-body kicking prior, then adapts the kick to free-kick settings where the ball is stationary at random positions, and finally extends it to moving-ball shooting through a locomotion-command and kick-trigger interface. A high-level heuristic planner controls this interface during training, while alternative high-level controllers can drive the same low-level policy at inference. In simulation, RoboNaldo demonstrates free-kick shot error 48.6% lower and shoot velocity 2.96× than prior work baselines. In real world on a Unitree G1 with onboard perception, RoboNaldo attains 0.73 m and 0.86 m average target shooting error from 3 m away in free-kick and moving-ball cases, accordingly. And the post-contact ball velocity reaches 13.10 m/s, which is 59–71% of reported professional open-play shot speed.
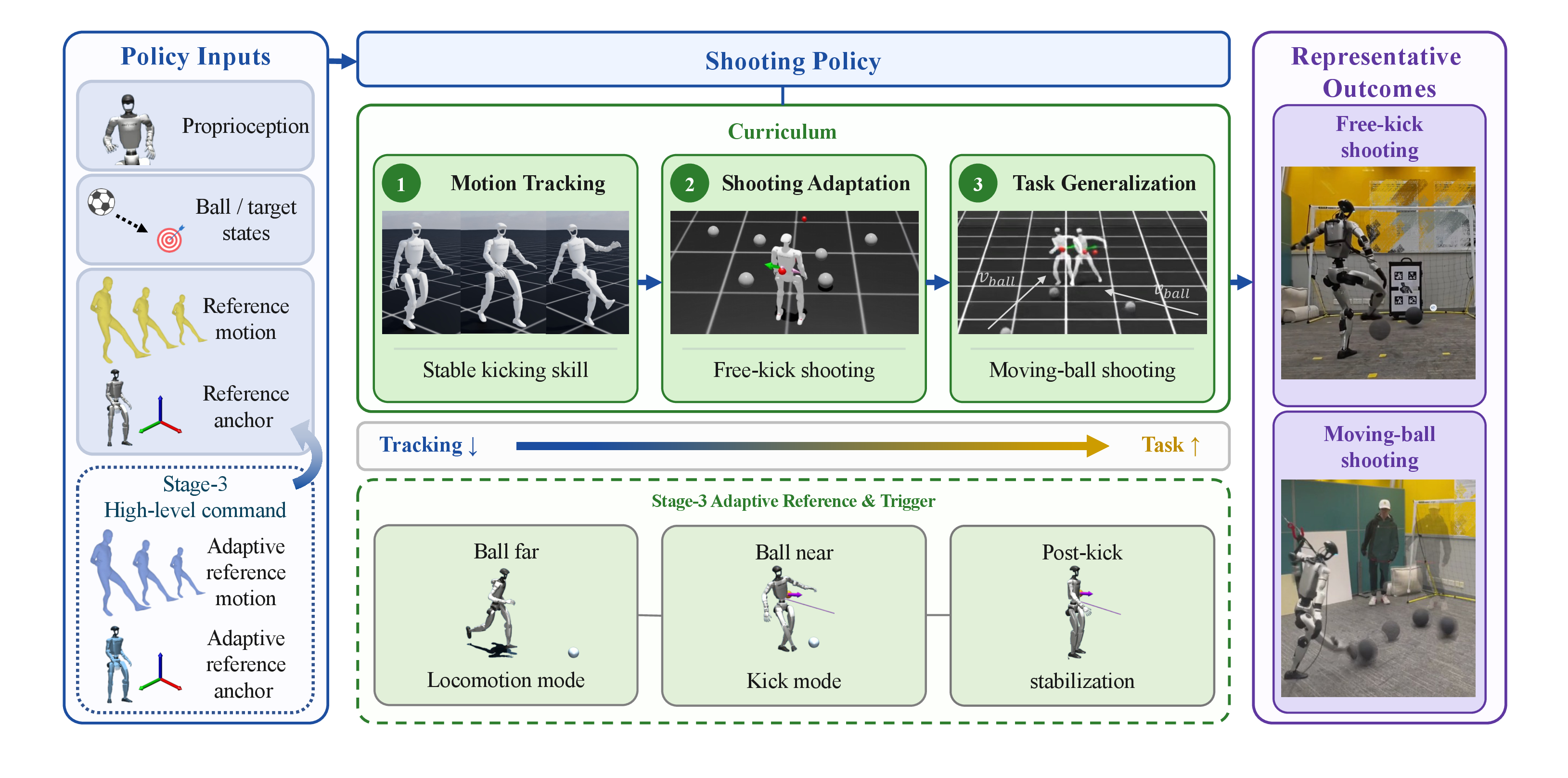
A 3-stage RL curriculum for a general-case humanoid soccer shooting policy, built on a single human kick reference.
In Stage 1, the policy tracks the reference for a stable kicking prior.
In Stage 2, task-reward-driven RL fine-tuning learns deviations around the tracker to adapt the kick to varied stationary-ball configurations. This stage saturates beyond stationary balls — once timing pressure rises with moving balls, the policy abandons the motion prior to chase task reward.
In Stage 3, a heuristic kick-timing and locomotion planner drives the policy: the reference kick provides guidance only when the planner triggers a kick; otherwise, locomotion rewards drive the robot toward the ball.
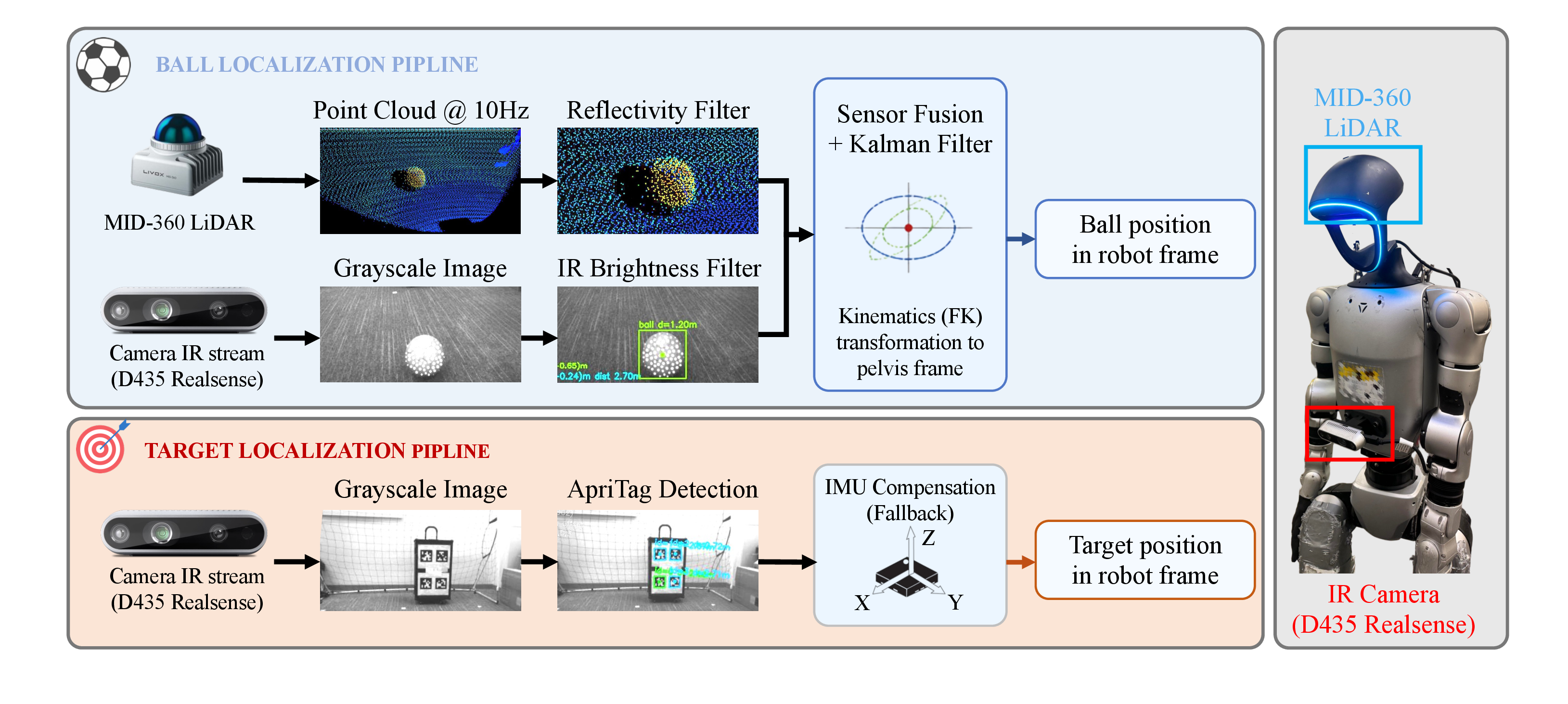
On real hardware, RoboNaldo reaches 0.73 m / 0.86 m point-level shot-to-goal error in stationary / moving-ball cases; the best shot lands 17 cm from a 3 m target at 13.10 m/s ball speed. With egocentric onboard sensing of both ball and target, RoboNaldo is ready for outdoor deployment.
Stage 2 learns accurate free-kicks on stationary balls. Stage 3 extends the policy to interactive shots on moving balls with heuristically planned timing and locomotion.
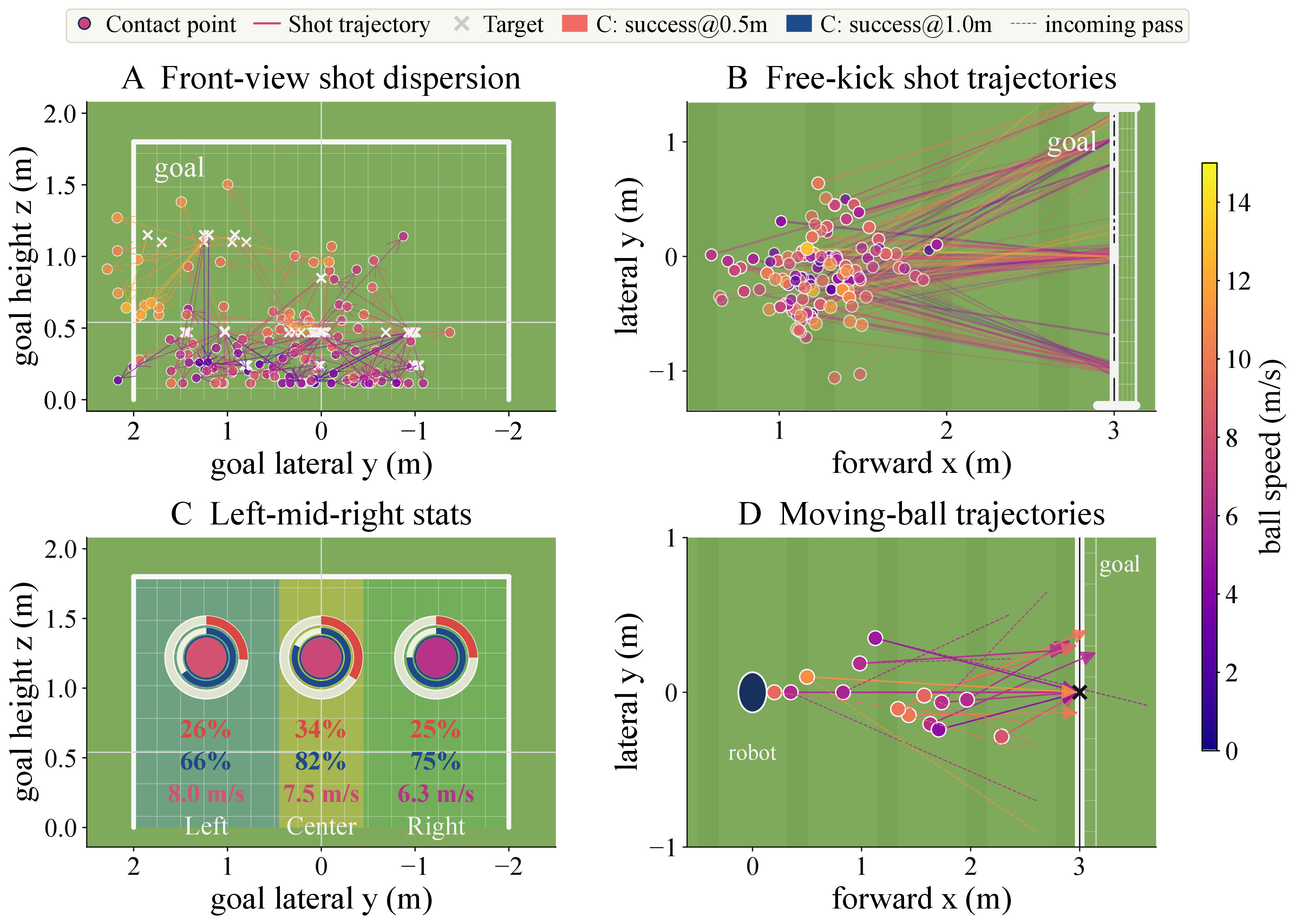
Stationary ball, directed targets at 3m far.
Target at left · middle · right.
Target at left · middle · right.
Target at left · middle · right.
Left · middle · right of the robot.
Near · medium · far from the robot.
Interactive shots on incoming moving balls.
Increasing ball speed.
On-field deployment, fully onboard.
Artificial soccer field · artificial hockey field · natural grass field. The hockey field is a bit more plain than the soccer field.
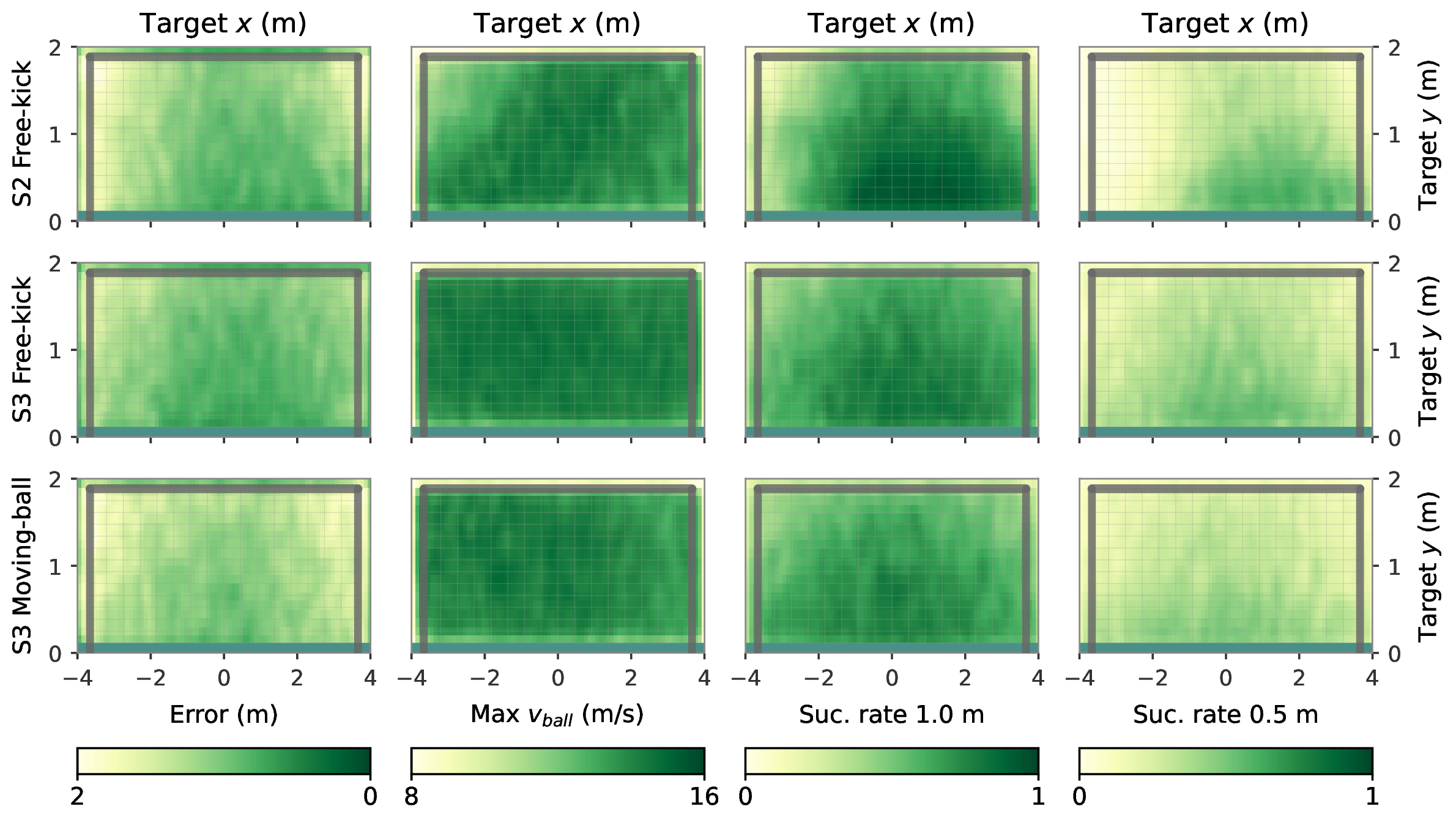
Targets sweep an 8 m × 2 m goal plane at a 3 m shooting distance. Each cell colors the shot-quality score at that target location. Stage 2 sharply covers the free-kick regime; Stage 3 trades a small accuracy margin for moving-ball generalization.
@article{zhong2026robonaldo,
title = {RoboNaldo: Accurate, Stable and Powerful Humanoid Soccer Shooting via Motion-Guided Curriculum Reinforcement Learning},
author = {Zhong, Yichao and Lu, Yidan and Lu, Yuhang and Tang, Tianyang and Mai, Haoguang and Pan, Yixuan and Li, Tianyu and Chen, Li and Wang, Jingbo and Li, Zhongyu and Lu, Peng and Li, Hongyang},
year = {2026},
eprint = {2606.11092},
archivePrefix = {arXiv},
primaryClass = {cs.RO},
url = {https://arxiv.org/abs/2606.11092}
}