Publication
We position OpenDriveLab as one of the most top research teams around globe, since we've got talented people and published work at top venues.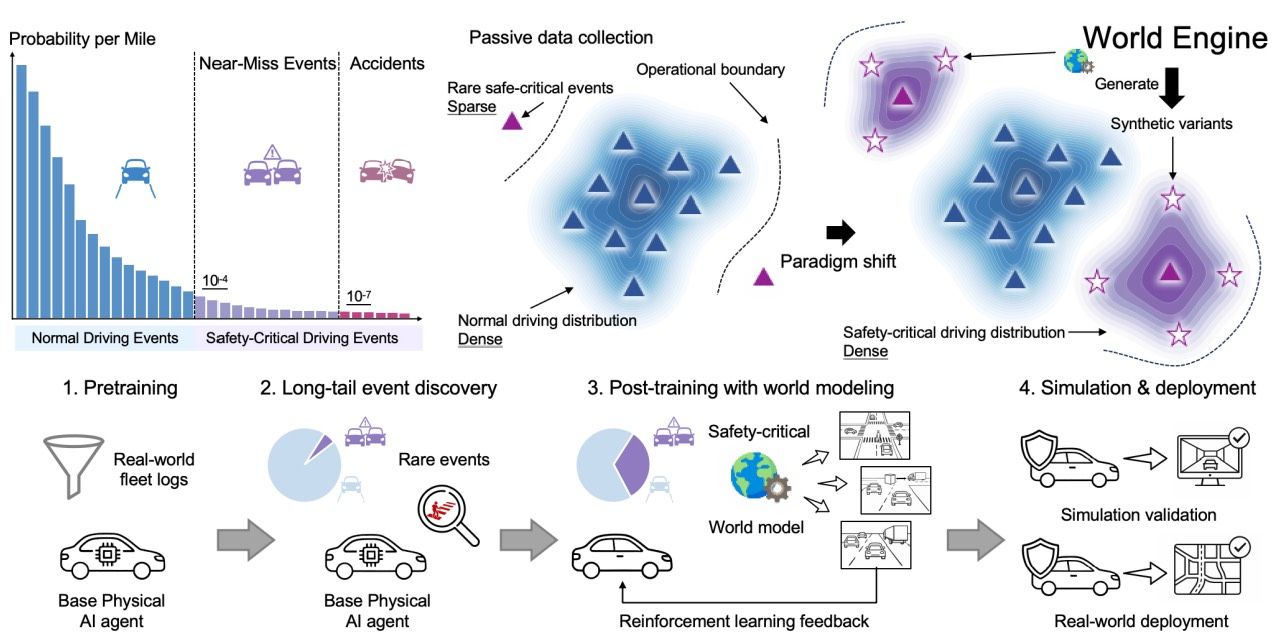
Zhenjie Yang,
Yufei Wang,
Luoxi Zou,
Jiaxin Peng,
Jin Pan,
Zhaoyu Su,
Andrei Bursuc,
Shengbo Eben Li,
Peng Su,
Research Article 2026


The missing infrastructure for Physical AI post-training in AD. Open-source. Production-validated.
Antonio Loquercio,
Preprint 2026Position Paper
Yihan Hu,
Jiazhi Yang,
Keyu Li,
Xizhou Zhu,
Siqi Chai,
Senyao Du,
Tianwei Lin,
Lewei Lu,
Qiang Liu,
Jifeng Dai,

Team AgiBot-World
IROS 2025 Best Paper Finalist


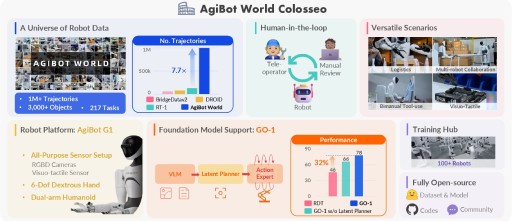
A novel generalist policy that leverages latent action representations to maximize data utilization, demonstrating predictable performance scaling with increased data volume.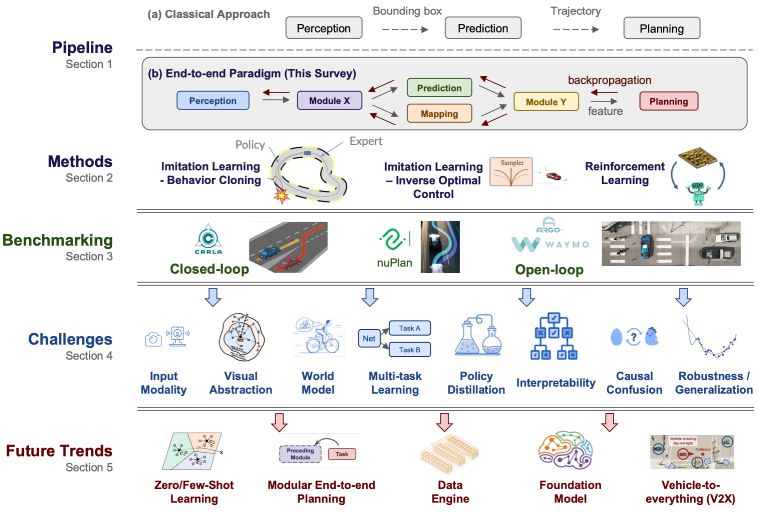
Bernhard Jaeger,
IEEE-TPAMI 2024Survey
In this survey, we provide a comprehensive analysis of more than 270 papers on the motivation, roadmap, methodology, challenges, and future trends in end-to-end autonomous driving.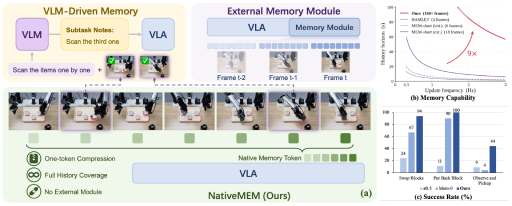
Modi Shi,
Chaojun Ni,
Jiazhi Yang,
Mengdi Li,
Zhizhong Su,
Tianwei Lin,
Preprint 2026
NativeMEM gives pretrained Vision-Language-Action policies long-term, real-time visual memory by compressing each historical frame-view observation into a single native memory token.
Yichao Zhong,
Yidan Lu,
Tianyang Tang,
Haoguang Mai,
Yixuan Pan,
Jingbo Wang,
Zhongyu Li,
Peng Lu,
Preprint 2026

World's first sub-meter accurate humanoid soccer shooting policy in general cases — single human reference, learn to track, then deviate and adapt.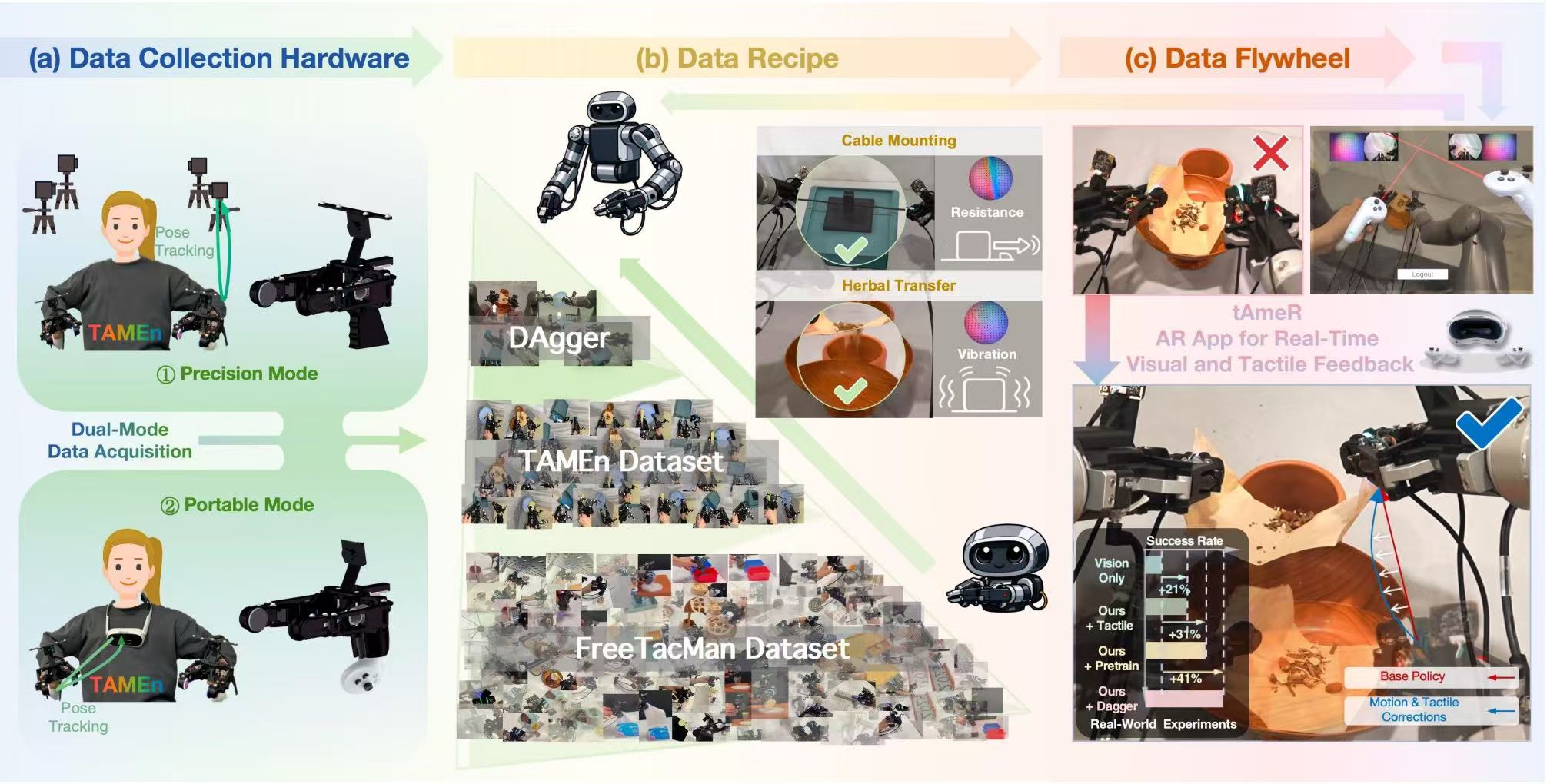
Longyan Wu,
Jieji Ren,
Chenghang Jiang,
Junxi Zhou,
Shijia Peng,
Ran Huang,
Guoying Gu,
Preprint 2026
TAMEn builds upon the UMI paradigm with key enhancements in multimodality, precision-portability synergy, replayability, and data flywheel.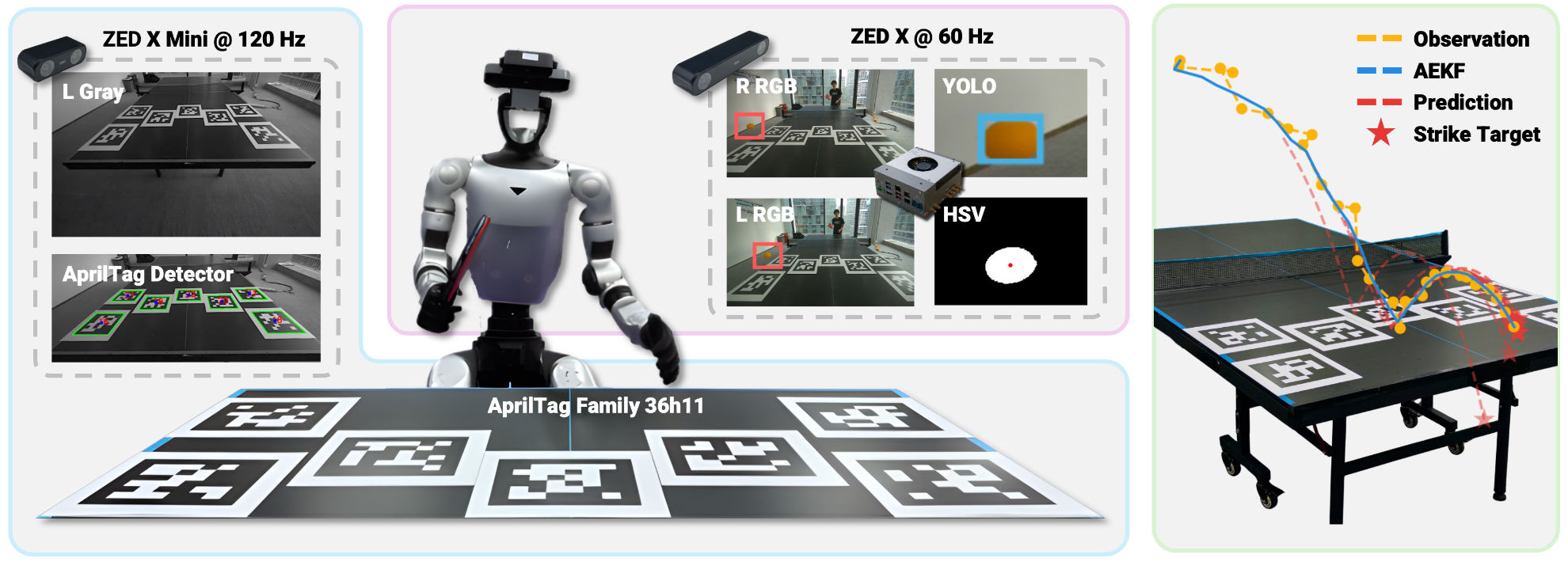
Junli Ren,
Yinghui Li,
Kai Zhang,
Penglin Fu,
Haoran Jiang,
Yixuan Pan,
Guangjun Zeng,
Tao Huang,
Weizhong Guo,
Peng Lu,
Jingbo Wang,
Preprint 2026
The future of robotics begins where the lab ends: in open-world interaction.
Zhuoheng Li,
Qingquan Lin,
Checheng Yu,
Qiangyu Chen,
Zhiqian Lan,
Lutong Zhang,
Preprint 2026
An open-source, high-DoF, lightweight, multimodal, and modular dexterous hand.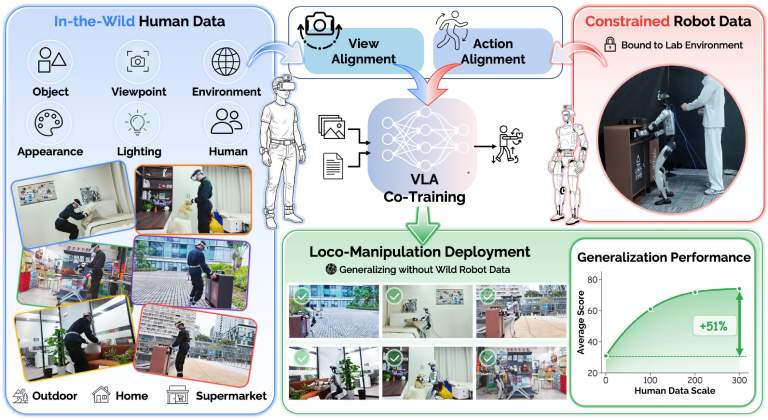
Modi Shi,
Shijia Peng,
Haoran Jiang,
Yinghui Li,
Di Huang,
RSS 2026
The first endorsement of human-to-humanoid transfer for whole-body locomanipulation.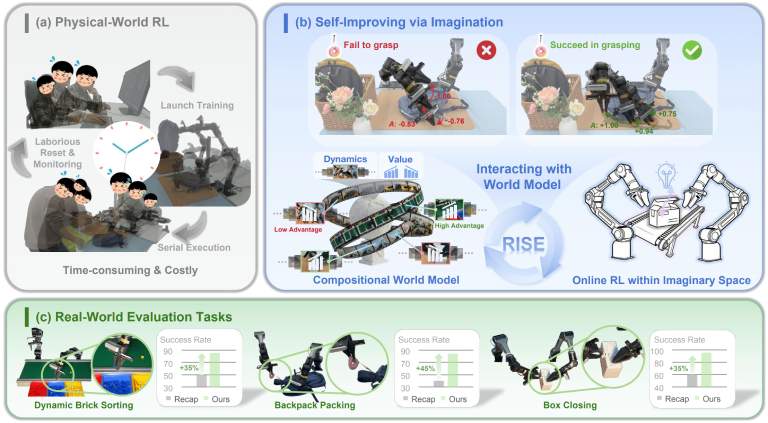
Jiazhi Yang,
Kunyang Lin,
Jinwei Li,
Wencong Zhang,
Tianwei Lin,
Longyan Wu,
Zhizhong Su,
Hao Zhao,
Ya-Qin Zhang,
Xiangyu Yue,
RSS 2026
The first study on leveraging world models as an effective learning environment for challenging real-world manipulation, bootstrapping performance on tasks requiring high dynamics, dexterity, and precision.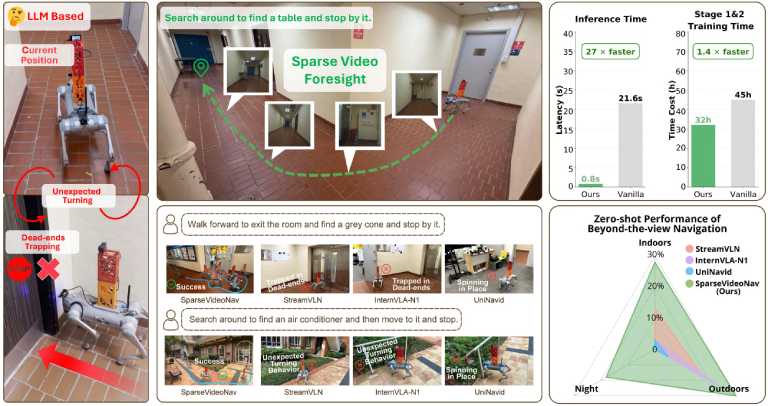
Siqi Liang,
Yuxian Li,
Yukuan Xu,
Yichao Zhong,
Fu Zhang,
Preprint 2026
we investigate beyond-the-view navigation task in the real world by introducing video generation model in this field for the first time, pioneering such capability in challenging night scenarios.
Checheng Yu,
Gangcheng Jiang,
Haoguang Mai,
Kaiyang Wu,
Lirui Zhao,
Modi Shi,
Qingwen Bu,
Shijia Peng,
Yibo Yuan
Preprint 2026

"Veni, Vidi, Vici" - I came, I saw, I conquered. We aim to conquer the "Mount Everest" of robotics: 100% reliability in real-world garment manipulation.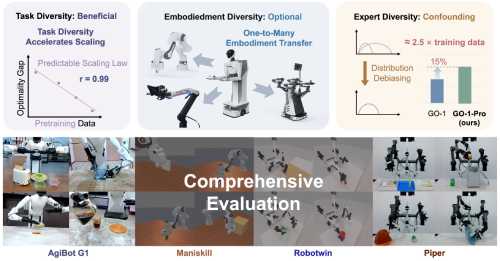
Modi Shi,
Chiming Liu,
Guanghui Ren,
Di Huang,
Maoqing Yao,
Preprint 2025
The first comprehensive analysis of data diversity principles revealing optimal scaling strategies for large-scale robotic manipulation training.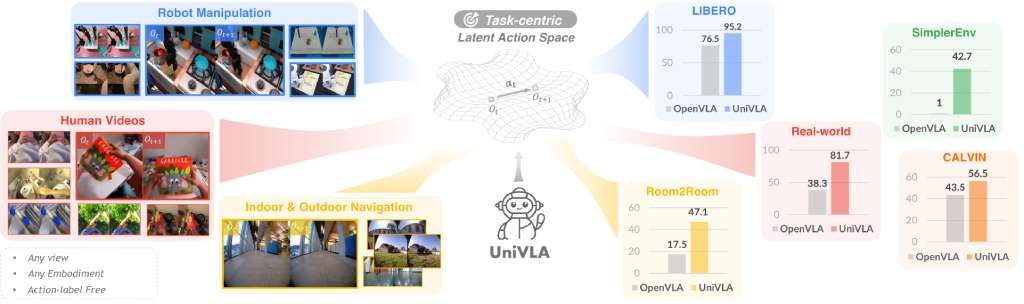
Qingwen Bu,
Guanghui Ren,
Maoqing Yao,
RSS 2025
A unified vision-language-action framework that enables policy learning across different environments.
Haoran Jiang,
Qingwen Bu,
Modi Shi,
Yanjie Zhang,
Delong Li,
Chuanzhe Suo,
Chuang Wang,
ICLR 2026
A unified VLA framework enabling large-space humanoid loco-manipulation via unified latent learning and loco-manipulation-oriented RL. 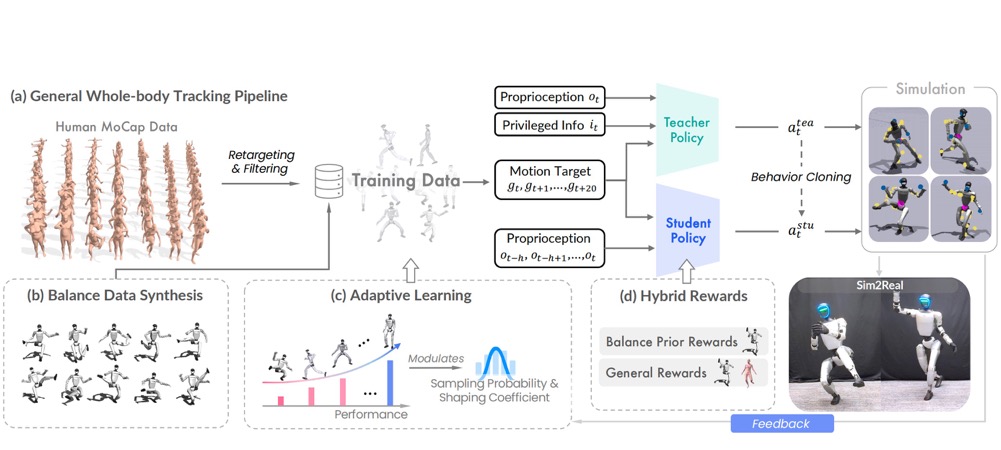
Yixuan Pan,
Ruoyi Qiao,
Liang Pan,
Haoguang Mai,
Qingwen Bu,
Hao Zhao,
Cunyuan Zheng,
ICRA 2026
A unified whole-body control policy for humanoid robots that enables zero-shot execution of diverse motions, including Ip Man'squat, dancing, running and real-time teleoperation.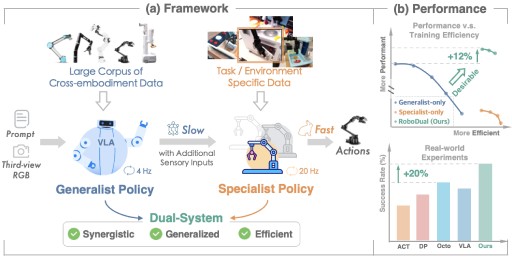
Qingwen Bu,
Jia Zeng,
Heming Cui,
Maoqing Yao,
Preprint 2024
Our objective is to develop a synergistic dual-system framework which supplements the generalizability of large-scale pre-trained generalist with the efficient and task-specific adaptation of specialist.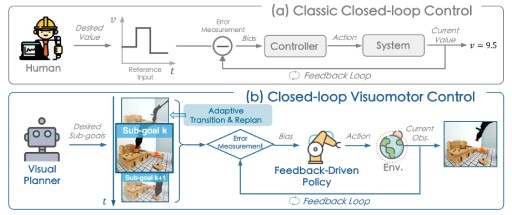
Qingwen Bu,
Jia Zeng,
Yanchao Yang,
Guyue Zhou,
Heming Cui,
NeurIPS 2024
CLOVER employs a text-conditioned video diffusion model for generating visual plans as reference inputs, then these sub-goals guide the feedback-driven policy to generate actions with an error measurement strategy.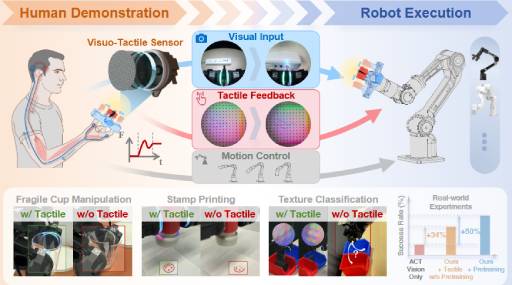
Longyan Wu,
Checheng Yu,
Jieji Ren,
Ran Huang,
Guoying Gu,
ICRA 2026

A human-centric and robot-free visuo-tactile data collection system for high-quality and efficient robot manipulation.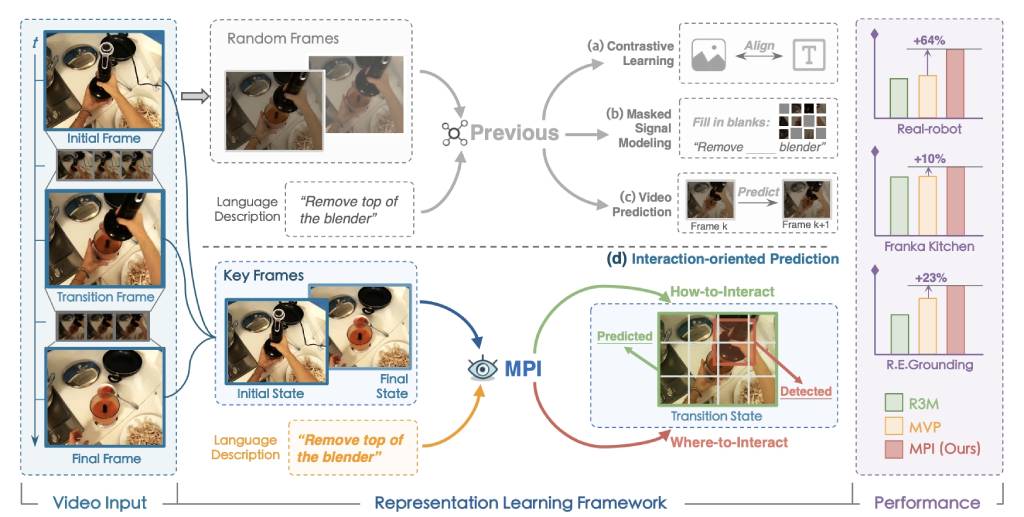
Jia Zeng,
Qingwen Bu,
Wenke Xia,
Hao Dong,
Haoming Song,
Dong Wang,
Di Hu,
Heming Cui,
Bin Zhao,
Xuelong Li,
RSS 2024
We propose a general pre-training pipeline that learns Manipulation by Predicting the Interaction (MPI).Zhenjie Yang,
Yufei Wang,
Luoxi Zou,
Jiaxin Peng,
Jin Pan,
Zhaoyu Su,
Andrei Bursuc,
Shengbo Eben Li,
Peng Su,
Research Article 2026
The missing infrastructure for Physical AI post-training in AD. Open-source. Production-validated.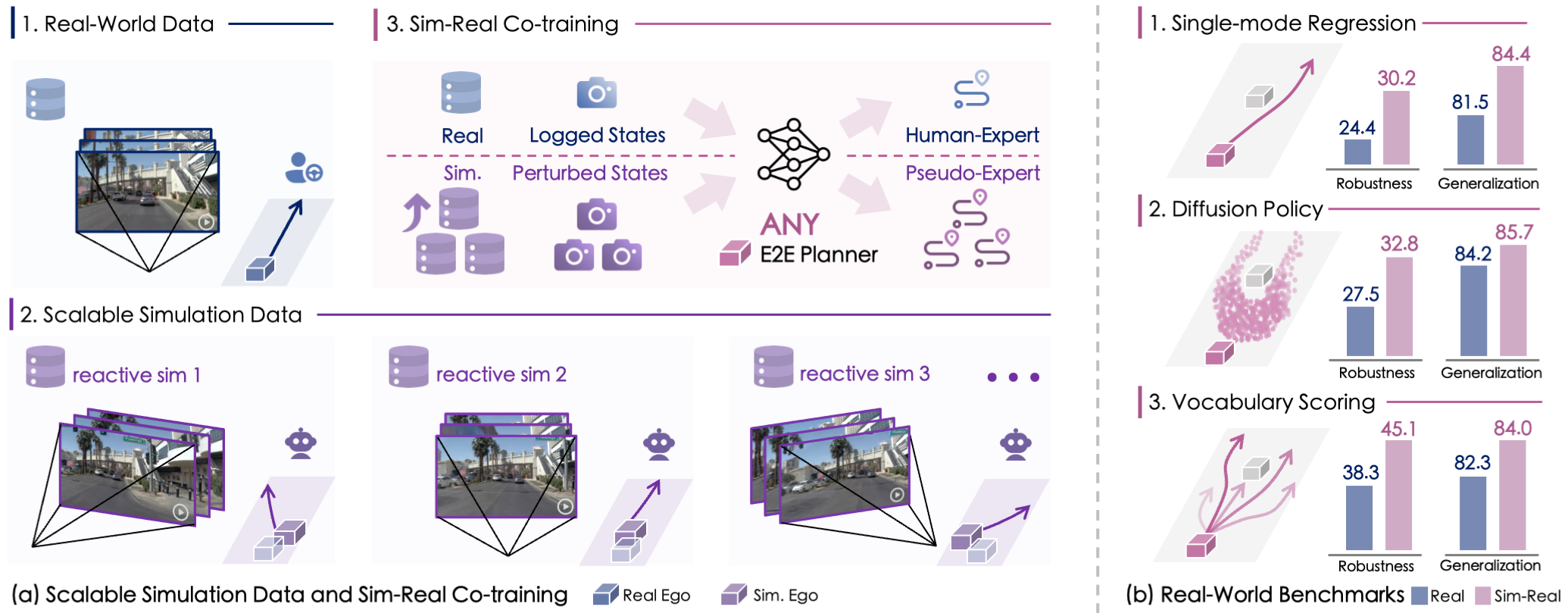
Jiazhi Yang,
Guang Li,
Junli Wang,
Yinfeng Gao,
Zhang Zhang,
Liang Wang,
Hangjun Ye,
Tieniu Tan,
Long Chen,
CVPR 26 Oral

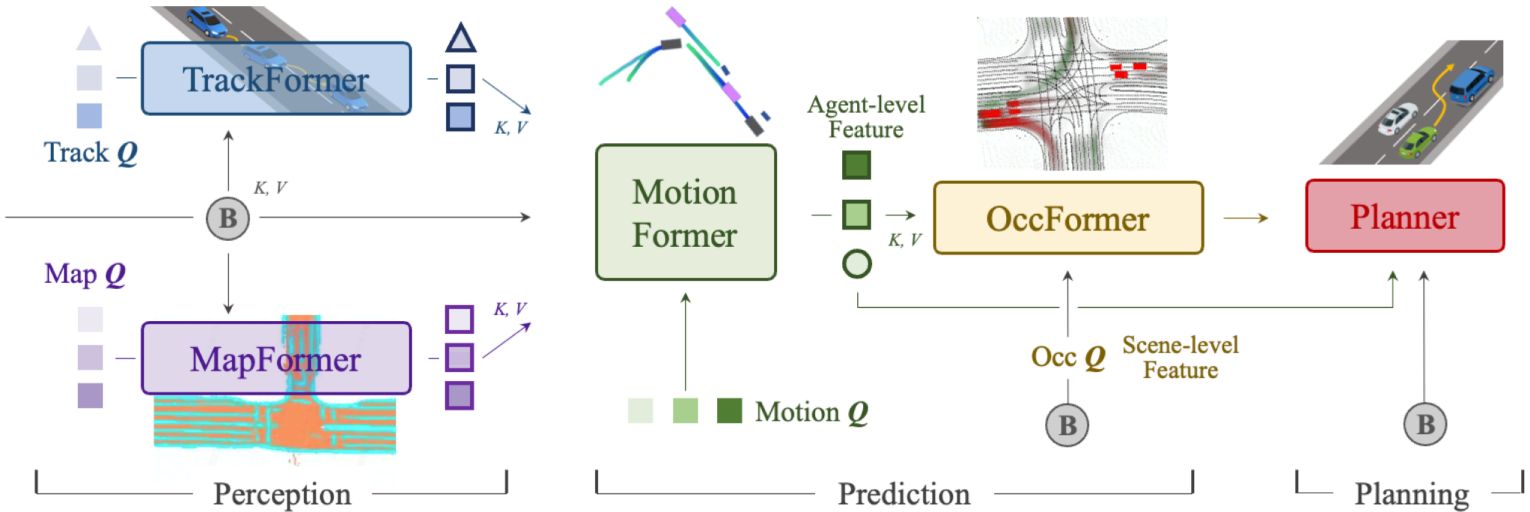
A scalable sim-real learning framework that synthesizes high-fidelity driving data and cboosts end-to-end planners to achieve robust, generalizable autonomy with principled scaling insights.
Haohan Yang,
Ke Guo,
Hongchen Li,
Chen Lv
IEEE-TPAMI 2026
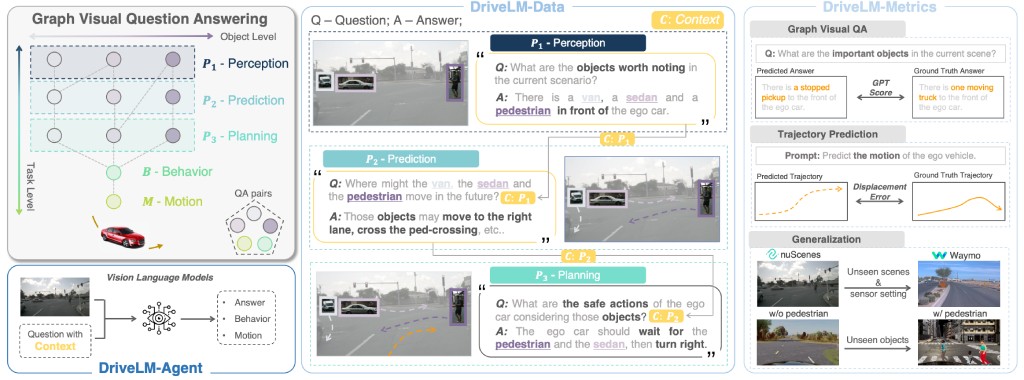
Katrin Renz,
ECCV 2024 Oral
Unlocking the future where autonomous driving meets the unlimited potential of language.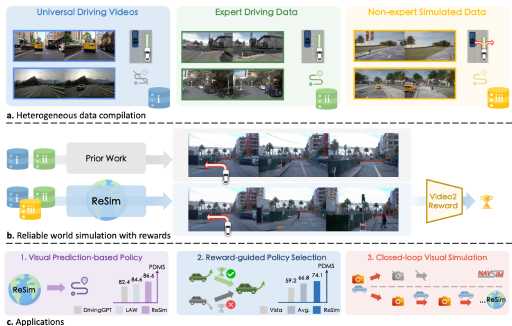
Jiazhi Yang,
Long Chen,
Yuqian Shao,
Xiangyu Yue,
NeurIPS 2025 Spotlight
ReSim is a driving world model that enables Reliable Simulation of diverse open-world driving scenarios under various actions, including hazardous non-expert ones. A Video2Reward model estimates the reward from ReSim's simulated future.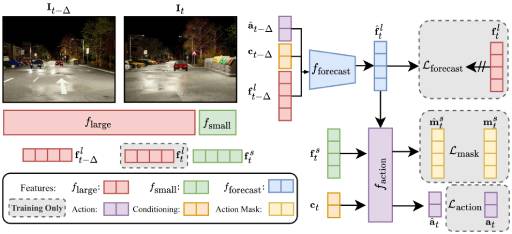

William Ljungbergh,
Jiazhi Yang,
Hongzi Zhu,
Christoffer Petersson,
ICCV 2025
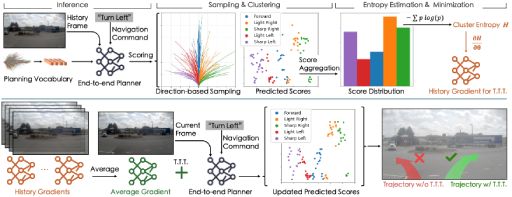
Zhiding Yu,
Shiyi Lan,
Jose M. Alvarez
Preprint 2025
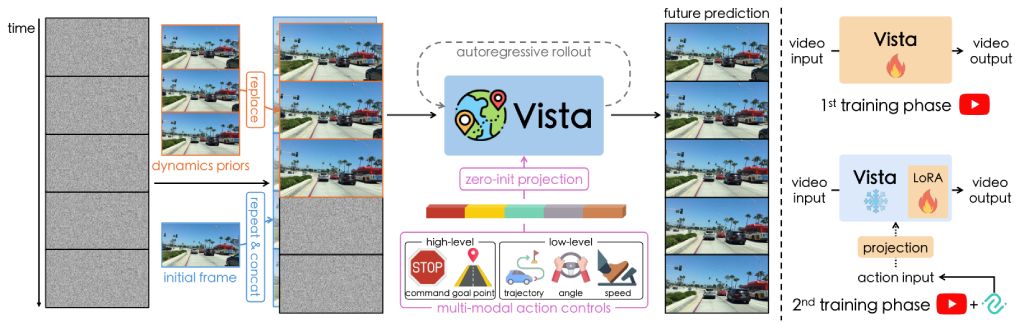
Jiazhi Yang,
Jun Zhang,
NeurIPS 2024

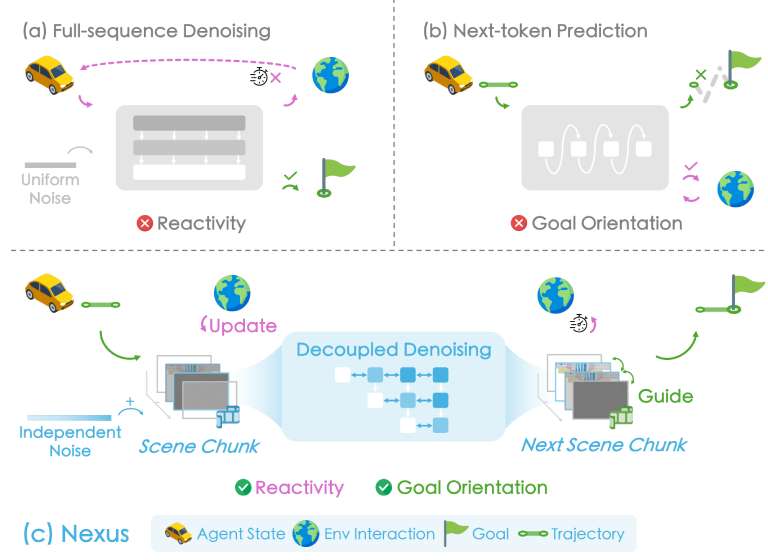
A generalizable driving world model with high-fidelity open-world prediction, continuous long-horizon rollout, and zero-shot action controllability.
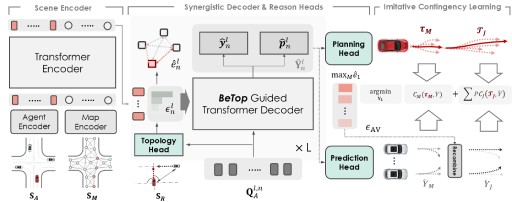

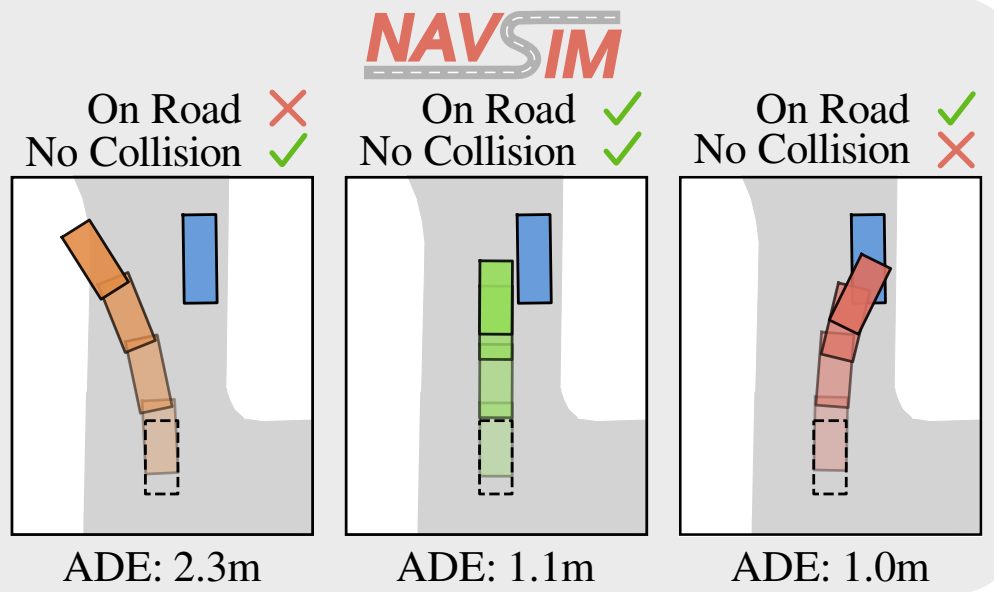
Daniel Dauner,
Marcel Hallgarten,
Xinshuo Weng,
Zhiyu Huang,
Igor Gilitschenski,
Boris Ivanovic,
Marco Pavone,
NeurIPS 2024 Track Datasets and Benchmarks
Data-Driven Non-Reactive Autonomous Vehicle Simulation and Benchmarking.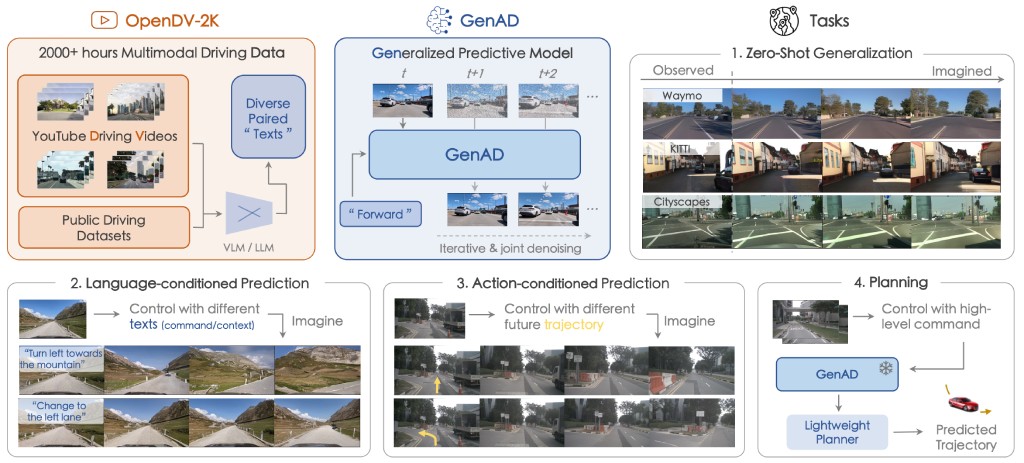
Jiazhi Yang,
Bo Dai,
Jia Zeng,
Jun Zhang,
CVPR 2024 Highlight

We aim to establish a generalized video prediction paradigm for autonomous driving by presenting the largest multimodal driving video dataset to date, OpenDV-2K, and a generative model that predicts the future given past visual and textual input, GenAD.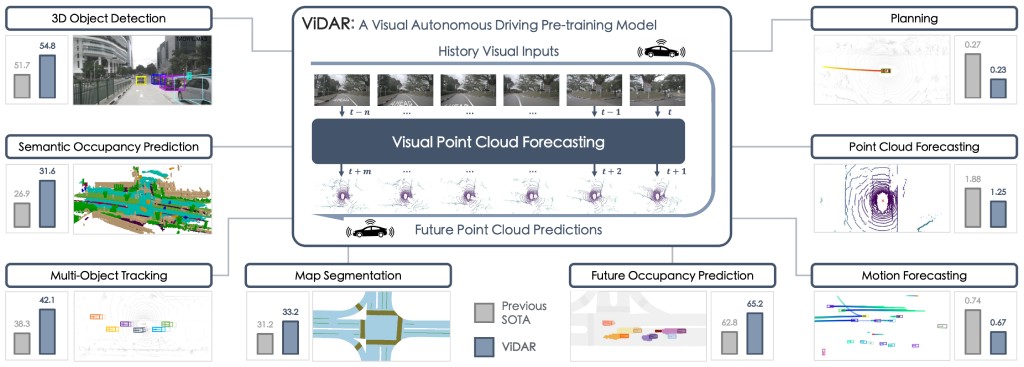
Yanan Sun,
CVPR 2024 Highlight
A new self-supervised pre-training task for end-to-end autonomous driving, predicting future point clouds from historical visual inputs, joint modeling the 3D geometry and temporal dynamics for simultaneous perception, prediction, and planning.
Yang Li,
Jia Zeng,
Huilin Xu,
Pinlong Cai,
Feng Xu,
Lu Xiong,
Jingdong Wang,
Futang Zhu,
Kai Yan,
Chunjing Xu,
Tiancai Wang,
Fei Xia,
Beipeng Mu,
Dahua Lin,
中國科學:信息科學Survey
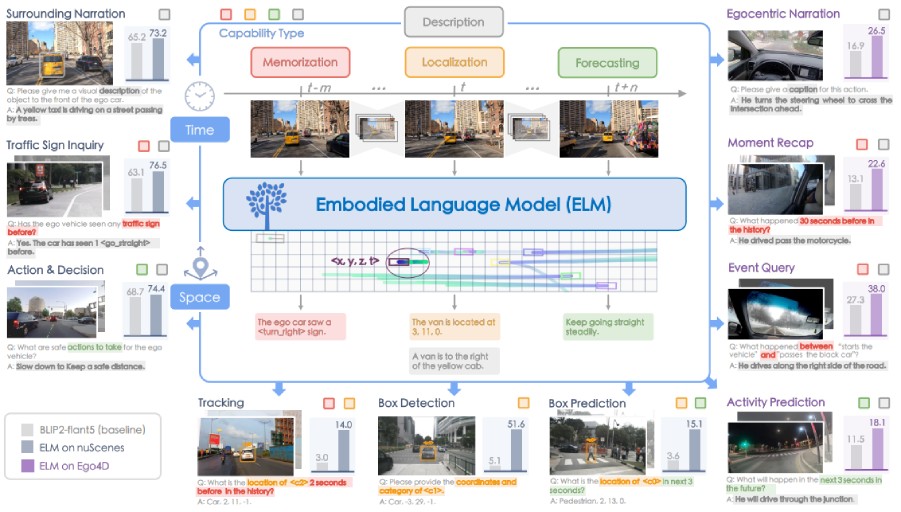
Qingwen Bu,
Jia Zeng,
Hang Qiu,
Hongzi Zhu,
Minyi Guo,
ECCV 2024
Revive driving scene understanding by delving into the embodiment philosophy.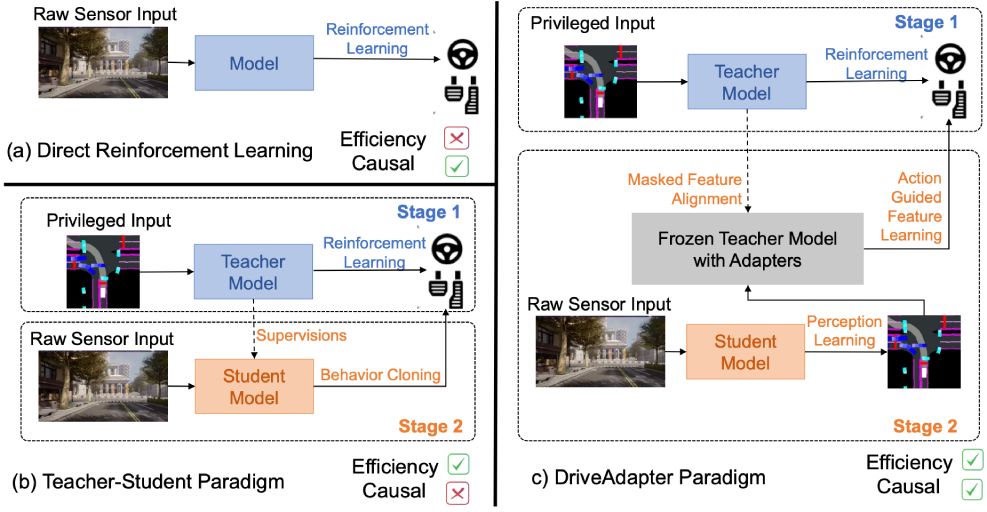
Patrick Langechuan Liu,
ICCV 2023 Oral
A new paradigm for end-to-end autonomous driving without causal confusion issue.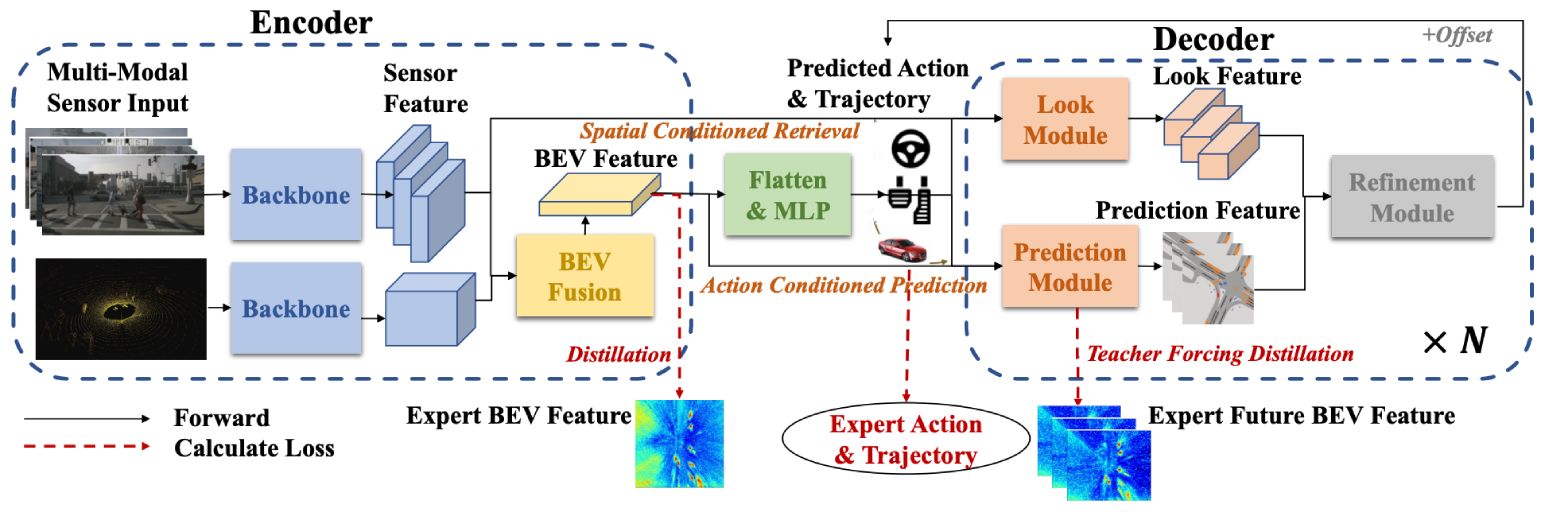
Jiangwei Xie,
Conghui He,
CVPR 2023
A scalable decoder paradigm that generates the future trajectory and action of the ego vehicle for end-to-end autonomous driving.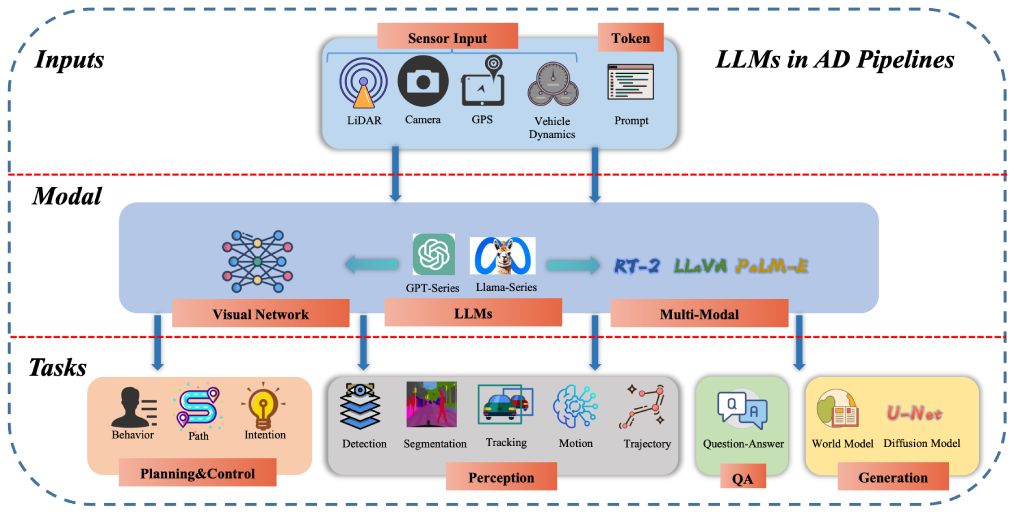
Zhenjie Yang,
Preprint 2023Survey
A collection of research papers about LLM-for-Autonomous-Driving (LLM4AD).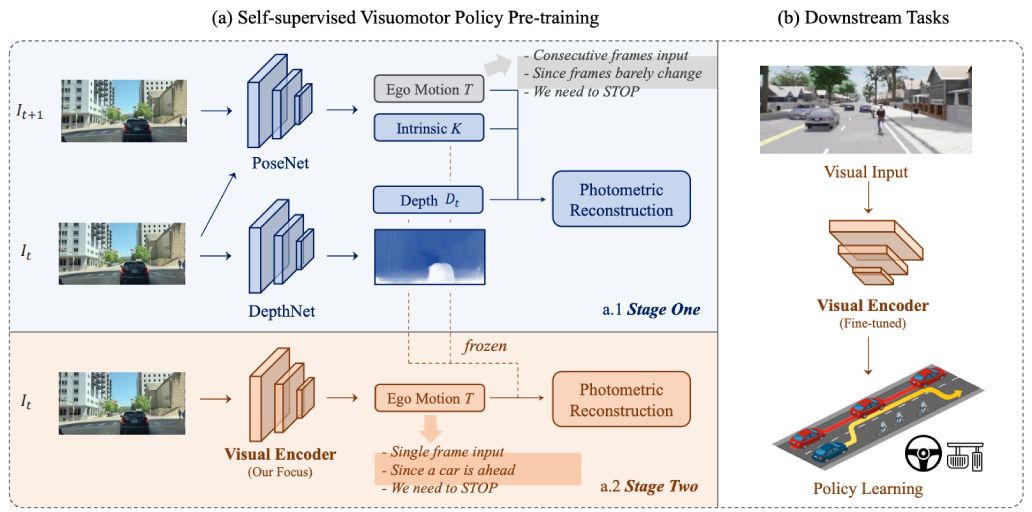
ICLR 2023
An intuitive and straightforward fully self-supervised framework curated for the policy pre-training in visuomotor driving.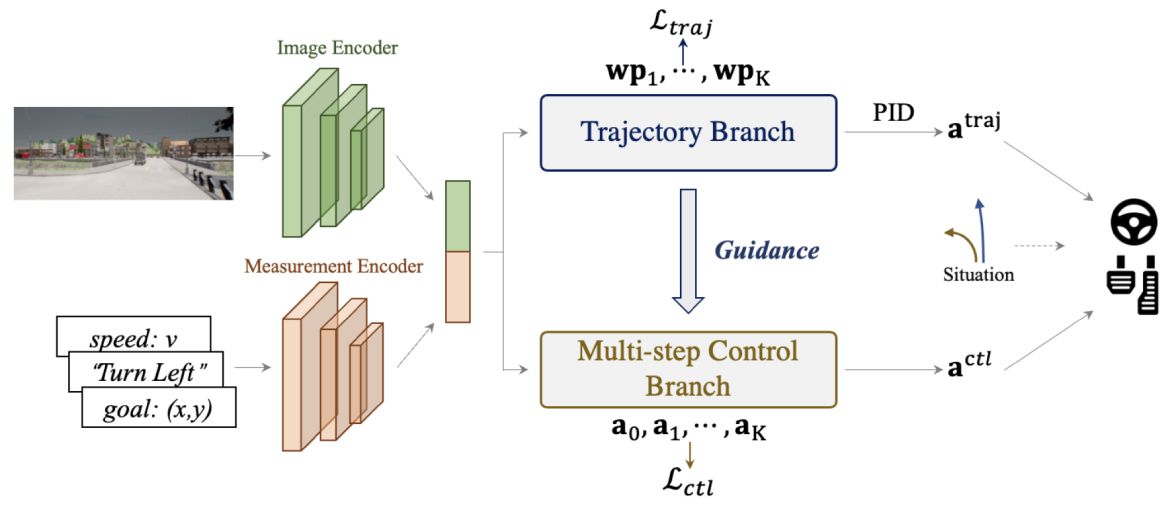
Trajectory-guided Control Prediction for End-to-end Autonomous Driving: A Simple yet Strong Baseline
NeurIPS 2022

Take the initiative to explore the combination of controller based on a planned trajectory and perform control prediction.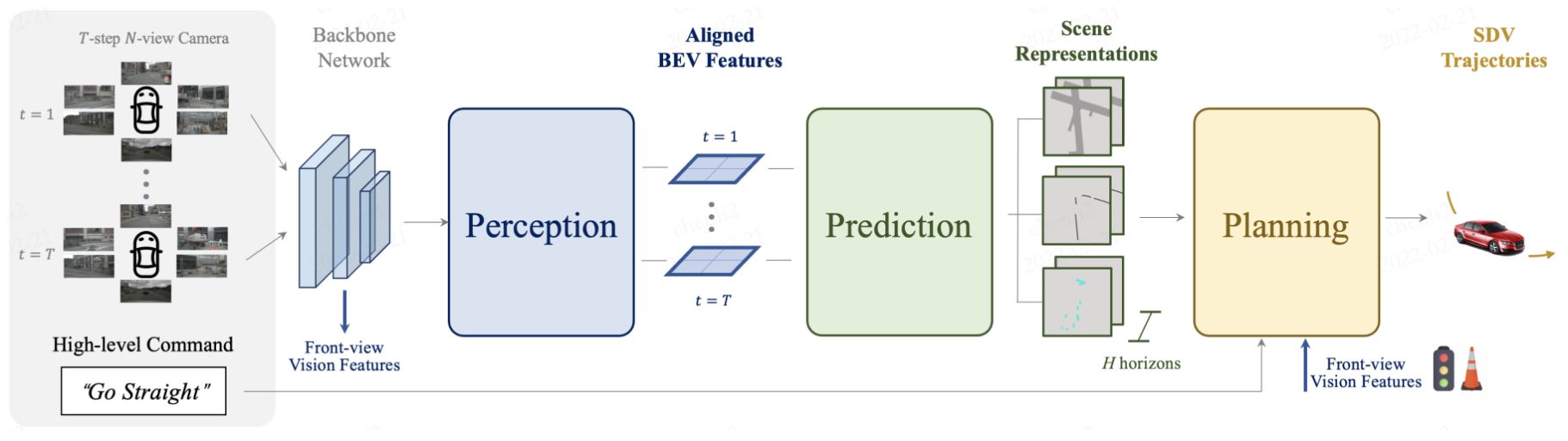
Dacheng Tao
ECCV 2022
A spatial-temporal feature learning scheme towards a set of more representative features for perception, prediction and planning tasks simultaneously.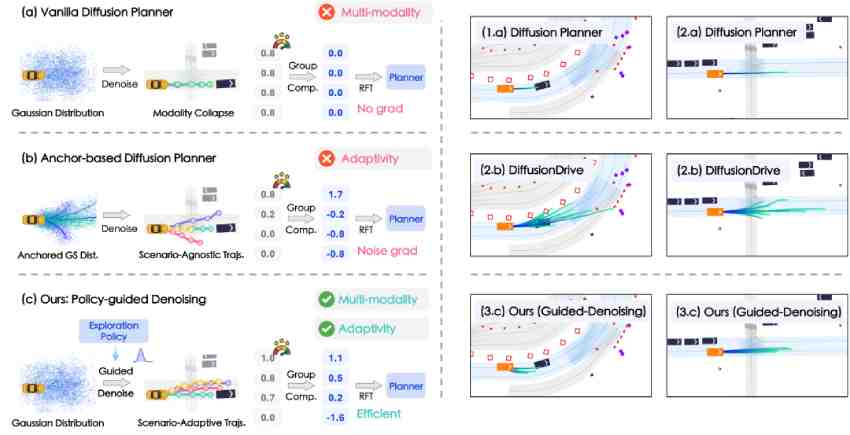
Hongchen Li,
Jiazhi Yang,
Lei Shi,
Mingyang Shang,
Zengrong Lin,
Gaoqiang Wu,
Zhihui Hao,
Xianpeng Lang,
Jia Hu,
Preprint 2026
A closed-loop and sample-efficient RFT framework for diffusion-based planners.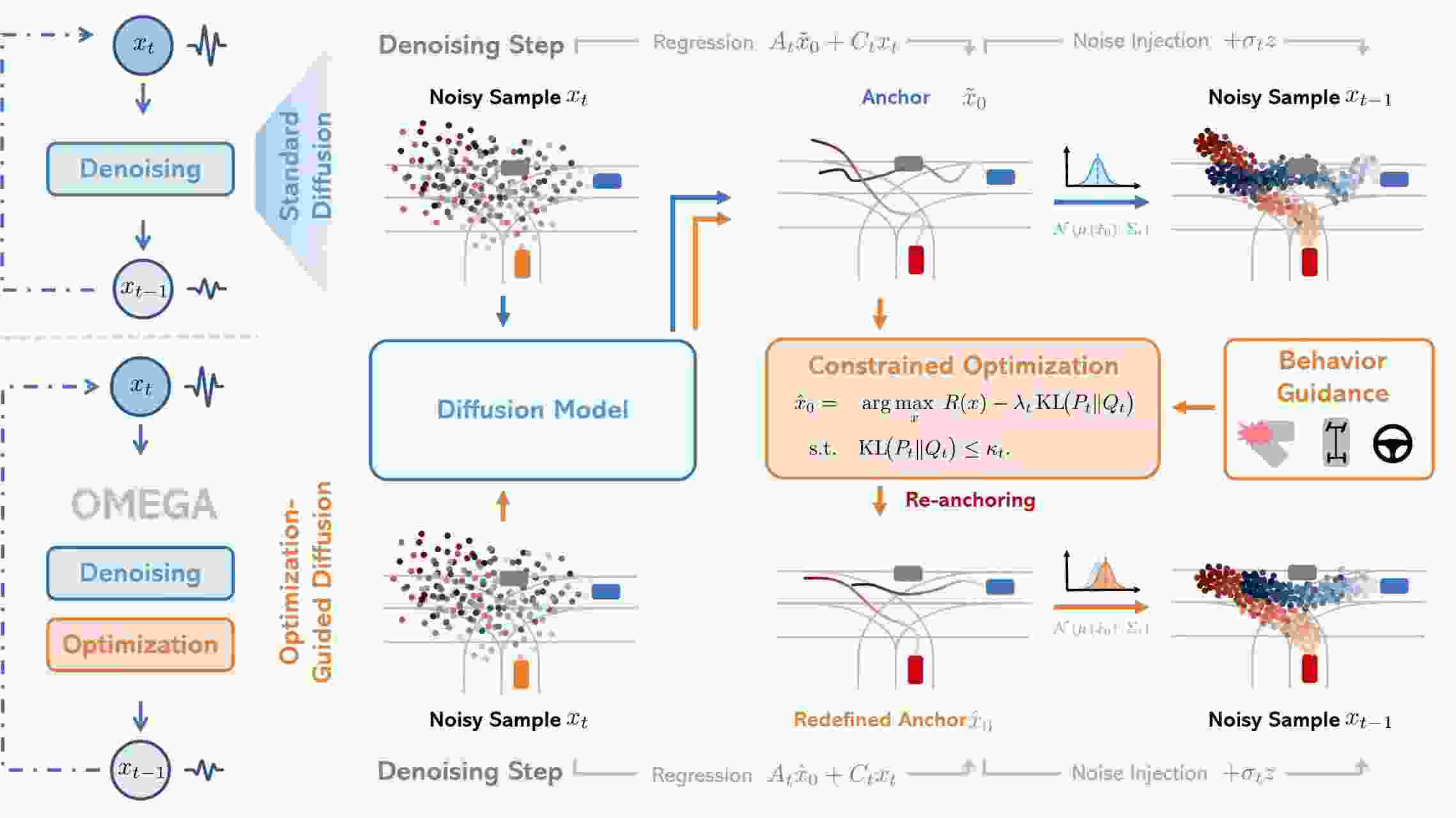
Shihao Li,
Tuo An,
Peng Su,
Boyang Wang,
Haiou Liu,
Chen Lv,
Preprint 2025
OMEGA is a training-free, optimization-guided diffusion framework that enforces structural consistency and interaction reasoning during sampling to generate realistic, controllable, and safety-critical multi-agent driving scenes.
Zhenhua Wu,
Carl Lindström,
Peng Su,
Matthias Nießner,
Preprint 2025
Peijin Jia,
Kun Jiang,
ICLR 2024
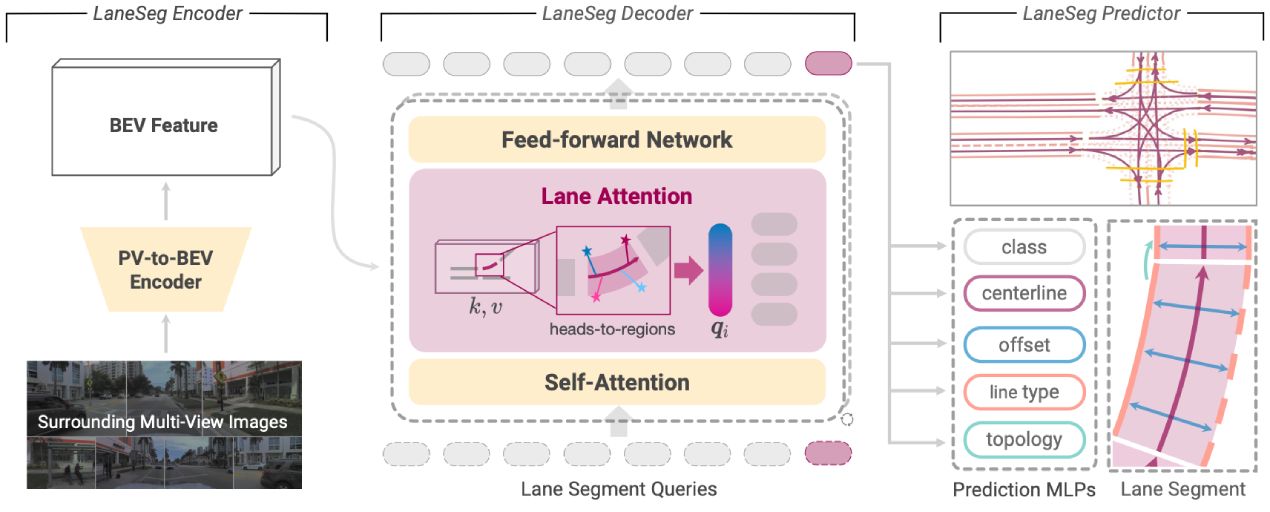
We advocate Lane Segment as a map learning paradigm that seamlessly incorporates both map geometry and topology information.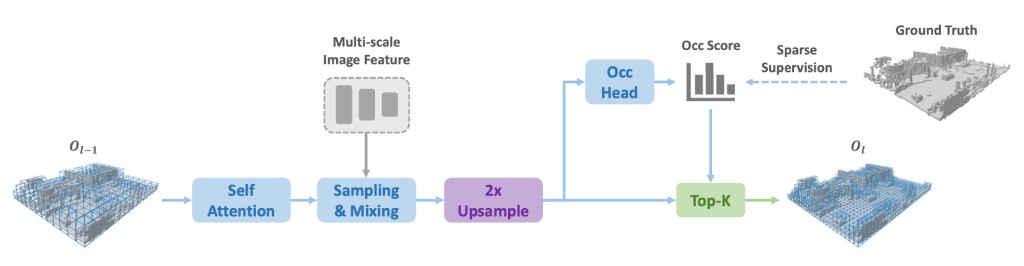
Haisong Liu,
Yang Chen,
Haiguang Wang,
Jia Zeng,
Limin Wang
ECCV 2024
Jingdong Wang,
NeurIPS 2023
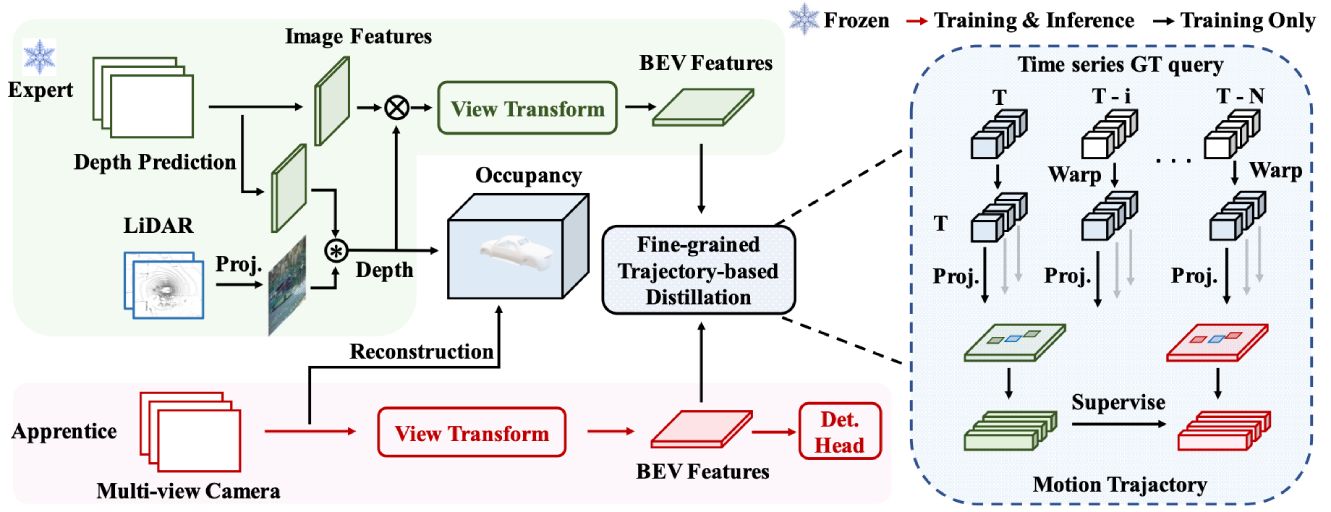
The unified framework to enhance 3D object detection by uniting a multi-modal expert model with a trajectory distillation module.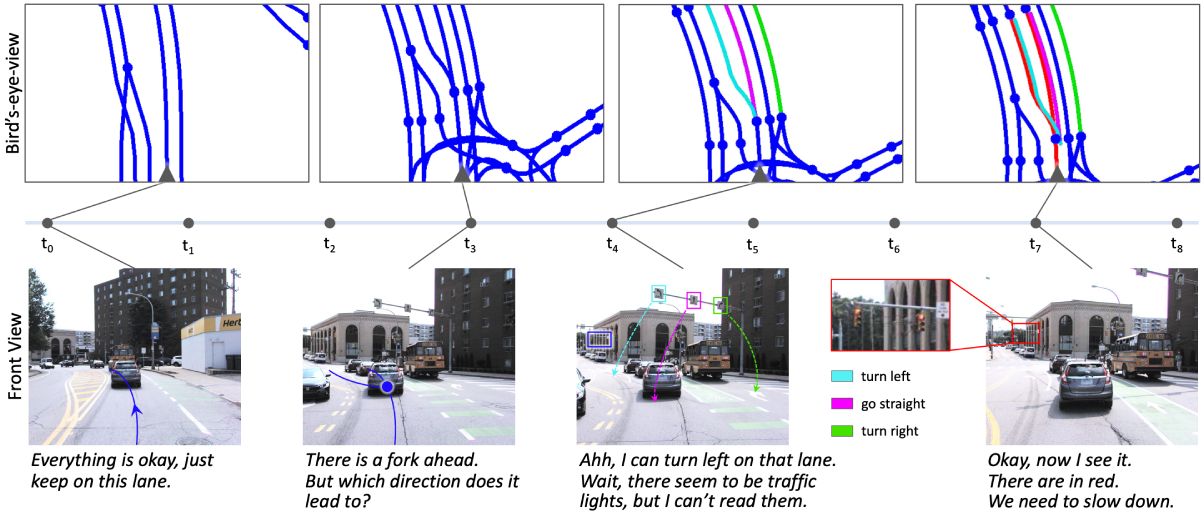
Yang Li,
Zhenbo Liu,
Peijin Jia,
Yuting Wang,
Shengyin Jiang,
Feng Wen,
Hang Xu,
Wei Zhang,
NeurIPS 2023 Track Datasets and Benchmarks
The world's first perception and reasoning benchmark for scene structure in autonomous driving.
Jifeng Dai,
Lewei Lu,
Jia Zeng,
Jiazhi Yang,
Hanming Deng,
Hao Tian,
Enze Xie,
Jiangwei Xie,
Yang Li,
Si Liu,
Jianping Shi,
Dahua Lin,
IEEE-TPAMI 2023Survey
We review the most recent work on BEV perception and provide analysis of different solutions.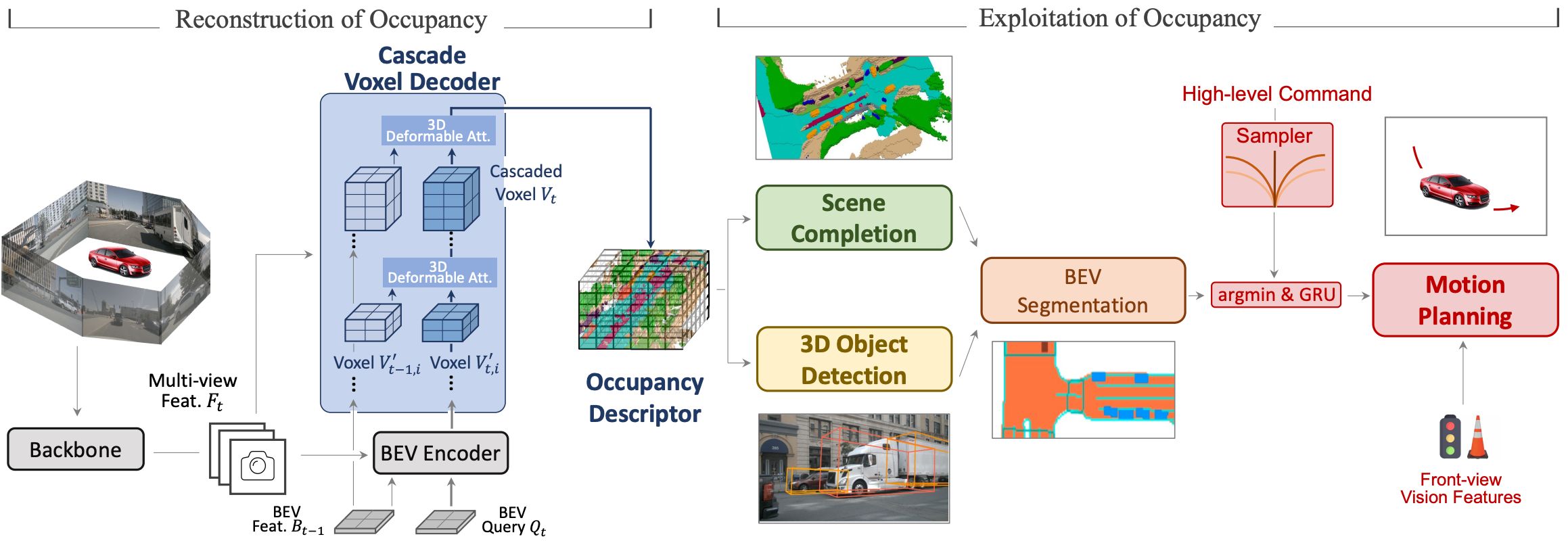
Wenwen Tong,
Tai Wang,
Silei Wu,
Hanming Deng,
Yi Gu,
Lewei Lu,
Dahua Lin,
ICCV 2023
Occupancy serves as a general representation of the scene and could facilitate perception and planning in the full-stack of autonomous driving.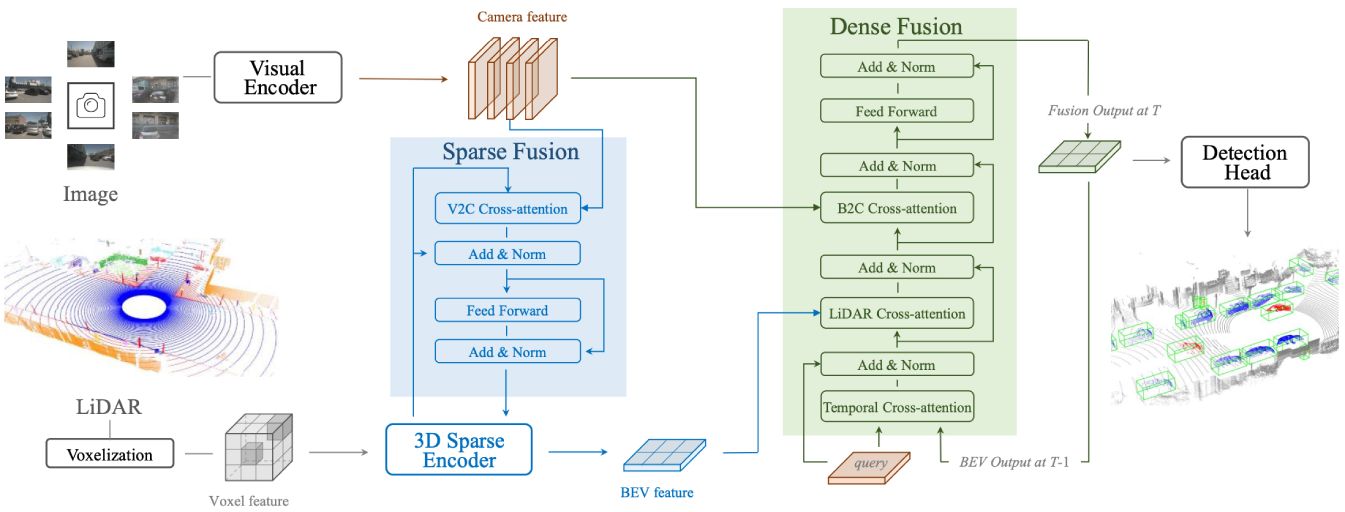
Shaoshuai Shi,
Shangzhe Di,
Si Liu,
IROS 2023
We propose Sparse Dense Fusion (SDF), a complementary framework that incorporates both sparse-fusion and dense-fusion modules via the Transformer architecture.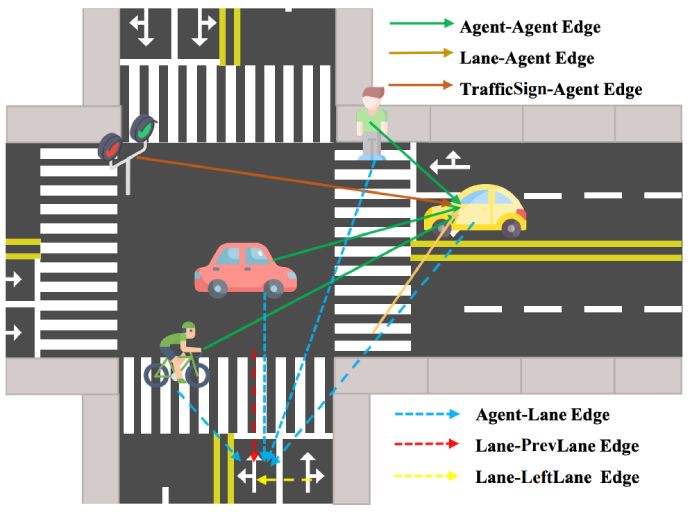
Yu Liu,
IEEE-TPAMI 2023
HDGT formulates the driving scene as a heterogeneous graph with different types of nodes and edges.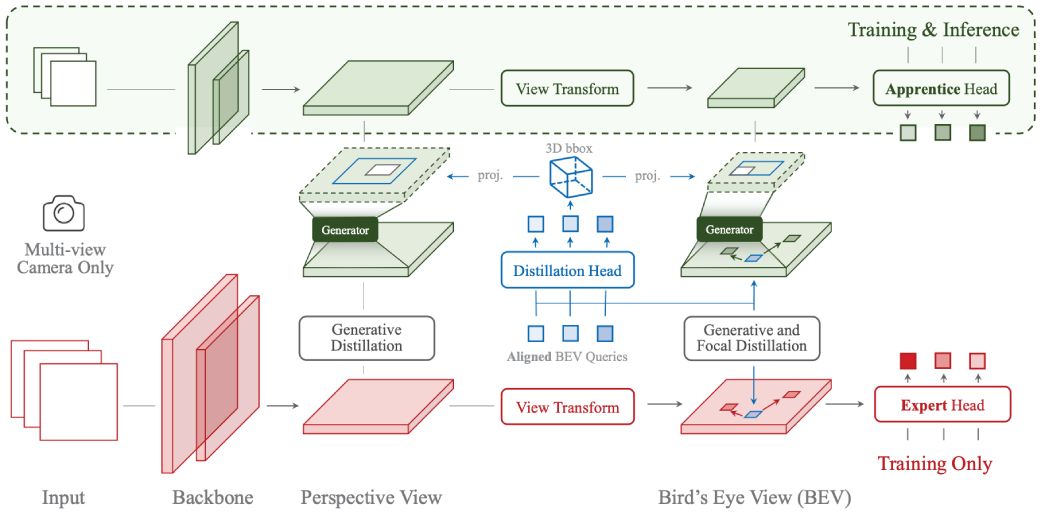
Jia Zeng,
Hanming Deng,
Lewei Lu,
CVPR 2023
We investigate on how to distill the knowledge from an imperfect expert. We propose FD3D, a Focal Distiller for 3D object detection.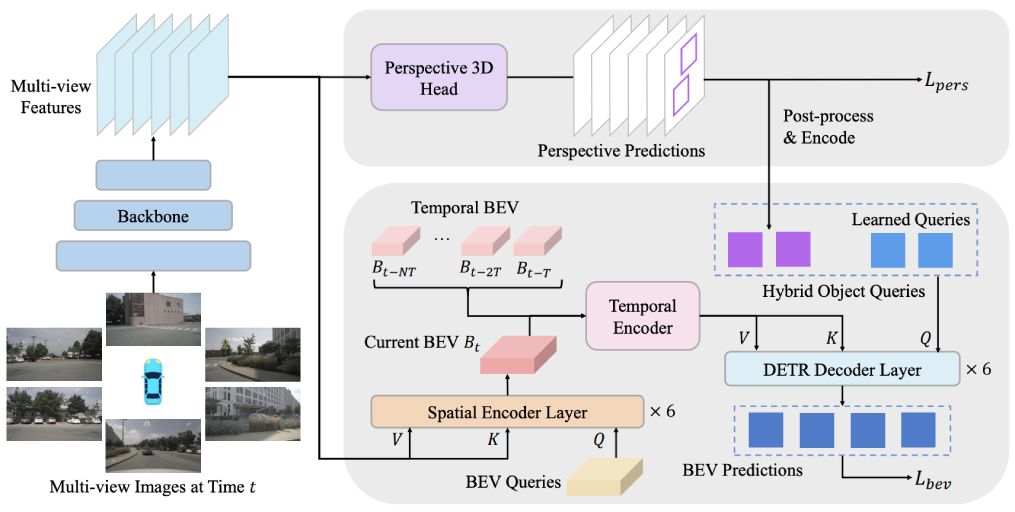
Chenyu Yang,
Yuntao Chen,
Hao Tian,
Chenxin Tao,
Xizhou Zhu,
Zhaoxiang Zhang,
Gao Huang,
Lewei Lu,
Jie Zhou,
Jifeng Dai
CVPR 2023 Highlight
A novel bird's-eye-view (BEV) detector with perspective supervision, which converges faster and better suits modern image backbones.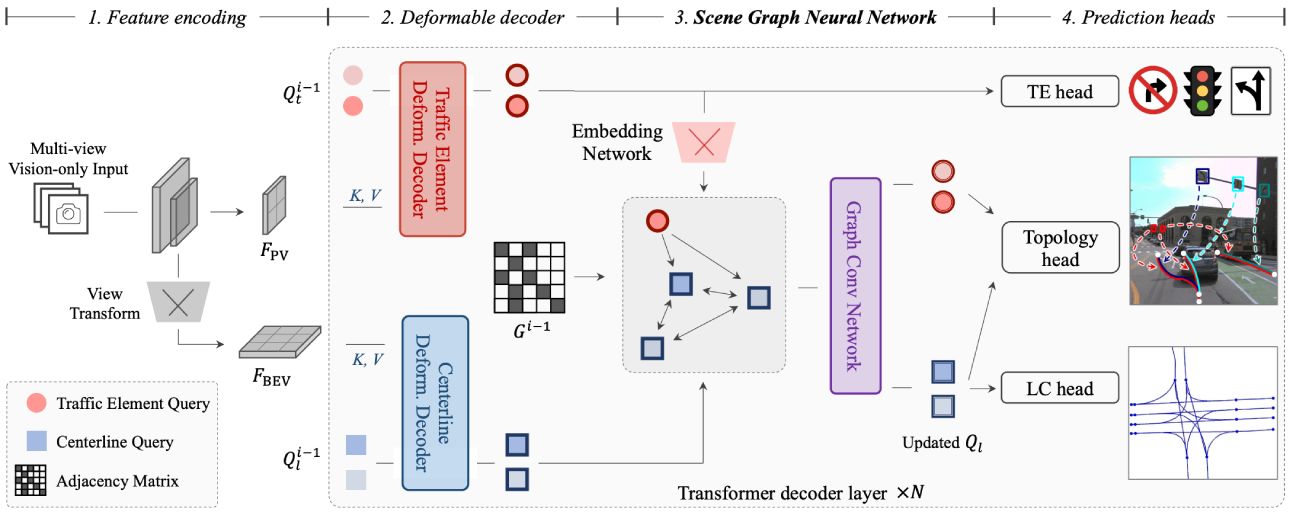
Yang Li,
Jiazhi Yang,
Shengyin Jiang,
Yuting Wang,
Hang Xu,
Chunjing Xu,
Preprint 2023
A new baseline for scene topology reasoning, which unifies heterogeneous feature learning and enhances feature interactions via the graph neural network architecture and the knowledge graph design.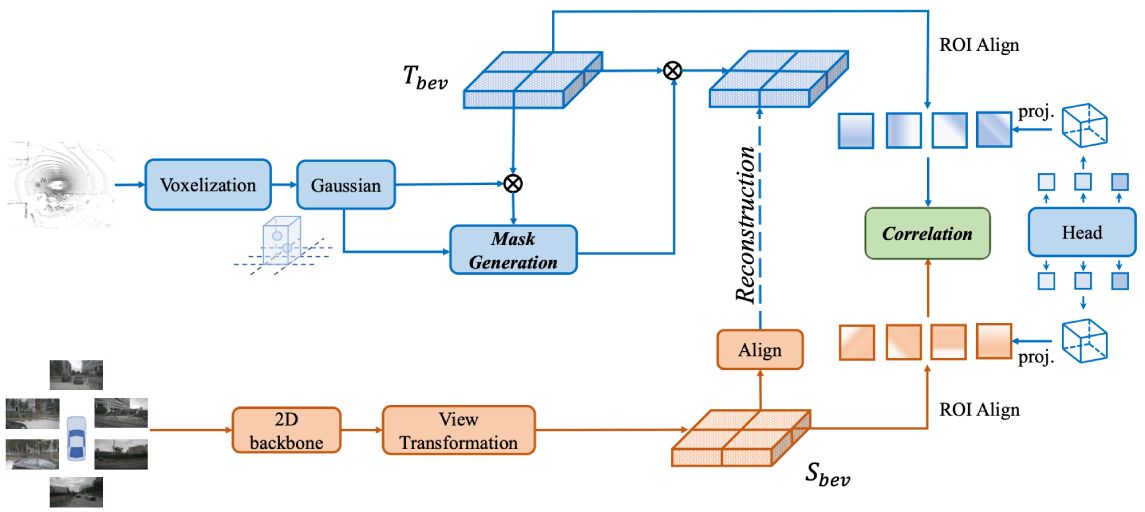
Jia Zeng,
Shengchuan Zhang,
Liujuan Cao,
Rongrong Ji,
Preprint 2023
We propose GAPretrain, a plug-and-play framework that boosts 3D detection by pretraining with spatial-structural cues and BEV representation.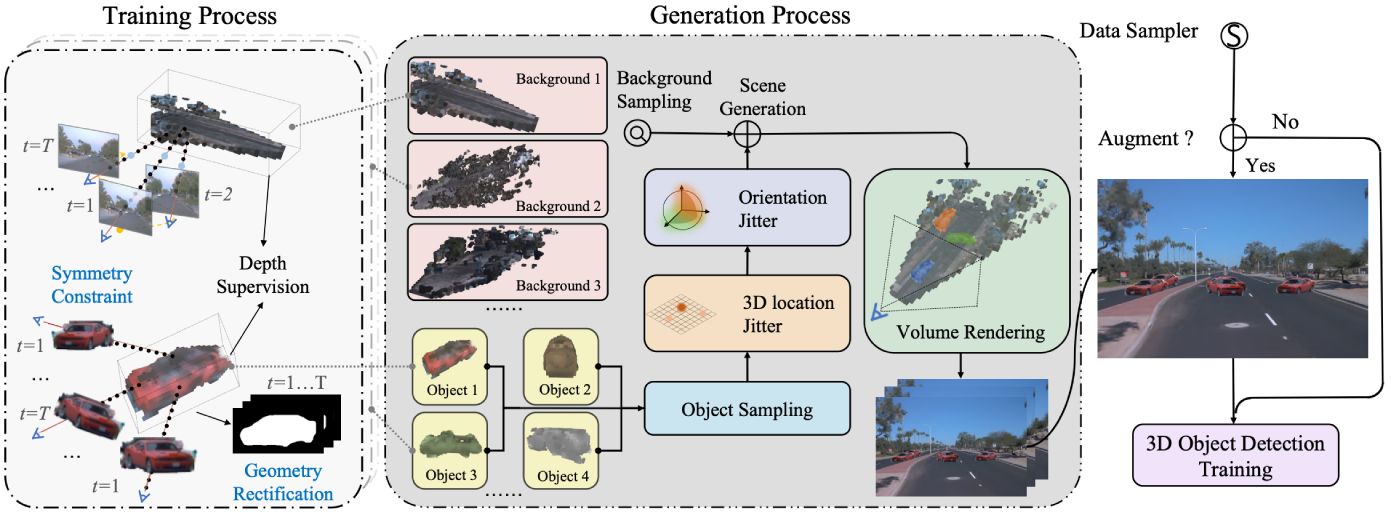
Wenwen Tong,
Jiangwei Xie,
Yang Li,
Hanming Deng,
Bo Dai,
Lewei Lu,
Hao Zhao,
PRCV 2024
We propose a 3D data augmentation approach termed Drive-3DAug to augment the driving scenes on camera in the 3D space.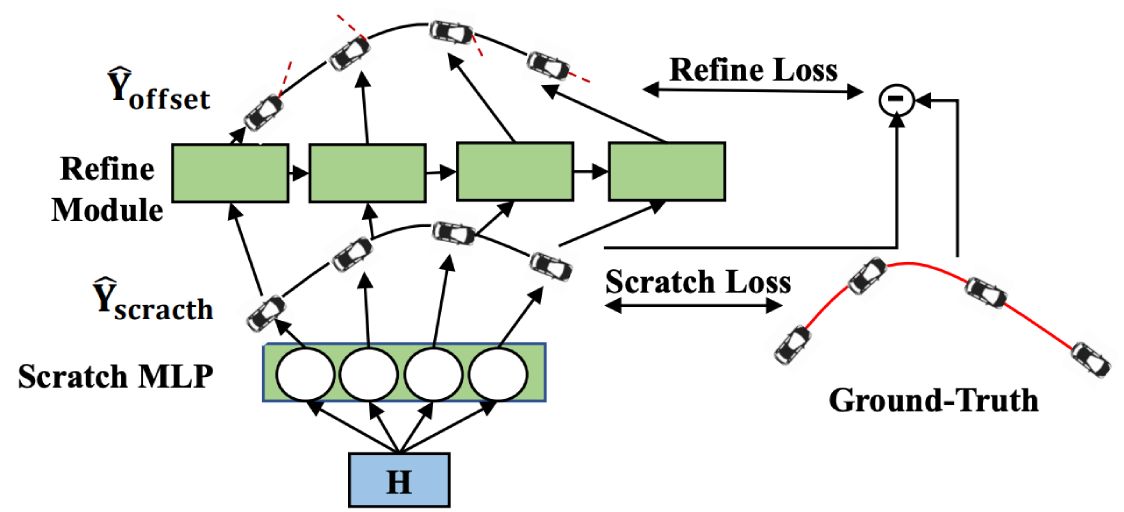
Jia Zeng,
CoRL 2022
We find taking scratch trajectories generated by MLP as input, a refinement module based on structures with temporal prior, could boost the accuracy.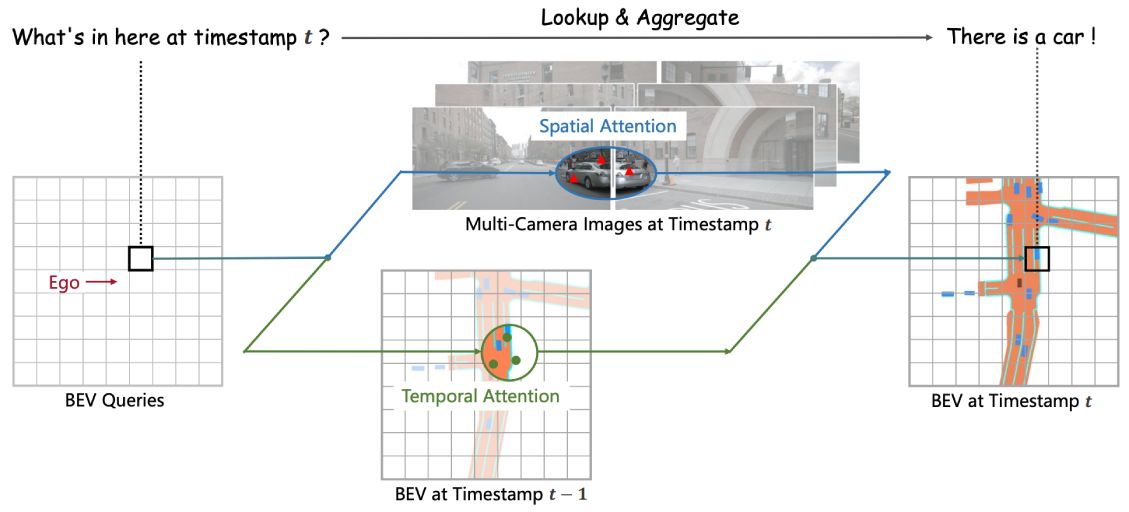
BEVFormer: Learning Bird's-Eye-View Representation From LiDAR-Camera via Spatiotemporal Transformers
Enze Xie,
Tong Lu,
Jifeng Dai
IEEE-TPAMI 2025
A paradigm for autonomous driving that applies both Transformer and Temporal structure to generate BEV features.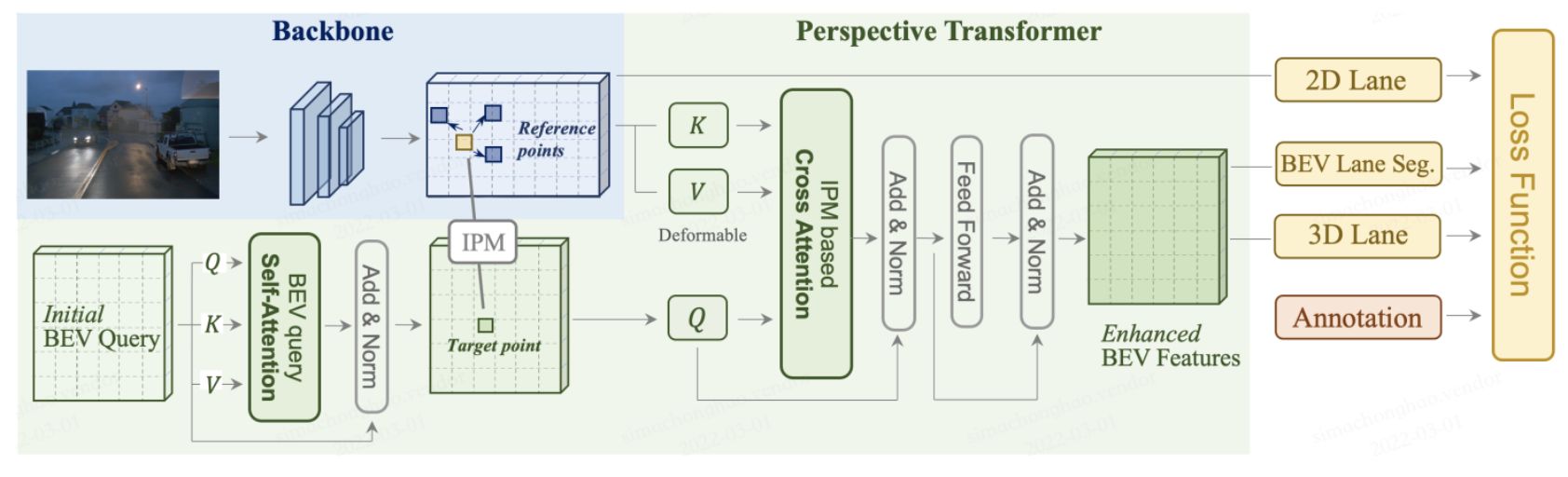
Yang Li,
Zehan Zheng,
Conghui He,
Jianping Shi,
ECCV 2022 Oral
PersFormer adopts a unified 2D/3D anchor design and an auxiliary task to detect 2D/3D lanes; we release one of the first large-scale real-world 3D lane datasets, OpenLane.
Haoran Jiang,
Qingsong Yao,
Yanan Sun,
Renrui Zhang,
Hao Zhao,
Hongzi Zhu,
ICCV 2025
DetAny3D is a promptable 3D detection foundation model that leverages 2D foundation knowledge to enable zero-shot 3D object detection from monocular images across novel categories and camera settings.
Yanan Sun,
Fei Xia,
IEEE-TPAMI 2026

Yifei Zhang,
Hao Zhao,
Siheng Chen
CVPR 2024
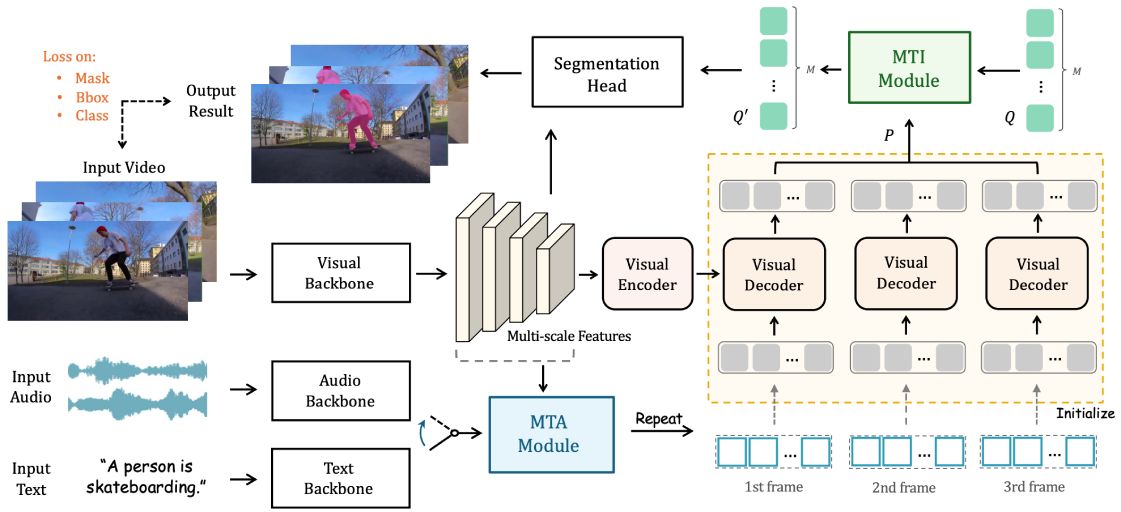
Shilin Yan,
Renrui Zhang,
Ziyu Guo,
Wenchao Chen,
Wei Zhang,
Zhongjiang He,
Peng Gao
AAAI 2024
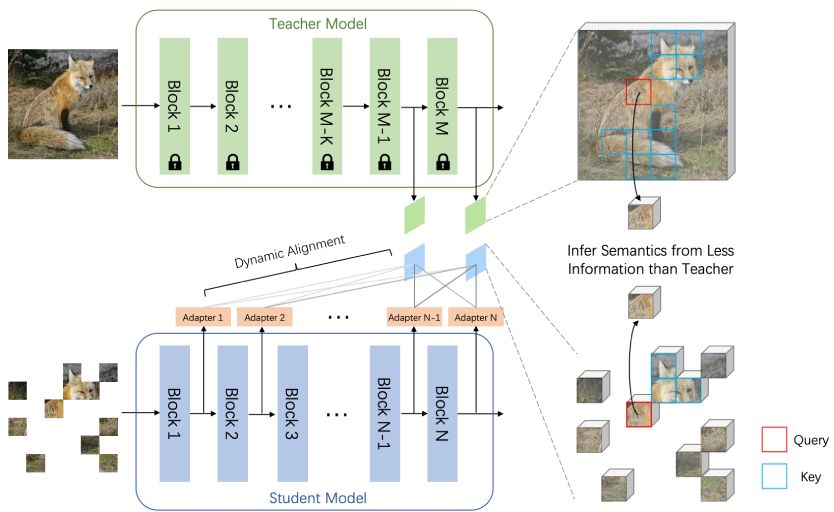
Peng Gao,
Hao Sun,
Houqiang Li,
Jiebo Luo
CVPR 2023
An efficient MIM paradigm MaskAlign and a Dynamic Alignment module to apply learnable alignment to tackle the problem of input inconsistency.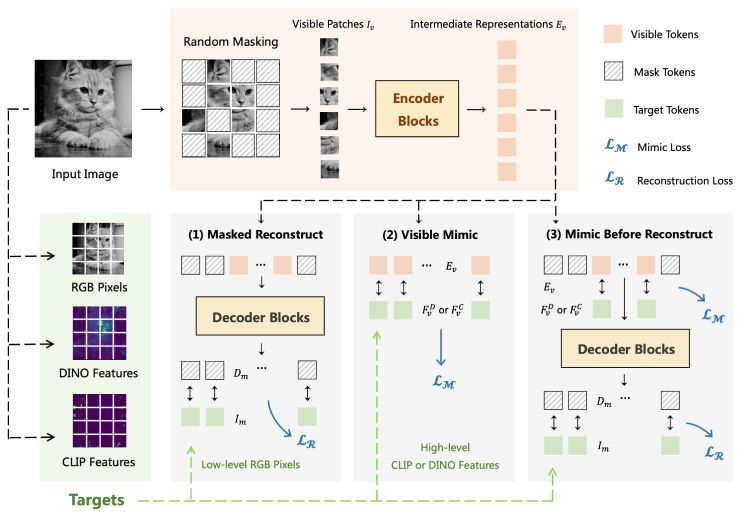
Peng Gao,
Renrui Zhang,
Rongyao Fang,
Ziyi Lin,
Hongsheng Li,
Qiao Yu
IJCV 2023
Introducing high-level and low-level representations to MAE without interference during pre-training.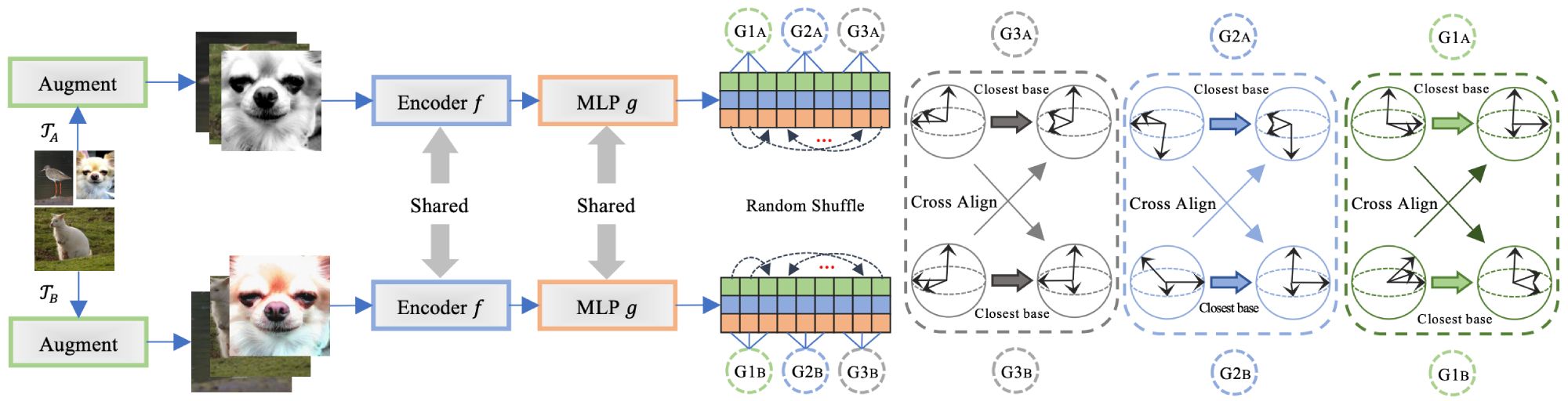
Shaofeng Zhang,
Lyn Qiu,
Feng Zhu,
Hengrui Zhang,
Rui Zhao,
Xiaokang Yang
CVPR 2022