Embodied AI
bridges intelligence and the physical world through real-world perception, action, and learning. Focusing on humanoids, manipulation, and dexterous hands, we aim to uncover robot scaling laws, develop general world models, and unlock reinforcement learning for general-purpose embodied agents.For a complete list of publications, please see here.- Native Memory Compression for Long-Horizon Robotic ManipulationNativeMEM gives pretrained Vision-Language-Action policies long-term, real-time visual memory by compressing each historical frame-view observation into a single native memory token.
- RoboNaldo: Accurate, Stable and Powerful Humanoid Soccer Shooting via Motion-Guided Curriculum Reinforcement LearningWorld's first sub-meter accurate humanoid soccer shooting policy in general cases — single human reference, learn to track, then deviate and adapt.

- MM-Hand: A 21-DOF Multi-modal Modular Dexterous Robotic Hand with Remote ActuationAn open-source, high-DoF, lightweight, multimodal, and modular dexterous hand.

- TAMEn: Tactile-Aware Manipulation Engine for Closed-Loop Data Collection in Contact-Rich TasksTAMEn builds upon the UMI paradigm with key enhancements in multimodality, precision-portability synergy, replayability, and data flywheel.
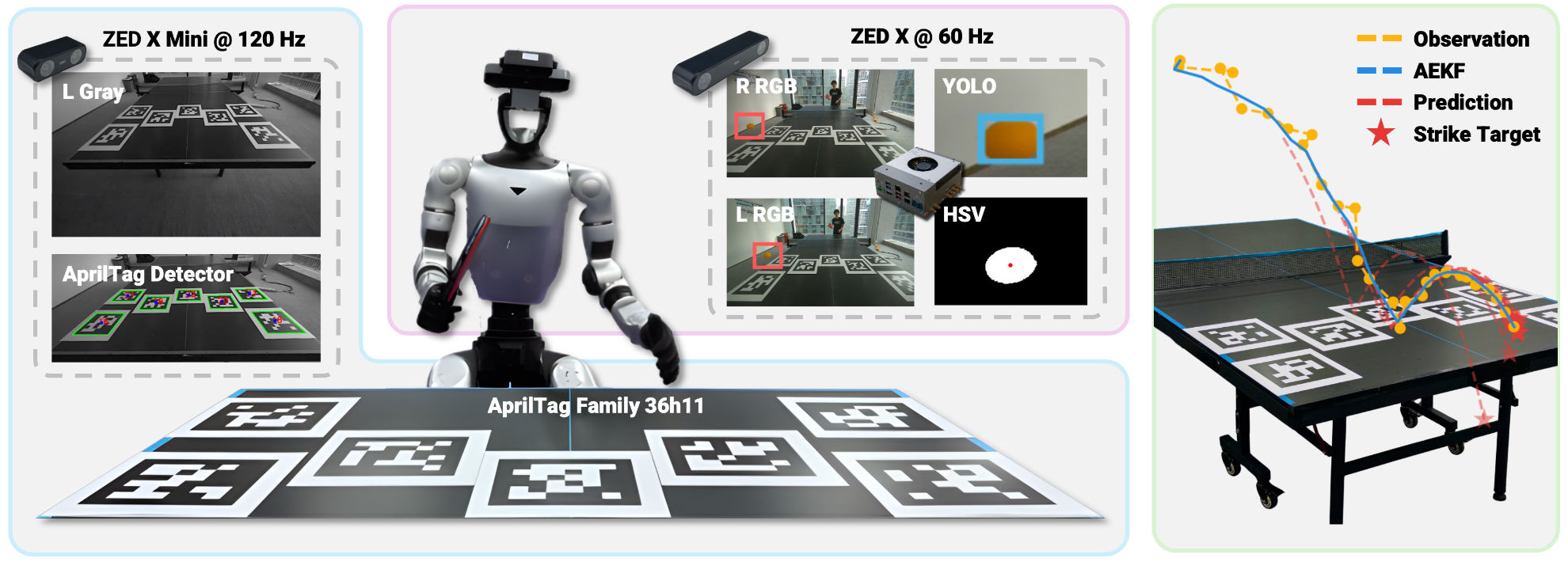
- SMASH: Mastering Scalable Whole-Body Skills for Humanoid Ping-Pong with Egocentric VisionThe future of robotics begins where the lab ends: in open-world interaction.
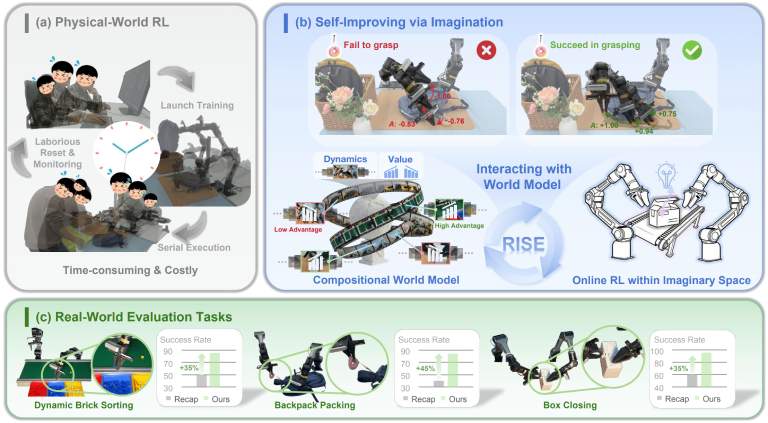
- RISE: Self-Improving Robot Policy with Compositional World ModelThe first study on leveraging world models as an effective learning environment for challenging real-world manipulation, bootstrapping performance on tasks requiring high dynamics, dexterity, and precision.
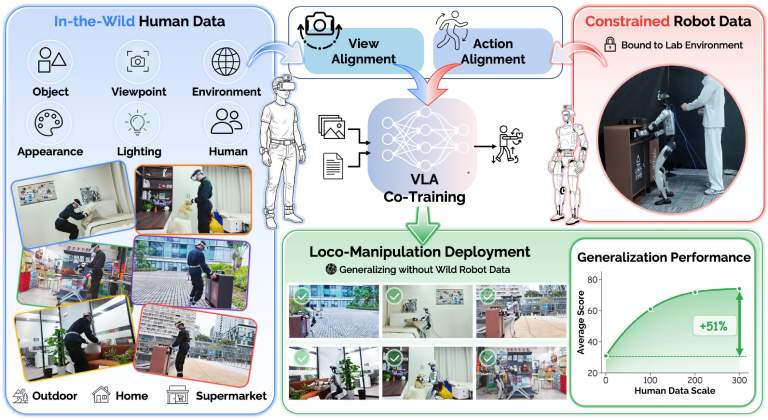
- EgoHumanoid: Unlocking In-the-Wild Loco-Manipulation with Robot-Free Egocentric DemonstrationThe first endorsement of human-to-humanoid transfer for whole-body locomanipulation.
- Sparse Video Generation Propels Real-World Beyond-the-View Vision-Language Navigationwe investigate beyond-the-view navigation task in the real world by introducing video generation model in this field for the first time, pioneering such capability in challenging night scenarios.
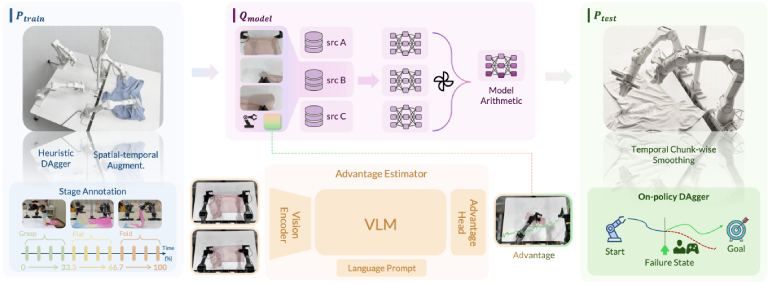
- χ0: Resource-Aware Robust Manipulation via Taming Distributional Inconsistencies"Veni, Vidi, Vici" - I came, I saw, I conquered. We aim to conquer the "Mount Everest" of robotics: 100% reliability in real-world garment manipulation.
- WholeBodyVLA: Towards Unified Latent VLA for Whole-body Loco-manipulation ControlA unified VLA framework enabling large-space humanoid loco-manipulation via unified latent learning and loco-manipulation-oriented RL.
- Agility Meets Stability: Versatile Humanoid Control with Heterogeneous DataA unified whole-body control policy for humanoid robots that enables zero-shot execution of diverse motions, including Ip Man'squat, dancing, running and real-time teleoperation.
- GO-1-Pro: Is Diversity All You Need for Scalable Robotic Manipulation?The first comprehensive analysis of data diversity principles revealing optimal scaling strategies for large-scale robotic manipulation training.
- FreeTacMan: Robot-free Visuo-Tactile Data Collection System for Contact-rich ManipulationA human-centric and robot-free visuo-tactile data collection system for high-quality and efficient robot manipulation.
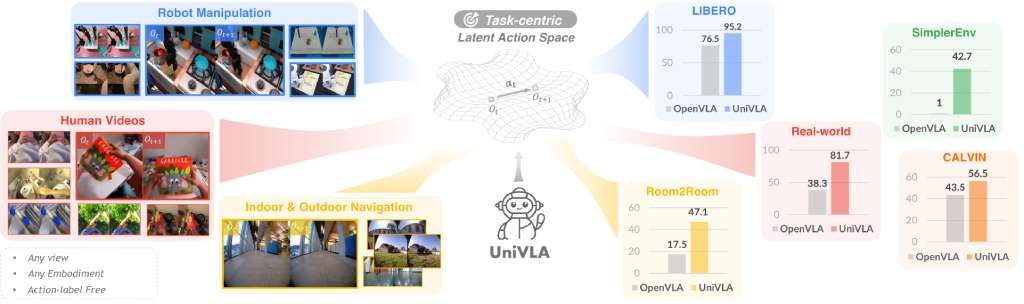
- UniVLA: Learning to Act Anywhere with Task-centric Latent ActionsA unified vision-language-action framework that enables policy learning across different environments.
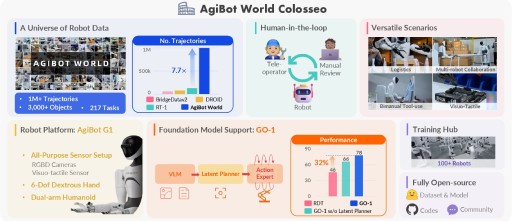
- AgiBot World Colosseo: A Large-scale Manipulation Platform for Scalable and Intelligent Embodied SystemsA novel generalist policy that leverages latent action representations to maximize data utilization, demonstrating predictable performance scaling with increased data volume.
- Towards Synergistic, Generalized, and Efficient Dual-System for Robotic ManipulationOur objective is to develop a synergistic dual-system framework which supplements the generalizability of large-scale pre-trained generalist with the efficient and task-specific adaptation of specialist.
- Closed-Loop Visuomotor Control with Generative Expectation for Robotic ManipulationCLOVER employs a text-conditioned video diffusion model for generating visual plans as reference inputs, then these sub-goals guide the feedback-driven policy to generate actions with an error measurement strategy.
- Learning Manipulation by Predicting InteractionWe propose a general pre-training pipeline that learns Manipulation by Predicting the Interaction (MPI).
